


This week’s Deep Learning Paper Recaps are Bridging the gap between streaming and non-streaming ASR systems by distilling ensembles of CTC and RNN-T models and BRIO: Bringing Order to Abstractive Summarization
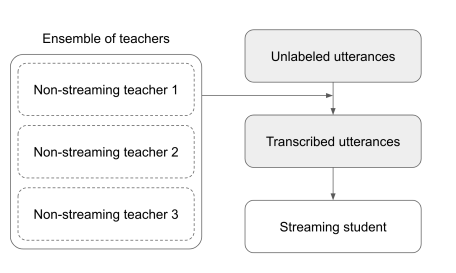
Bridging the gap between streaming and non-streaming ASR systems by distilling ensembles of CTC and RNN-T models
What’s Exciting About this Paper
Streaming models are usually constrained to be casual with no future context and also suffer from higher Word Error Rates. This paper bridges the gap between streaming and non-streaming models.
Student models described in the paper drastically improved upon the streaming models of previous work. The Word Error Rate (WER) decreases by 41% on Spanish, 27% on Portuguese, and 13% on French for the newer language models.
Key Findings
Using at least one CTC teacher leads to lower student WER. For example, an RNN-T student trained on CTC models outperforms counterparts trained on RNN-T teachers. Combining CTC and RNN-T gives the best results.
RNN-T student models outperform their CTC teachers. RNN-T student models suffer less from deletion errors when trained with a CTC teacher.
Our Takeaways
This way of distilling non-streaming models into streaming models greatly narrows the research focus to just asynchronous models and accelerates research velocity.
This approach of training streaming-student models not only drastically improves the results, but also closes the gap between non-streaming teachers and streaming students.
BRIO: Bringing Order to Abstractive Summarization
What’s Exciting About this Paper
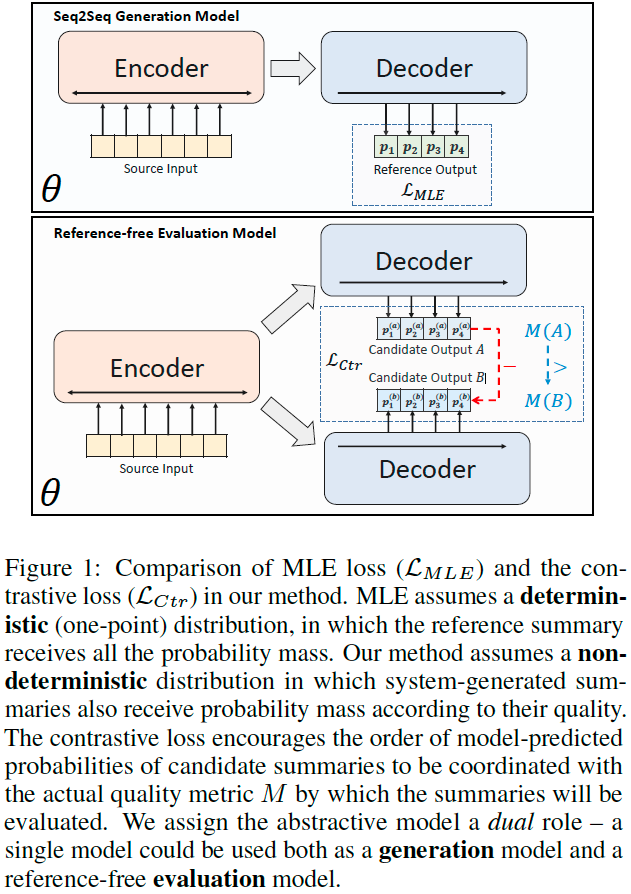
Summarization models are commonly trained using Maximum Likelihood Estimation (MLE). MLE assumes that an ideal model would assign all probability mass to the reference summary.
This may lead to lower performance at inference time, when a model must compare several candidates that deviate from the reference.
This paper proposes a training method in which different candidates are assigned probability mass according to their quality.
This method gives the model a dual role:
- As a generation model (trained using MLE), it generates the output summaries in an autoregressive manner.
- As an evaluation model (trained using a contrastive loss), it can be used to score the quality of candidates.
Key Findings
Their method establishes new State-of-the-Art results on several well-known and widely used datasets.
Their models estimate the probabilities of candidates that highly correlate with the candidates’ level of quality.
Our Takeaways
BRIO presents a novel training approach that can be used to improve the performance of Text Summarization models.
Their approach could also potentially be applied to other conditional text-generation tasks such as machine translation.





