

Intro
OpenAI’s GPT-3 is an impressive deep learning model, but at 175B parameters, it is quite the resource hog! Estimates vary, but a model of this size would take hundreds of years to train on a single GPU.
Fortunately, OpenAI had the benefit of a high-bandwidth cluster of NVIDIA V100 GPU’s provided by Microsoft, which allowed them to train GPT-3 in a matter of weeks instead of years. Just how big was this cluster? According to this paper, it would take around 34 days to train GPT-3 on 1,024x NVIDIA A100 GPUs.
That is a mind boggling amount of GPUs. With each A100 GPU priced at $9,900, we’re talking almost $10,000,000 to setup a cluster that large. And we’re not even factoring in the cost of electricity, or the server rack you actually have to install the GPUs into, or the human costs of maintaining this type of hardware, among other costs.
Nowadays, you can rent A100 GPUs from public cloud providers like Google Cloud, but at $2.933908 per hour, that still adds up to $2,451,526.58 to run 1,024 A100 GPUs for 34 days. And keep in mind, that price is for a single training run!
I can keep going, but the point is that training large models is expensive and slow. Here at AssemblyAI, we aren’t training models in the 175B parameter range (thankfully), but our speech recognition models are extremely large Transformers that are fast approaching the 1B parameter size. As a startup, speed and cost are two things we have to constantly optimize for.
Startups are all about iterating fast. Most companies can get feedback from customers and ship a new feature over a weekend. But when you’re a deep learning company, and your models take weeks to train, your iteration speed as a startup is significantly hindered.
The main way out of this problem is to train your models on more GPUs, but that comes at a high cost usually not affordable to startup companies. Over the past few years, we’ve learned a few lessons about training large models, and wanted to share them with the community.
Our Model Sizes & Training Times
At AssemblyAI, we build large, accurate Automatic Speech Recognition (ASR) models that we expose via a simple Speech-to-Text API. Developers use our API to build applications that transcribe phone calls, zoom meetings, podcasts, videos, and other types of media content.
See Also: What is ASR?Our best performing ASR models are large Transformers that take around 3 weeks to train on 48x V100 GPUs.

Why do our models take so long to train, and require so many GPUs? There are three main contributing factors:
1. The input features to an ASR model are high dimensional, long sequences
We, more or less, calculate the spectrogram of an audio file every 10 milliseconds, and use these values as input features to our neural network. The shape/dimensions of the spectrogram varies depending on the sample rate of the audio data, but if you have a sample rate of 8000 Hz, the number of features in the spectrogram will be 81. For a 16 second audio sample, the shape would be [1600, 81] - which is quite a big feature input!
Below is an example of what a spectrogram looks like as a matrix:
[[[-5.7940, -5.7940, -4.1437, ..., 0.0000, 0.0000, 0.0000],
[-5.9598, -5.9598, -4.2630, ..., 0.0000, 0.0000, 0.0000],
[-5.9575, -5.9575, -4.2736, ..., 0.0000, 0.0000, 0.0000],
...,
[-4.6040, -4.6040, -3.5919, ..., 0.0000, 0.0000, 0.0000],
[-4.4804, -4.4804, -3.5587, ..., 0.0000, 0.0000, 0.0000],
[-4.4797, -4.4797, -3.6041, ..., 0.0000, 0.0000, 0.0000]]],
[[[-5.7940, -5.7940, -5.7940, ..., 0.0000, 0.0000, 0.0000],
[-5.9598, -5.9598, -5.9598, ..., 0.0000, 0.0000, 0.0000],
[-5.9575, -5.9575, -5.9575, ..., 0.0000, 0.0000, 0.0000],
...,
[-4.6040, -4.6040, -4.6040, ..., 0.0000, 0.0000, 0.0000],
[-4.4804, -4.4804, -4.4804, ..., 0.0000, 0.0000, 0.0000],
[-4.4797, -4.4797, -4.4797, ..., 0.0000, 0.0000, 0.0000]]],
[[[-5.7940, -5.7940, -5.7940, ..., 0.0000, 0.0000, 0.0000],
[-5.9598, -5.9598, -5.9598, ..., 0.0000, 0.0000, 0.0000],
[-5.9575, -5.9575, -5.9575, ..., 0.0000, 0.0000, 0.0000],
...,
[-4.6040, -4.6040, -4.6040, ..., 0.0000, 0.0000, 0.0000],
[-4.4804, -4.4804, -4.4804, ..., 0.0000, 0.0000, 0.0000],
[-4.4797, -4.4797, -4.4797, ..., 0.0000, 0.0000, 0.0000]]]
2. Our models have a large number of parameters
When it comes to Transformer based neural networks, bigger is usually better. There are many papers that back up this claim, with GPT-3 being the most popular example. Both in the research community, and our own internal research, we find this trend to be true for ASR models as well.
Our best performing models are large Transformers that have nearly 500 million parameters. The more parameters, the more compute power required to update the gradients during back-propagation. Training a neural network basically boils down to doing a bunch of matrix operations. The more parameters in your model, the larger the matrices. Large matrices require more compute and GPU memory resources.
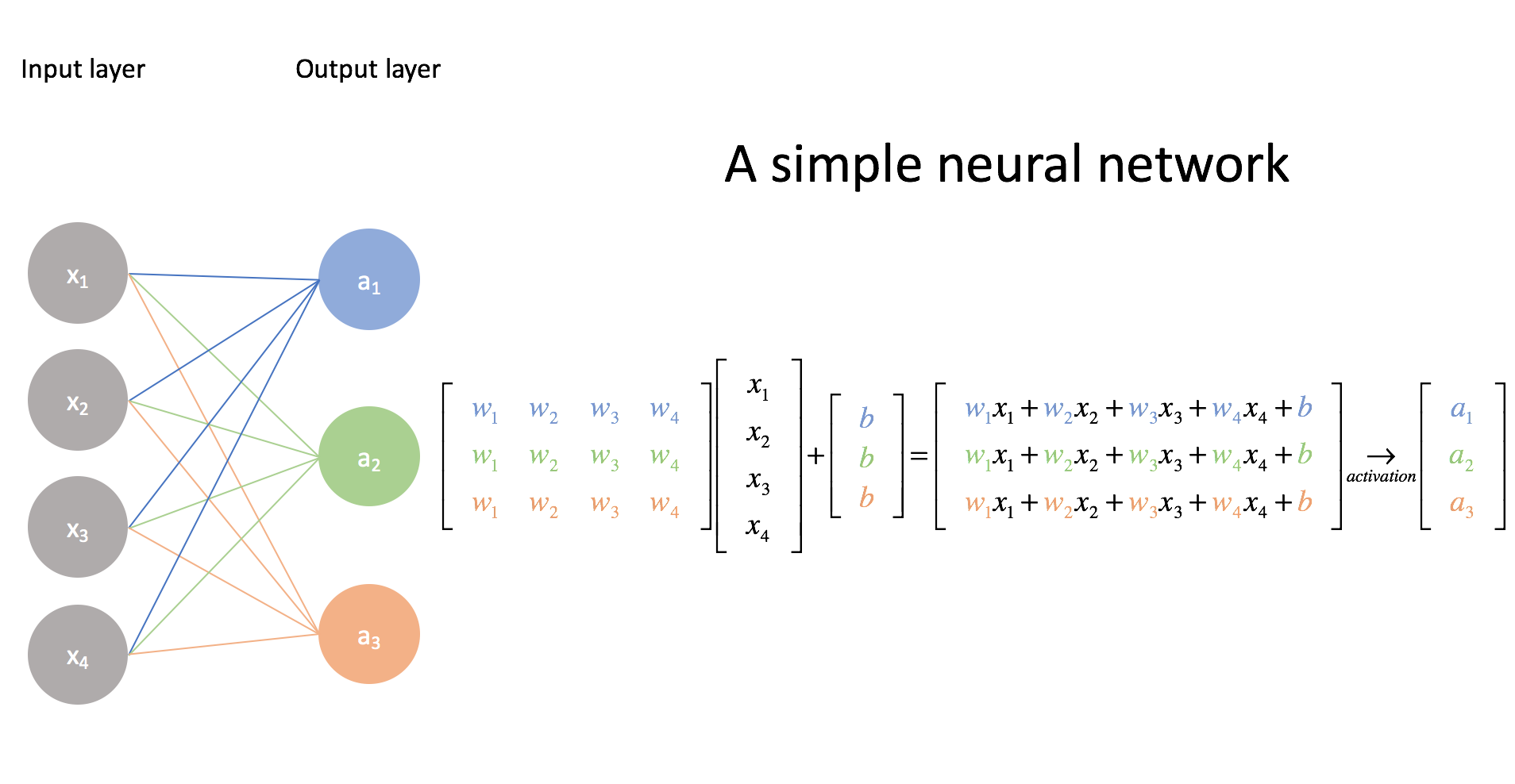
3. We train on large amounts of data
Large models have more modeling power - thanks to their increase in parameter size - and to make use of that modeling power, we train our models on almost 100,000 hours of labeled speech data. GPT-3, for example, was trained on 45TB of text data - which can also be thought of as around 1,099,511,626,800 words of text.
When training a neural network, you iterate over your dataset multiple times (with each iteration being referred to as an “epoch”). The larger your dataset, the longer each iteration, or “epoch”, takes. Even with early stopping, training a big model, on a large dataset, for 20-50 epochs can take a lot of time!
How to Improve Iteration Speed
Startups have a difficult task - achieve a lot of progress in a short amount of time. Those that achieve the most amount of progress, in the shortest amount of time, are often heralded as the “breakout” startups.
As a deep learning startup, this poses a difficult challenge. How do you iterate quickly when your models take 3-4 weeks to train?
Train on more GPUs
The easiest way to reduce training time is to train your models on more GPUs. More GPUs means more GPU memory available for your training run. For example, let’s say you can fit a mini-batch of size 8 on a single GPU. If you have 1,000 samples in your dataset to iterate through, that means 125 mini-batches (each of size 8) to iterate through. If each iteration takes 1 second, it would take 125 seconds to iterate over all 125 mini-batches.
If you have 4 GPUs, you can iterate over 4 mini-batches at a time in parallel, instead of 1 mini-batch. That means it would only take 32 iterations to go through all 125 of your mini-batches. Let’s say each iteration now takes 1.5 seconds with 4 GPUs, because of the extra communication overhead with 4 GPUs - still, you would be able to iterate through your entire dataset in 48 seconds (32 * 1.5). That is almost 3x faster than a single GPU!
One thing to be aware of, however, is that bigger batches don't always equate to faster training times. If your effective batch size gets too large, it can start to hurt the overall convergence of your model. Choosing the right batch size to train on is a hyperparameter you’ll have to experiment with, and there is ongoing research into different optimizers like LAMB and LARS that helps mitigate the issue of large batch size hurting convergence.
GPU performance doesn’t scale linearly
The more GPUs you train on, the more communication overhead there is. This is why training on 8 GPUs is not 8x faster, for example, than training on a single GPU. At AssemblyAI, we use Horovod to manage our distributed training runs across many GPUs. Horovod is a great library that helps you get a lot more efficiency as you add more GPUs to your training clusters.
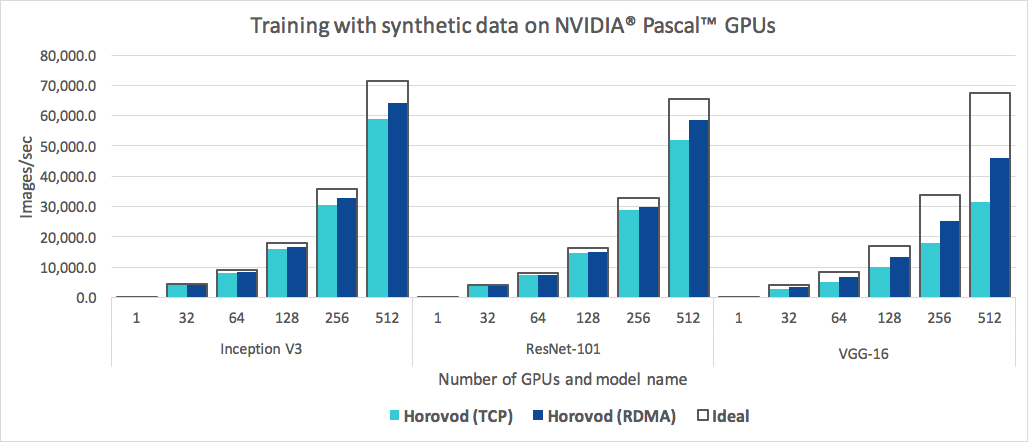
In our testing, we found Horovod to be a lot faster than Distributed TensorFlow and PyTorch DistributedDataParallel. This being said, PyTorch is under active development and improving quickly. In our testing, we found PyTorch DistributedDataParallel was comparable to Horovod on a single server - but Horovod performs better when scaling training runs to multiple servers (for eg, 4 servers each with 8 GPUs).
Train with lower precision
Most models are trained with FP32 by default (floating point value 32, aka single precision). Training with half-precision (FP16) or Mixed Precision, can also speed up your training times.
A FP16 tensor is 16-bits, or 2-bytes, where each bit is a 0 or 1, such as 01010101 10101010. A FP32 tensor is 32-bits, or 4-bytes, such as 11110000 00001111 11001100 00110011.
Less precision during training means fewer bytes, which means during training less GPU memory is required, less bandwidth is required, and the actual hardware-level operations on newer GPUs tend to run more quickly - all of which speed up training times.
Dropping to FP16 is relatively easy to do with PyTorch, for example x = x.half casts a FP32 tensor down to FP16. The thing to keep in mind, however, is that training with lower precision in practice is not always a walk in the park. Some operations or custom loss functions may not support lower precision, it may take a lot of hyperparameter tuning to get your model to converge with FP16, and the lower precision may also hurt your model's overall accuracy.
How to Reduce Training Costs
This is an easy one - don’t use public clouds like AWS or Google Cloud. This might seem like the easiest way to get started, but costs will very quickly add up, especially in comparison to the below options.
Buy your own hardware
If you are comfortable managing your own hardware (we don’t recommend this), buying consumer grade GPUs, like the NVIDIA TITAN X, is a relatively inexpensive option. Each TITAN X, for example, costs roughly $3,000, and has surprisingly good performance for being a consumer grade GPU card. If you have the chops to build your own rig, going this route comes with a one-time expense for the hardware, but comes with the headache of hosting and maintaining your training rigs.
Companies like https://lambdalabs.com/ offer customizable, relatively inexpensive training rigs that can be shipped to you. For example, a machine with 4x NVIDIA RTX A5000 cards, and NVLink, runs about $16,500. This includes the RAM, processor, casing, etc. All you have to do is find somewhere to plug this in, and pay your electricity bill.
Dedicated cloud servers
At AssemblyAI, we rent dedicated servers from Cirrascale. There are many providers like Cirrascale, but paying for a dedicated server offers much better pricing than the big public clouds like AWS or Google Cloud. This option also gives you the ability to customize your machines with the RAM and processor specifications you need, as well as offers much more flexibility as to the GPU cards you can choose from.
AWS, for example, only offers the following GPUs:
- NVIDIA Tesla M60 GPUs
- NVIDIA A100
- NVIDIA Tesla V100
- NVIDIA K80 (these are horrible)
Whereas Cirrascale, for example, offers a wide variety of GPUs such as P100s, V100s, A100s, RTX 8000s, and others.
Oftentimes, you don’t need the most expensive GPU cards (A100s today) to train your model in a reasonable amount of time. Plus, the latest and greatest GPUs are usually not immediately supported by popular frameworks like PyTorch and TensorFlow. The NVIDIA A100s, for example, took a bit of time before they were supported by PyTorch.
Being able to customize a machine to fit your training needs and budget is a huge benefit to working with a smaller hosting provider, compared to big public clouds like AWS or Google Cloud. You also don't have to worry about Speech-to-Text privacy concerns like you sometimes do with these big providers. Also, because you are renting an entire physical machine and not a virtualized machine like you get with AWS/GCP, the overall performance of the actual machine is much much better.
Wrapping Up
In sum, training large deep learning models as a startup is a challenge that not many other startups have to face. Costs can be high, iteration times can be slow, and these factors can seriously hinder your startup’s progress if you’re not careful.
If you’re thinking about starting a deep learning company - we highly recommend applying for Y Combinator’s Artificial Intelligence Track. AssemblyAI was part of this track in 2017, and it comes with a significant amount of GPU credits with the big public clouds like AWS and GCP, as well as discounts with providers like Cirrascale.
Daniel Gross’s Pioneer program also provides up to $100K in AWS credits, which you can splurge on training runs while you are getting off the ground.
If you want to read more posts like this, you can follow us on Twitter @assemblyai and @youvegotfox.





