

A joint group of researchers from Carnegie Mellon University and Università Politecnica delle Marche proposed a novel approach that combines Speaker Diarization (SD) and Automatic Speech Recognition (ASR) into a unified end-to-end framework, aiming to significantly simplify the speech processing pipeline while maintaining accurate speaker attribution and transcription.
Speaker Diarization is a powerful feature in multi-speaker speech processing that involves distinguishing and segmenting speech signals based on individual speakers. The SD model addresses the question who spoke when? in a given audio clip.

SD and ASR traditionally operate through separate pipelines, even though most real-world applications often necessitate transcriptions enhanced with segmentation and speaker identification. For this reason, being able to combine SD and ASR in a single speech model has many technical advantages. Let’s discover why this is so in the next section and then briefly survey how this new research tries to attack the problem.
What this research tries to solve
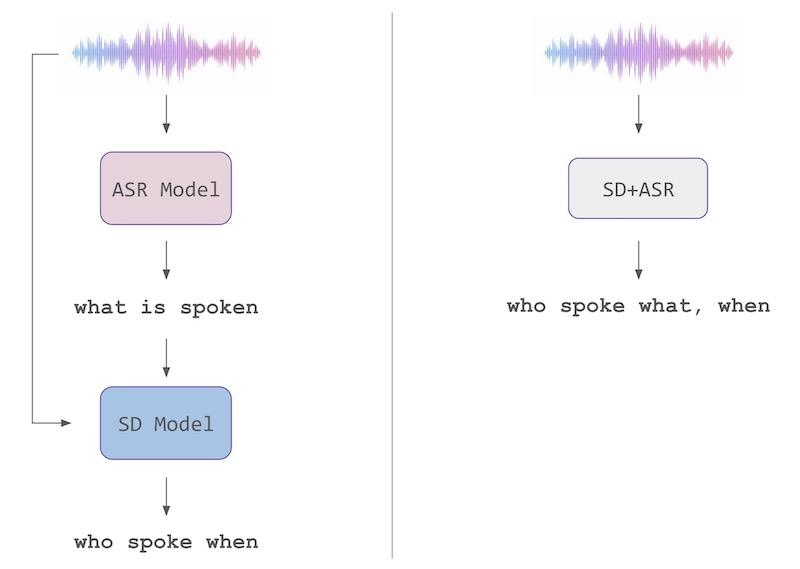
Conventional pipelines that couple SD and ASR rely on many distinct models, such as voice activity detection, audio source separation/segmentation, speaker embeddings, clustering, and ASR components.
Chaining multiple models results in some technical pitfalls, for example:
- Training multiple models separately makes it substantially more complicated to perform hyperparameter tuning than optimizing one model in a single run. This also makes model evaluation more difficult.
- Computational overhead derives from deploying a chain of different models, which requires higher compute costs and generally results in higher latency.
- Error propagation can cause degradation in performance due to the concatenated errors from separate models. For example, if the diarization pipeline starts with a sentence segmentation step –which in turn may take the ASR transcription as input– a small error by the segmentation model, such as missing an end-of-sentence, may drastically skew the result.
Recent years have seen various attempts to streamline the diarization process by merging distinct steps in the SD pipeline, aiming toward end-to-end diarization models. While some methods operate independently of transcribed text and rely only on the acoustic features, others feed the ASR output to the SD model to enhance the diarization accuracy.
However, many of these solutions grapple with constraints. Some methods struggle with handling more than two or three speakers, while others only perform well with short audio clips, yielding inconsistent results for clips of arbitrary length. Such limitations are significant stumbling blocks for practical uses of multi-speaker labeling and diarization.
Key insights
This new research proposes SLIDAR, a novel 2-step approach to SD+ASR, where:
- A single model jointly performs speaker attribution, speech segmentation, and speech recognition at a local level first via a sliding window approach.
- The speaker labeling is then “globalized” for the entire audio via a clustering and aggregation step performed on the results of the local pieces.
The primary idea involves analyzing fixed-length speech windows independently, employing a clustering mechanism to allocate global speaker identities, which allows processing arbitrary length audio inputs at constant memory requirements. This is achieved by adding several special tokens used to estimate and track different features in the audio clip.

More precisely:
- The local model is based on a refined Serialized Output Training strategy, which only has one output layer. The model predicts, for each utterance in the current input, timestamp tokens for onset and offset timestamps, as well as the words and speaker tag tokens for the speaker to which the utterance belongs.
- For each local window, the maximum number N of different speakers is estimated a priori, yielding N distinct speaker tag tokens: <|spk0|>, <|spk1|>, … ,<|spkN|>. This labelling only needs to be consistent within the local window, thus it does not affect the aggregation step.
- Additionally, a <|nospeech|> special token is used when the current window does not contain any speech, and a special truncation token <|trunc|> is used in place of timestamps when an utterance is truncated due to the windowing approach. This allows training the model on randomly sampled windows but also requires world-level segmentation to split truncated utterances.
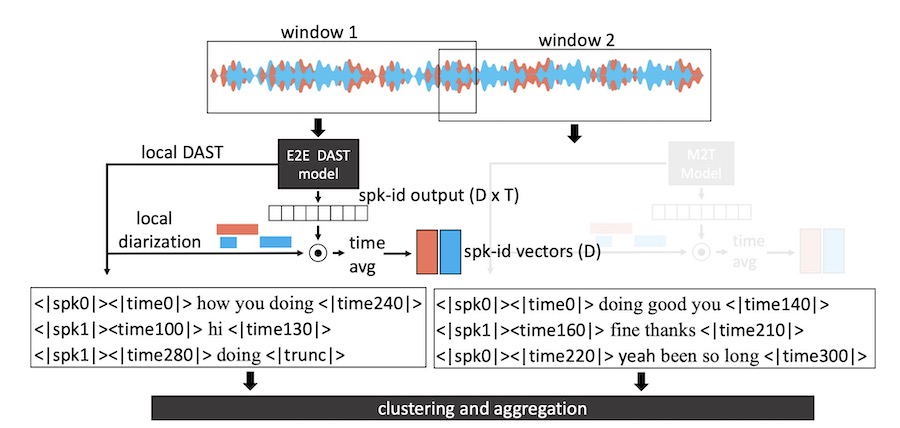
Together with the local augmented transcripts, the model estimates speaker embeddings for each window to encode speaker characteristics. These embeddings are then subjected to a clustering algorithm that assigns speaker labels, establishing distinct speaker identities for the whole transcript.
The model’s architecture is built upon an Acoustic Event Detection (AED) framework, allowing Whisper-like multi-task learning strategies. In particular, the authors introduce:
- An oracle diarization token <|OD|>, where the model is prompted with oracle diarization information for the local window. Oracle diarization refers to a hypothetical scenario where speaker change-points and identities are known perfectly in advance. Introducing the <|OD|> token was key for SLIDAR to reach high ASR accuracy (low cpWER).
- A <|vanillaASR|> task to enable training on non-conversational or single-speaker speech data.
- Whisper’s previous decoding window output conditioning (via a <|prev|> token) for the current prediction.
Experimental results for SLIDAR show comparable performance to state-of-the-art methods such as Transcribe-to-diarize, despite using significantly less supervised training data. For more details, see section 4 in the first reference below.
References
- One model to rule them all? Towards end-to-end joint speaker diarization and speech recognition, Samuele Cornell et al, arxiv:2310.01688v1, 2023.







