


This week’s Deep Learning Paper Reviews is Barlow Twins: Self-Supervised Learning via Redundancy Reduction and Sparse MoEs Meet Efficient Ensembles.
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
What’s Exciting About this Paper
Most self-supervised learning algorithms are based on contrastive learning, which requires negative instances to prevent collapse.
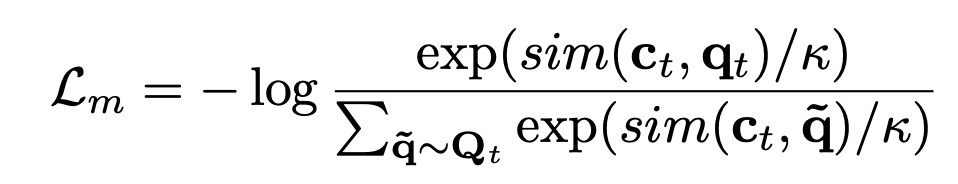
This paper comes up with an elegant, novel solution for self-supervised learning (SSL) without the need for negative instances.
It’s one of the first SSL solutions based on decorrelating features, rather than instances.
Key Findings
Barlow Twins naturally avoids collapse by measuring the cross correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible.
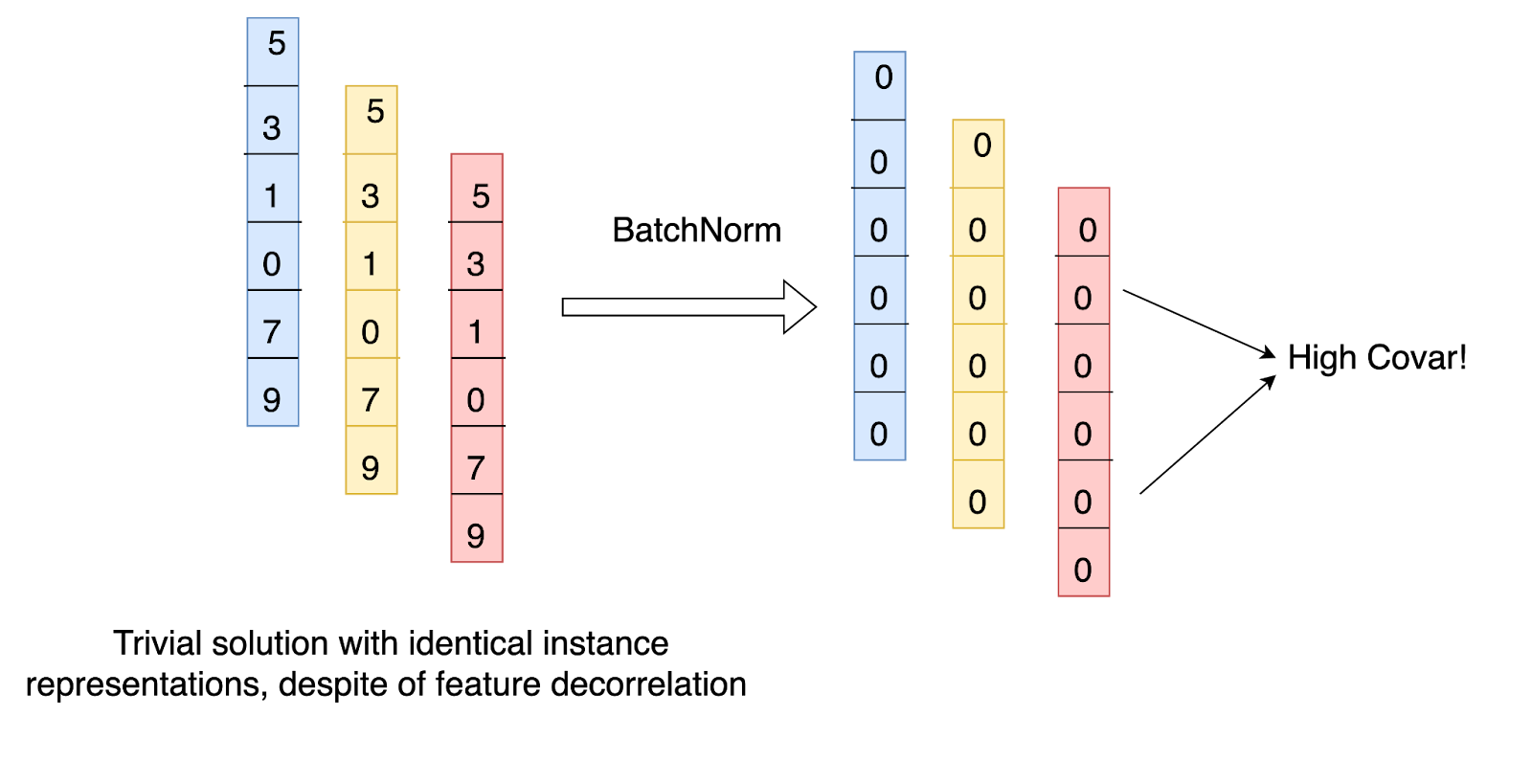
Batch normalization of features prior to the Barlow Twins loss is also critical to prevent collapse (an encoder outputs identical features for all images), since batch norm would reduce all features to 0s, which would result in high correlations (and high loss) between the features.
Our Takeaways
Barlow Twins is one of the first SSL techniques based on feature decorrelation that outperforms State-of-the-Art contrastive methods such as SimCLR.
Sparse MoEs Meet Efficient Ensembles
What’s Exciting About this Paper
Mixture of Experts (MoE) are neural networks that use dynamic routing at the token level to execute subgraphs of a large model. This enables them to have a larger parameter count than their dense counterpart while maintaining the same compute requirements. They have demonstrated impressive quality gains over dense models with the same floating point operations per second (FLOPS). Some have referred to MoE as dynamic ensembles. What are the differences between prediction performance with MoE and traditional model ensembles? This paper investigates this topic.
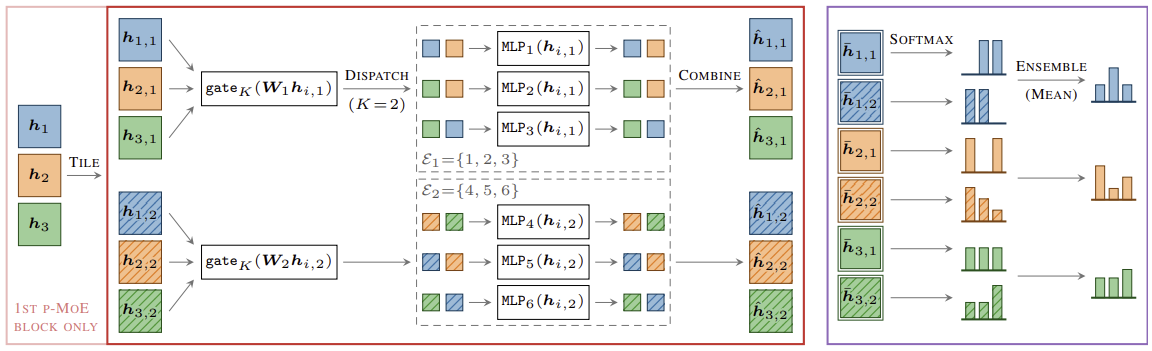
Below is a diagram of using both sparse MoE and model ensembles together. h1, h2, and h3 are different inputs in a batch, each model is a MoE and there are two models in the ensemble.
Key Findings
Sparse MoE and ensembles have complementary features and benefits. They can be used together to achieve higher accuracy, more robustness, and better calibration. Meaning that MoE is not a substitute or replacement for traditional model prediction ensembling.
They find that even as the number of experts used in the MoE increases there is additional value added by adding more models to the static ensemble. This observation is surprising because sparse MoE seem to already encapsulate the effect of static ensembles.
Our Takeaways
Sparse Mixtures of Experts have been shown to provide added value over their dense counterparts in NLP modeling tasks. They usually have the same computation cost as the dense model they replace. At first glance, they seem like a different and more efficient way of creating an ensemble of models, which could lead to the false assumption that further model ensembling would add little value. This turns out not to be the case and both methods can be used together for even greater quality predictions.





