We're introducing Conformer-1, a state-of-the-art speech recognition model trained on 650K hours of audio data that achieves near human-level performance and robustness across a variety of data.
Our results demonstrate that Conformer-1 is more robust on real-world data than popular ASR models, making up to 43% fewer errors on noisy dataI, and achieving state-of-the-art results on a wide variety of academic and real-world datasets compared to other ASR models.
Hit play to view transcript
We'll get in a minute, but he is still crying tears of joy. LeBron.
I'm sorry, Doris. No. No worries, Kyrie. LeBron, as soon as that
buzzer sounded, your emotions let loose. Can you describe what
you're feeling right now? I set out a goal two years when I came
back to bring a championship to the city. I gave everything that I
had. I put my heart, my blood, my sweat, my tears to this game.
Hit play to view transcript
Good morning. Hi. It's Elmo. Time to wake up, sleepy head. Come on,
rise and shine. Elmo loves the morning.
In the morning, there's so many things happening on Sesame Street.
Elmo's looking out his window right now, and he sees telly on his
pogo stick. Hi, Kelly. And there's Alan and Gabby opening up Mr.
Hooper's store.
Hi, Alan. Hi, Gabby. Hi. Oh, and there's Gordon and Bob and Maria.
Oh, and there's Louise too. Hi everybody. Oh, and here comes Zoe
and Grover.
Hit play to view transcript
You must think that I'm stupid you must think that I'm a fool? You
must think that I'm new to this? But I have seen this song before.
I'm never going to let you close to me even though you mean the most
to me because every time I open up, it hurts. So I'm never going to
get too close to you, even when I mean almost to you, in case you go
and leave me in the dirt.
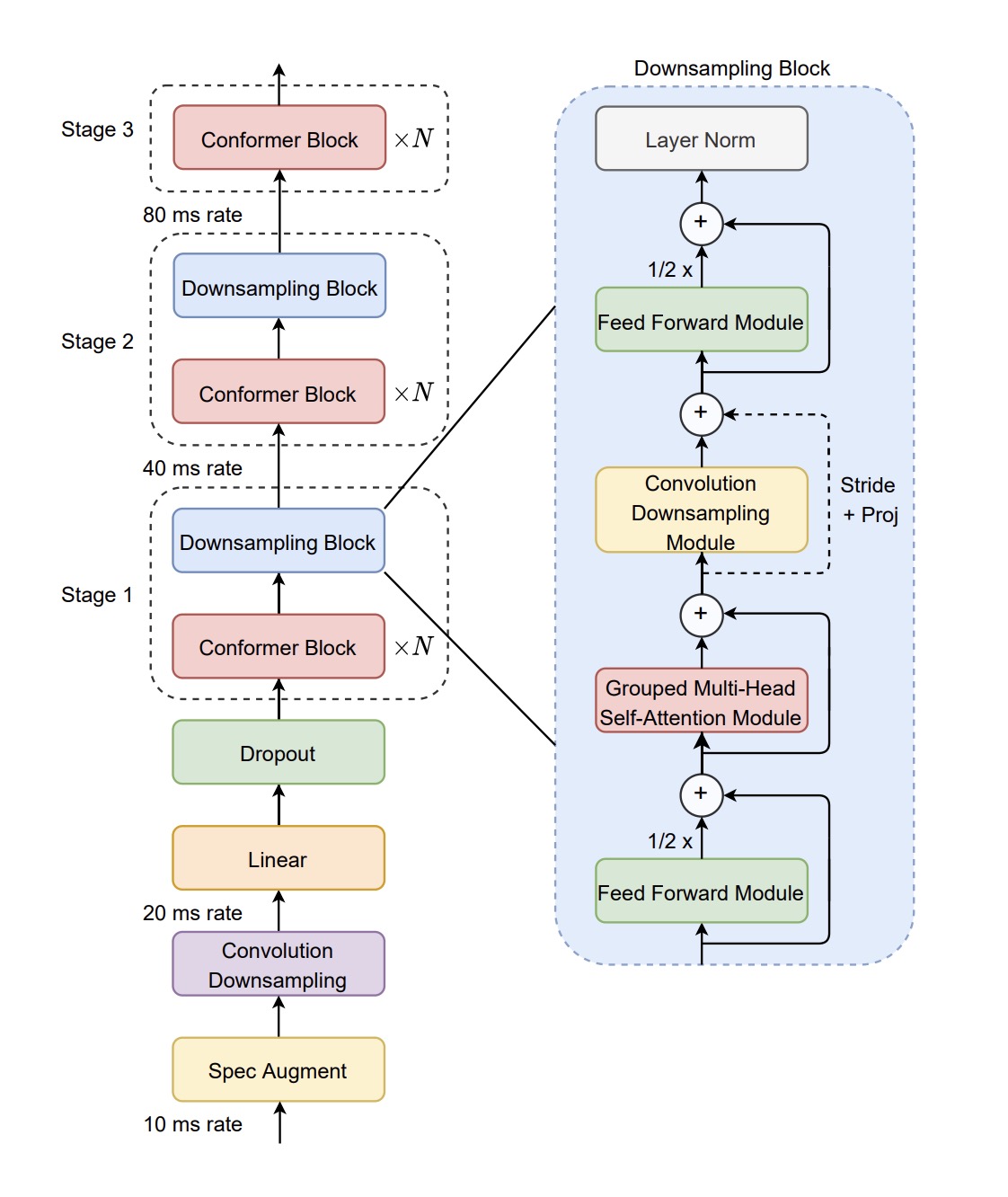
Conformer-1’s architecture
A model that leverages Transformer and Convolutional layers for speech recognition.
The Conformer [1] is a neural net for speech recognition that was published by Google Brain in 2020. The Conformer builds upon the now-ubiquitous Transformer architecture [2], which is famous for its parallelizability and heavy use of the attention mechanism. By integrating convolutional layers into the Transformer architecture, the Conformer can capture both local and global dependencies while being a relatively size-efficient neural net architecture.
While the Conformer architecture has shown state-of-the-art performance in speech recognition, its main downside lies in its computational and memory efficiency. The core usage of the attention mechanism in Conformer, essential to capture and retain long-term information in an input sequence, is in fact well-known to be a computational bottleneck. This makes the original Conformer architecture slow to operate at both training and inference tasks compared to other existing architectures, and poses an engineering challenge for its deployment within large scale ASR systems.
With Conformer-1, our goal was to train a production-ready speech recognition model that can be deployed at extremely large scale and that maximally leverages the original Conformer architecture’s outstanding modeling capabilities.
To do this, we introduce a number of modifications to the original Conformer architecture. For example, our Conformer-1 is built on top of the Efficient Conformer [3], a modification of the original Conformer architecture that introduces the following technical modifications:
Progressive Downsampling – A progressive reduction scheme for the length of the encoded sequence, inspired by ContextNet [4].
Grouped Attention – A modified version of the attention mechanism that makes it agnostic to sequence-length.
These changes yield speedups of 29% at inference time and 36% at training time with respect to the original, unmodified Conformer architecture, while at the same time achieving better or similar word-error-rate accuracy. Faster training times enabled our team to run more experiments in order to find the best set of hyperparameters.
In an effort to further improve our model’s accuracy on noisy audio, we implemented a modified version of Sparse Attention [5], a pruning method for achieving sparsity of the model’s weights in order to achieve regularization. This allows for better performance on audio with background noise, since it reduces the effect of the noise at particular timesteps to influence the higher level features, by mitigating the noise contribution within the attention steps.
In the original implementation of Sparse Attention, the average attention score is computed for a particular timestep, then the dot-product contribution from any timestep with lower attention score is filtered out. This effectively enforces the feature to only attend to the most salient global timesteps, achieving a regularization effect. With Conformer-1, we made this method more generalizable by replacing the average with a moving median, a quantile threshold used as the value for filtering. This prevents very big attention vectors in certain timesteps from significantly raising the filtering threshold, which can cause excessive pruning.
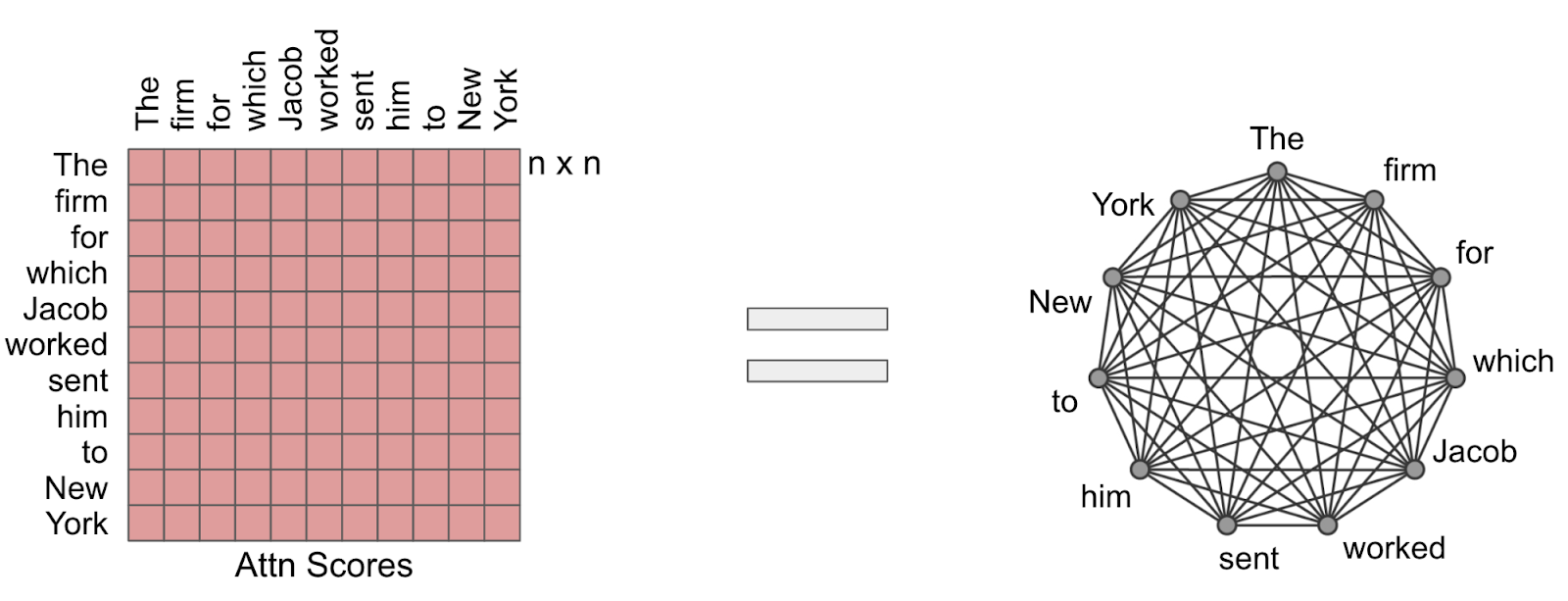
Fig. 2 – The Attention mechanism can be visualized as a fully-connected graph (i.e. each node is connected to every other node). The core idea behind Sparse Attention is to transform this into a sparse graph, while retaining similar attention scores as the original one. Image: Google Research Blog.
Scaling up to 650K hours
Recent research from DeepMind’s Chinchilla paper [6] has found that current Large Language Models (LLMs) are significantly undertrained. Over the past few years, there’s been an effort within the research community to scale the number of parameters of LLMs to unlock new capabilities, but Chinchilla finds that model size and volume of data should be scaled proportionally when training LLMs.
By scaling the amount of training data in this fashion, the authors of the Chinchilla paper were able to train a model, Chinchilla, that outperforms a number of models, including GPT-3 [7], on a wide range of tasks while only being a fraction of the size in terms of parameters.
When training our Conformer-1, we put these insights into practice and adapted these data scaling laws to the ASR domain. We determined that for a 300 million parameter Language model, we'd need roughly 6 billion tokens of text, which corresponds to about 625K hours of speech [II]. Given this, our team curated a dataset of 650K hours of English audio - consisting of proprietary internal datasets and various sources from the internet. This resulted in a 60TB dataset which was used to train our Conformer-1 model.
Results and Performance
In order to evaluate the accuracy and robustness of Conformer-1, we sourced 60+ hours of human labeled audio data covering popular speech domains such as call centers, podcasts, broadcasts, and webinars. We then calculated the Word Error Rate (WER) of Conformer-1 against these datasets, and compared the results against a number of other models.
Our results demonstrate that Conformer-1 is more robust on real world data than popular commercially available ASR models, as well as open-source models such as Whisper [III], making 43% fewer errors on noisy data on average.
Fig. 3 – The above figure illustrates the average WER for our Conformer-1 model (blue) and the other popular models across our 5 internal benchmarks. The figure above is known as a boxplot and is intended to provide insight into how spread out the values from each dataset are. The number in the middle of each bar corresponds to the median WER, and the size of the box itself represents the middle 50% of the data points. Short boxes indicate most of the data is centered around the median, while taller boxes mean the data is more spread out. The notches on the error bar show the minimum and maximum values for that dataset.
We hypothesize that Conformer-1’s strong performance relative to other models can be attributed to training on an augmented dataset which incorporates large amounts of noisy pseudo labeled speech data in addition to human labeled speech. This combination makes Conformer-1 highly robust to out of distribution samples.
To ground our results against popular open source speech recognition benchmarks, we also performed the same WER analysis against a number of academic datasets. In the figure below, we show that Conformer-1 generalizes well and maintains its high accuracy across the board in terms of WER.
Fig. 4 – To avoid over penalizing shorter audios a weighted average proportional to transcript length was taken across each dataset. In addition, for TedLium3 we used raw audio and did not replicate the slicing performed by OpenAI in Whisper. This led to higher WER across all providers for that dataset.
Before calculating any metrics for both inhouse benchmarks and public benchmarks, each model’s outputs were fed through Whisper’s open source text normalizer. This avoids unfairly penalizing trivial differences in formatting across models, and obtains an objective metric that has a strong correlation with human preferences. For more insight into how this is achieved please reference appendix C in the Whisper paper [8].
Robustness to noise
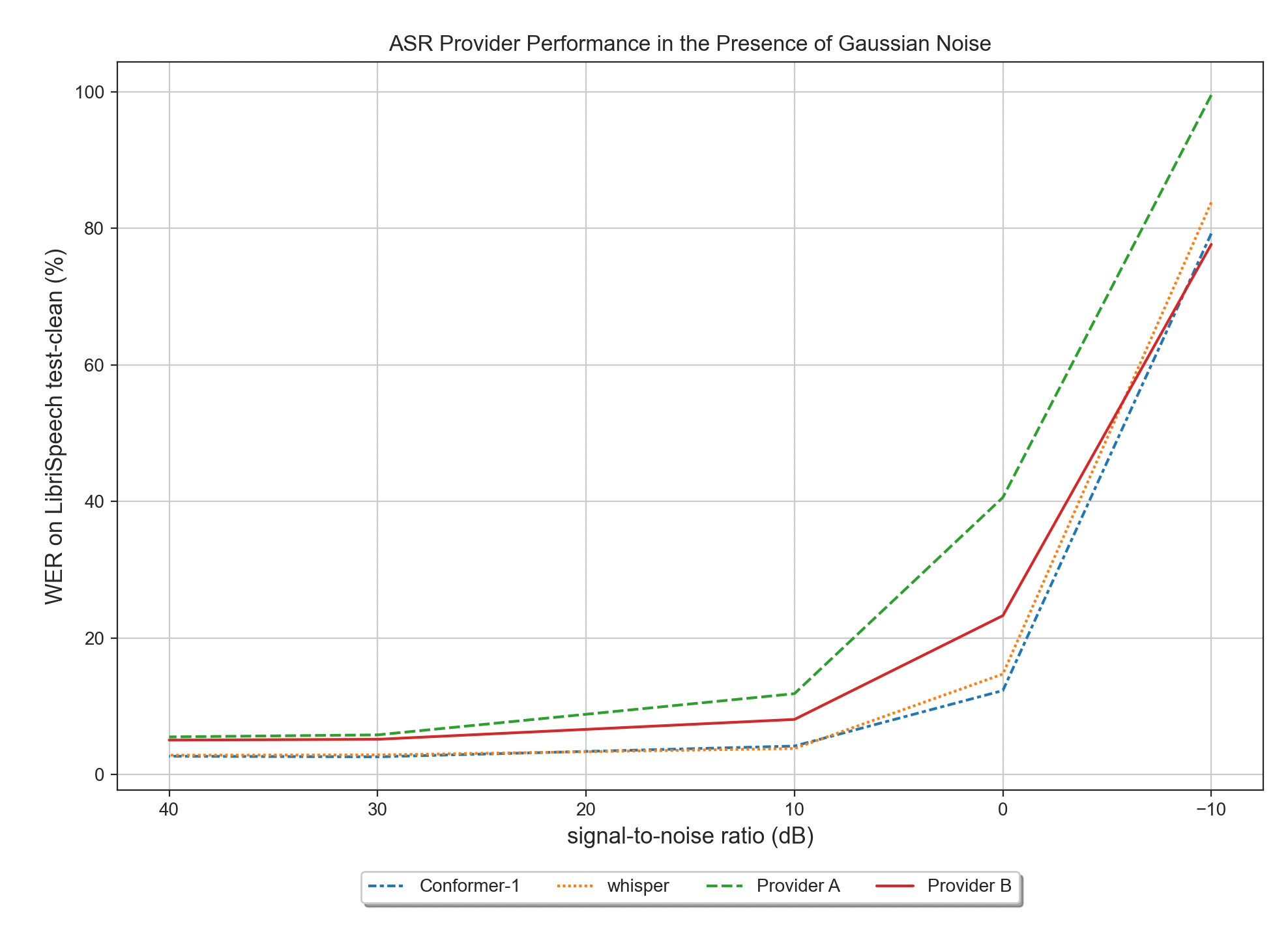
Conformer-1 shows extremely high accuracy and robustness to noise. This is reinforced in part by Conformer-1’s performance on LibriSpeech test-other [IV], however, even this dataset does not capture the level of noise found in real-world audio. To test how robust our model is to noise, we used LibriSpeech test-clean and performed an ablation study over different signal-to-noise ratios by adding Gaussian Noise to the audio data before feeding it to the models. The amount of noise added is increasing from left to right in the plot below and we see that Conformer-1’s WER is the slowest to rise.
In conclusion, our new Conformer-1 model achieves state-of-the-art speech recognition performance and robustness to real world audio data across a wide variety of domains.
Now available for streaming applications
Update: April 2023 In addition to the asynchronous model, Conformer-1 is now available for use in real-time transcription applications. The real-time Conformer-1 model shows a 24.3% relative accuracy improvement over its predecessor across the same diverse set of business-relevant datasets. If you are already using our API for real-time transcription, no changes are necessary to your existing code to obtain the benefits of Conformer-1.
Accessible today through our API
Conformer-1 is accessible through our API today.
The easiest way to try Conformer-1 is through our Playground, where you can upload a file or enter a YouTube link to see a transcription in just a few clicks.
You can also try out our API directly for free. Simply sign up to get a free API token, and head over to our Docs or welcome Colab to be up and running in just a few minutes.
If you’re thinking about integrating Conformer-1 into your product, you can reach out to our Sales team with any questions you might have.
Interested in integrating Conformer-1 into your product?
[I] The quoted figure is taken from our noise ablation study (see Results section). At a signal to noise ratio of 0 we achieve a WER 43% lower then the average across providers and 17% lower then the second best provider.
[II] To convert hours of audio to number of tokens, we used the following heuristics: 1 hour of audio = 7,200 words and 1 word = 1.33 tokens
[III] We used the public API provided by OpenAI to get our Whisper transcripts. According to the documentation, their API uses the Whisper large-v2 model. This API requires the developer to split their own audio files into smaller chunks when the audio file exceeds 25 MBs. Given this, we used our Voice Activity detection model to avoid splitting audio files mid sentence before sending them to the Whisper API. We believe this provides an accurate baseline on how a sophisticated developer would use this API for transcription.
[IV] LibriSpeech test-other corresponds to the audios with hard accents, poor quality, and generally higher degree of difficulty in that dataset.