

Language models (LMs) are a class of probabilistic models that learn patterns in natural language. LMs can be utilized for generative purposes to generate, say, the next event in a story by exploiting their knowledge of these patterns.
In recent years, significant efforts have been put into scaling LMs into Large Language Models (LLMs). The scaling process - training bigger models on more data with greater compute - leads to steady and predictable improvements in their ability to learn these patterns, which can be observed in improvements to quantitative metrics.
In addition to these steady quantitative improvements, the scaling process also leads to interesting qualitative behavior. As LLMs are scaled they hit a series of critical scales at which new abilities are suddenly “unlocked”. LLMs are not directly trained to have these abilities, and they appear in rapid and unpredictable ways as if emerging out of thin air. These emergent abilities include performing arithmetic, answering questions, summarizing passages, and more, which LLMs learn simply by observing natural language.
What is the cause of these emergent abilities, and what do they mean? In this article, we'll explore the concept of emergence as a whole before exploring it with respect to Large Language Models. We'll end with some notes about what this means for AI as a whole. Let's dive in!
Introduction
Language Models define a probability distribution over word sequences. They can therefore naturally be used for generative purposes by predicting the next most likely word(s) given the start of a text. In the example below, we see how an LM can predict the next most likely word in a sequence:

Language Models can also be used to perform other tasks. In this schema, an LM is trained in an unsupervised fashion on a large corpus, leading to basic language knowledge. Next, architectural modifications are made and task-specific datasets are used to fine-tune the LM in a supervised fashion, rendering it performant on the task in question. In the diagram below, we see how GPT's main Transformer LM is modified for different tasks. In particular, the inputs are prepared in specialized sequences with special tokens, and linear layers are appended to the model itself.
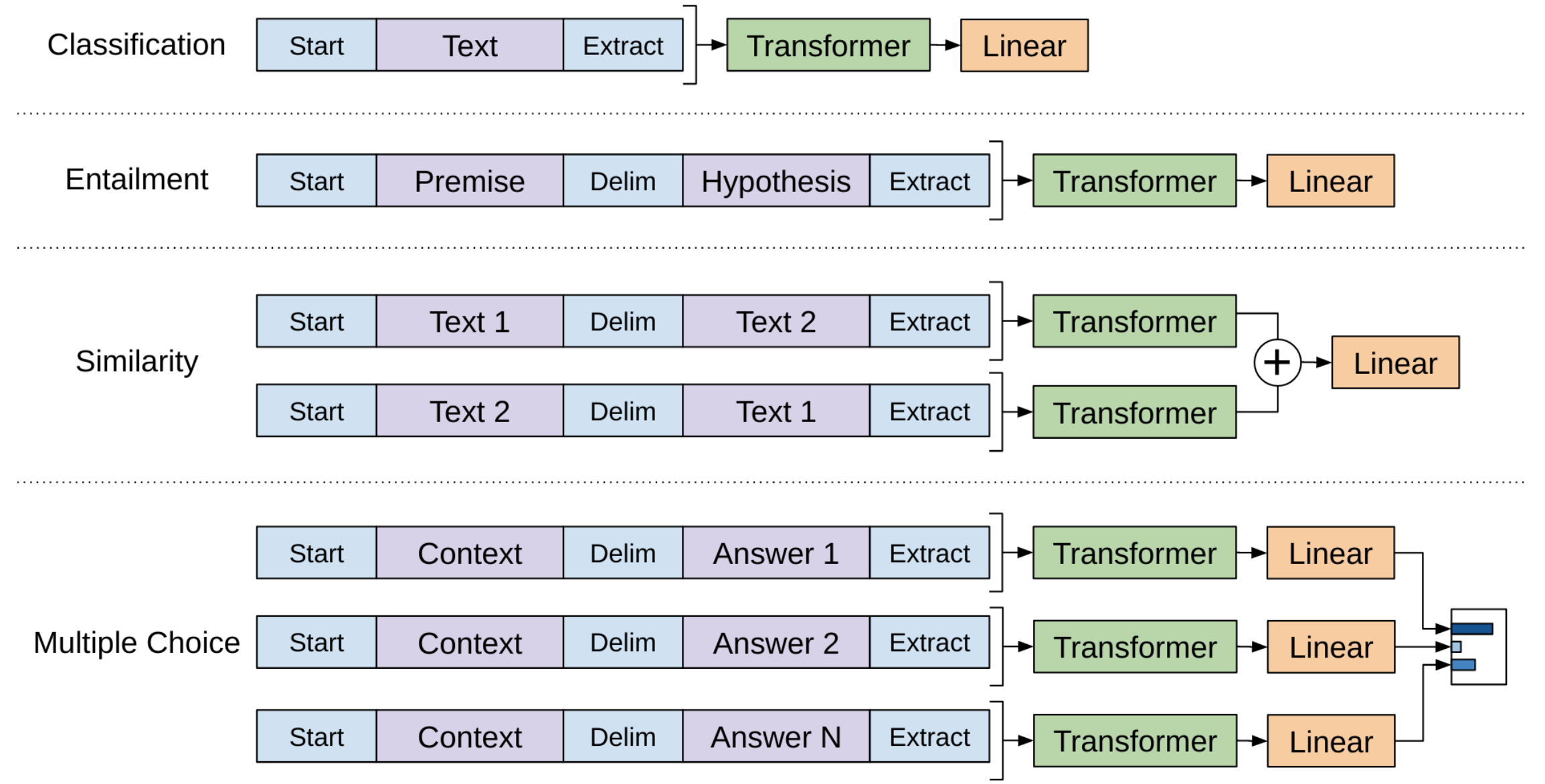
As it turns out, if you scale the Language Model into a Large Language Model, it is capable[6] of performing these tasks without any architectural modifications or task-specific training. LLMs are capable of performing these tasks, sometimes better[7] than specialized, fine-tuned networks, just by phrasing them in terms of natural language.

While the fact that LLMs gain these abilities as they scale is remarkable, it is the manner in which they appear that is especially interesting. In particular, many abilities of Large Language Models appear to be emergent. That is, as LLMs grow in size, they increase from near-zero performance to sometimes state-of-the-art performance at incredibly rapid paces and at unpredictable scales.
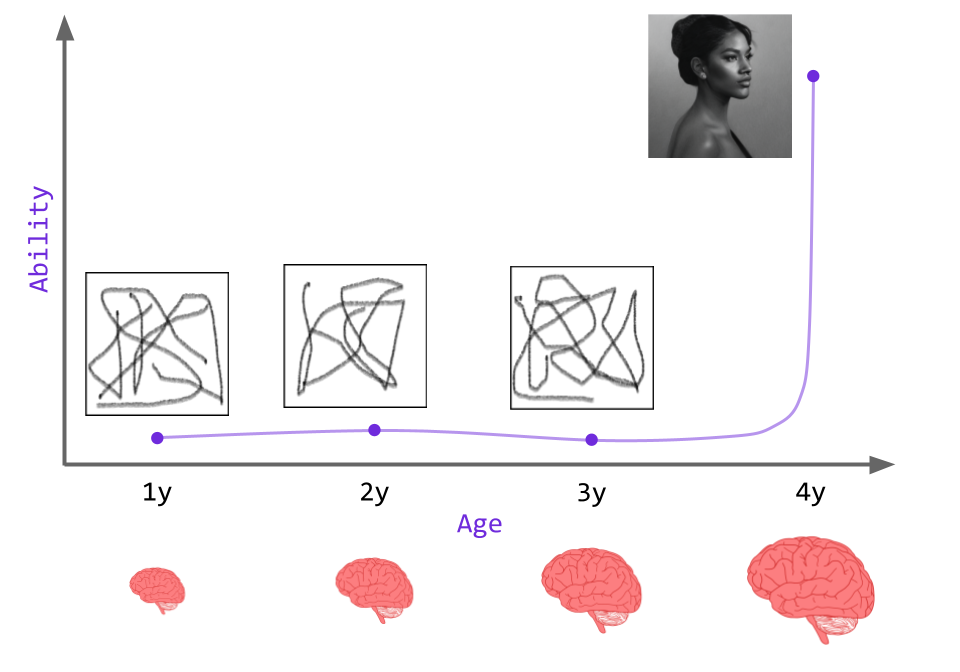
By analogy, consider a growing child who is unable to draw coherent pictures. As he grows, his brain smoothly increases in size and his fine motor skills smoothly improve; however, upon hitting a certain critical age there is a discontinuous “jump” in his ability to draw. This jump renders the child suddenly able to draw incredible portraits despite the fact that his fine motor skills show gradual improvement.
The concept of emergence is quite incredible, but it is not relegated to the field of AI. In fact, emergence has been observed and studied in various forms and in many disciplines. Before looking at emergence with respect to LLMs, then, let’s briefly examine emergence as an overarching concept. This overview, along with a concrete example from physics, will help us build intuition for why the observation of emergence in LLMs is so exciting.
Emergence as a general concept
Emergent behavior is not unique to LLMs and is in fact seen in many fields, such as physics, evolutionary biology, economics, and dynamical systems. While there is not a single definition of emergence that is used across domains, all definitions boil down to the same essential phenomenon of small changes to the quantitative parameters of a system making huge changes to its qualitative behavior. The qualitative behavior of these systems can be viewed as different "regimes" in which the "rules of the game", or equations dictating behavior, can vary drastically.
To illustrate this idea, let's take an example from physics. Consider water in the liquid phase, where the behavior of the system is governed by fluid dynamics. As the temperature of the water is steadily decreased, the specifics of how the system behaves may change (e.g. increased viscosity), but the overall qualitative behavior is similar and is described by fluid mechanics.

If the temperature continues to be steadily decreased, however, you will eventually hit a critical temperature at which the behavior of the system drastically changes. The water will enter the solid phase (ice), undergoing a phase transition that completely changes the "rules of the game". Suddenly the system is no longer obeying fluid mechanics but solid mechanics, entering a new regime in which the laws governing the system's behavior change in a qualitative way.
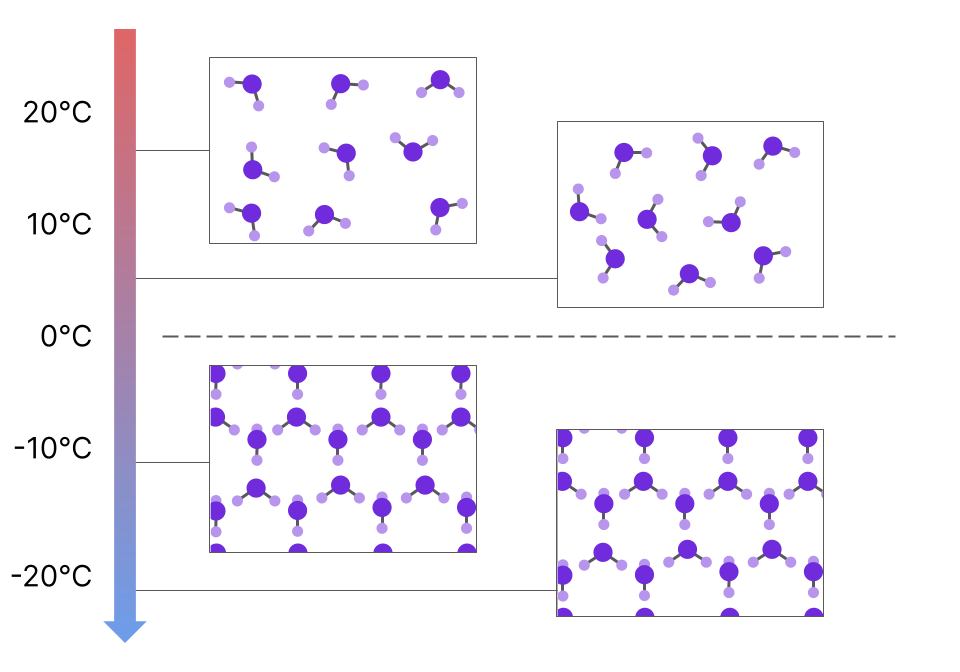
It is important to note that this change in behavior occurs in a discontinuous fashion with respect to temperature. As the temperature is steadily attenuated, the behavior changes abruptly upon crossing the critical threshold.
While we may take the process of ice freezing for granted because it is so pedestrian to us as humans, it is quite a remarkable phenomenon that has tremendous implications and applications in more exotic domains.
Emergence for fault-tolerant quantum computation
While the above example of water is helpful in that it is familiar to everyone, it does not sufficiently communicate the utility of emergent properties and phase transitions.
The phenomenon of superconductivity is another example of emergent behavior that arises as a function of temperature. Superconductivity is a phenomenon in which the electrical resistance of certain materials drops to zero below associated critical temperatures. This means that electrical current flows through superconductors with zero energy loss. This sudden change in behavior is similarly associated with a corresponding phase transition.
Emergent phenomena like these constitute huge areas of research and potential avenues to advanced technologies. Superconductivity in particular has many interesting potential applications, not the least of which as part of a potential route to fault-tolerant quantum computation. Could similar distinct regimes exist in LLMs; and, if so, might we discover additional useful regimes if we scale further?
This question is posed simply as a thought exercise - different regimes with distinct equations that govern behavior seem much less plausible in a neural network than a physical system. The purpose of adding this information is to highlight the fact that emergent behavior as an overarching concept is something to be excited about and is something that is under active investiation in other fields.
As we have seen, LLMs too appear to undergo these drastic qualitative changes, in their case as a function of scale rather than temperature. Let's take a closer look at this phenomenon now.
Emergence in Large Language Models
Scaling language models has demonstrated consistent and predictable improvements to performance, with the scaling law for the cross-entropy loss of language models holding at more than 7 orders of magnitude[2].
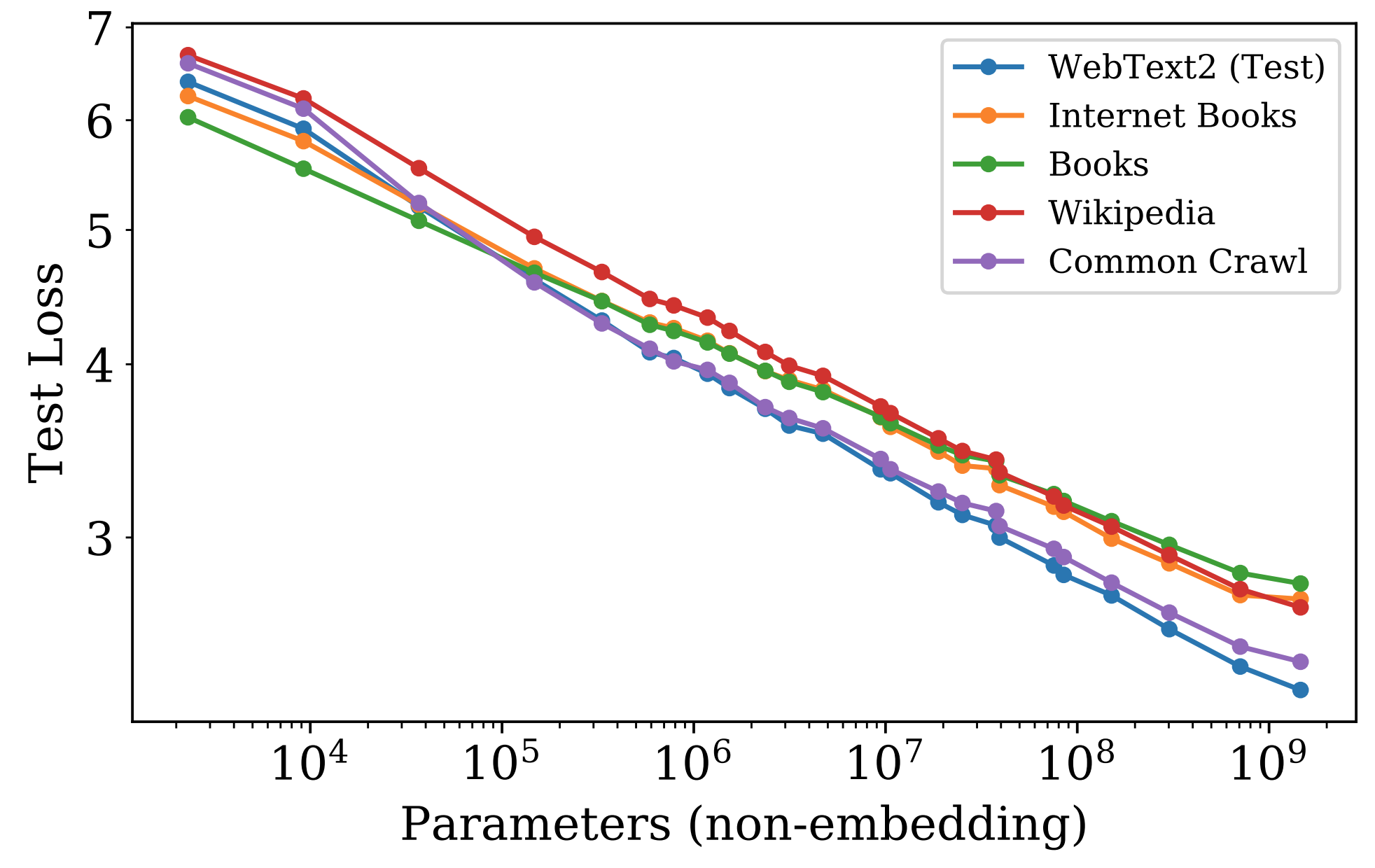
In other words, the performance of Language Models on their training objective steadily improves with scale. As we have noted above, this behavior is in contrast to the emergent abilities of LLMs, which are not directly trained for and which rapidly appear. Let's take a look at a specific example of one such ability now.
Guessing a movie from an emoji sequence
emoji_movie is a task in the BIG benchmark[1] (BIG-bench) in which a sequence of emojis describes a particular movie, and the task is to guess the movie given the sequence. For example, the sequence 👧🐟🐠🐡represents Finding Nemo, and the sequence 🦸🦸♂️👦👧👶 represents The Incredibles.
BIG-G is a Language Model with a decoder-only Transformer architecture. Below we can see the performance of BIG-G on emoji_movie at various scales.
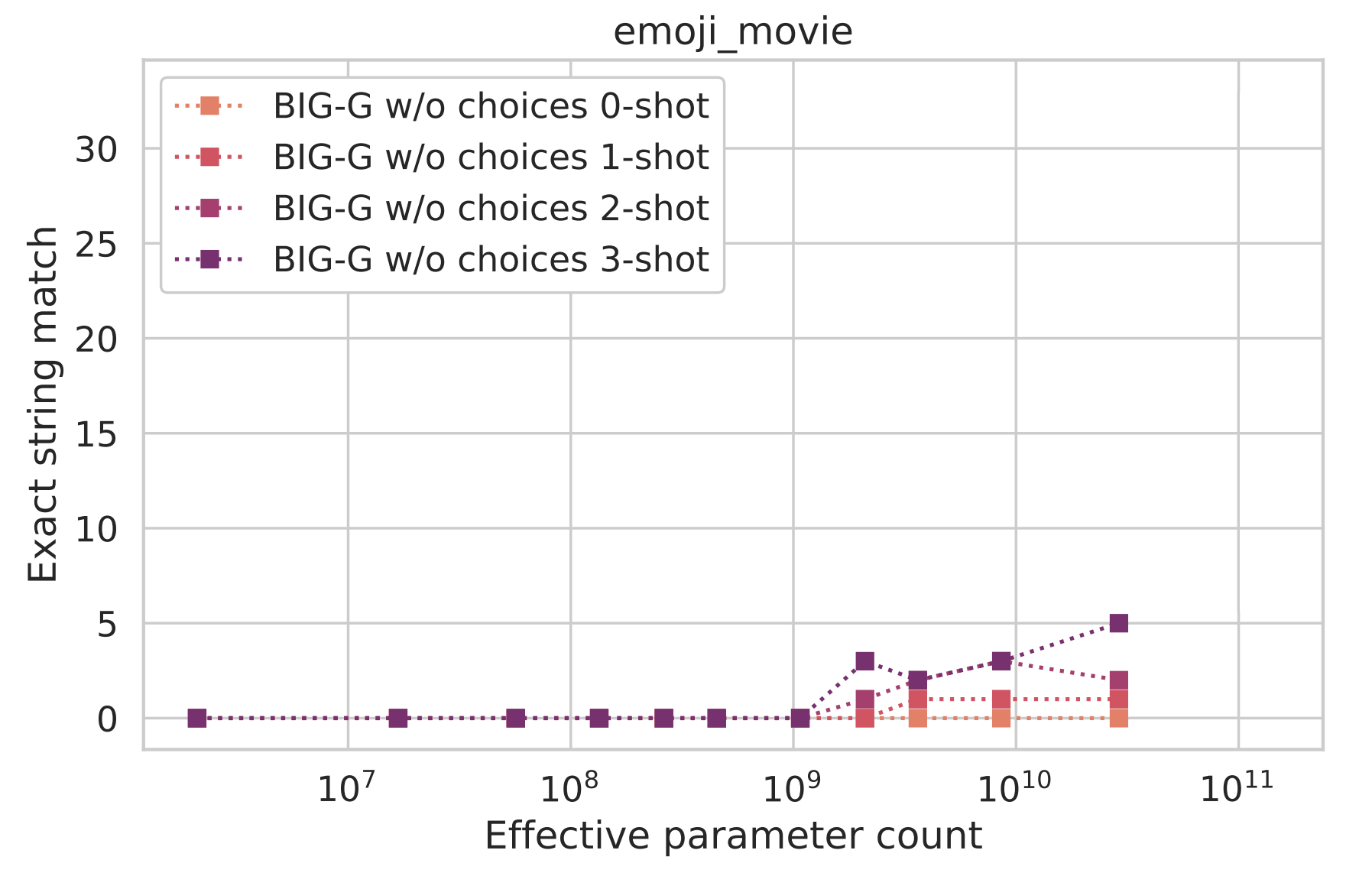
As we can see, the model performs quite poorly across scales, which is perhaps unsurprising. After all, a language model simply defines a probability distribution on token sequences, and the task requires finding nemo being the most probable string that should follow What movie does this emoji describe? U+1F9B8 U+200D U+2642 U+FE0F U+1F9B8 U+200D U+2640 U+FE0F U+1F466U+1F467 U+1F476 (the Unicode string for the Finding Nemo emoji sequence above).
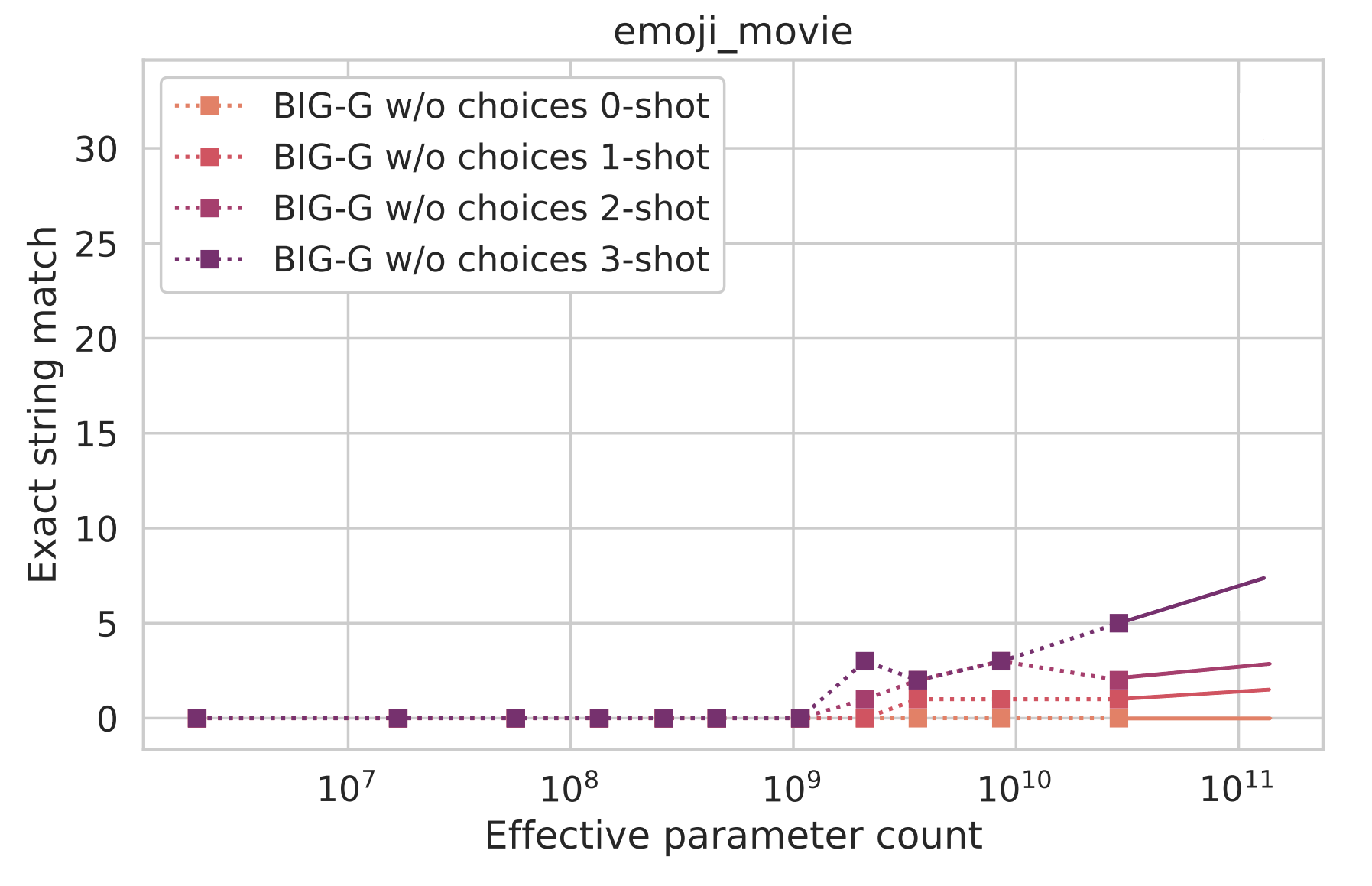
Nevertheless, the model appears to be getting slightly better as its size grows. If we extrapolate using just the last few scales, we might expect something like the below graph, where the solid lines are the extrapolations.
However, what we actually find is this:
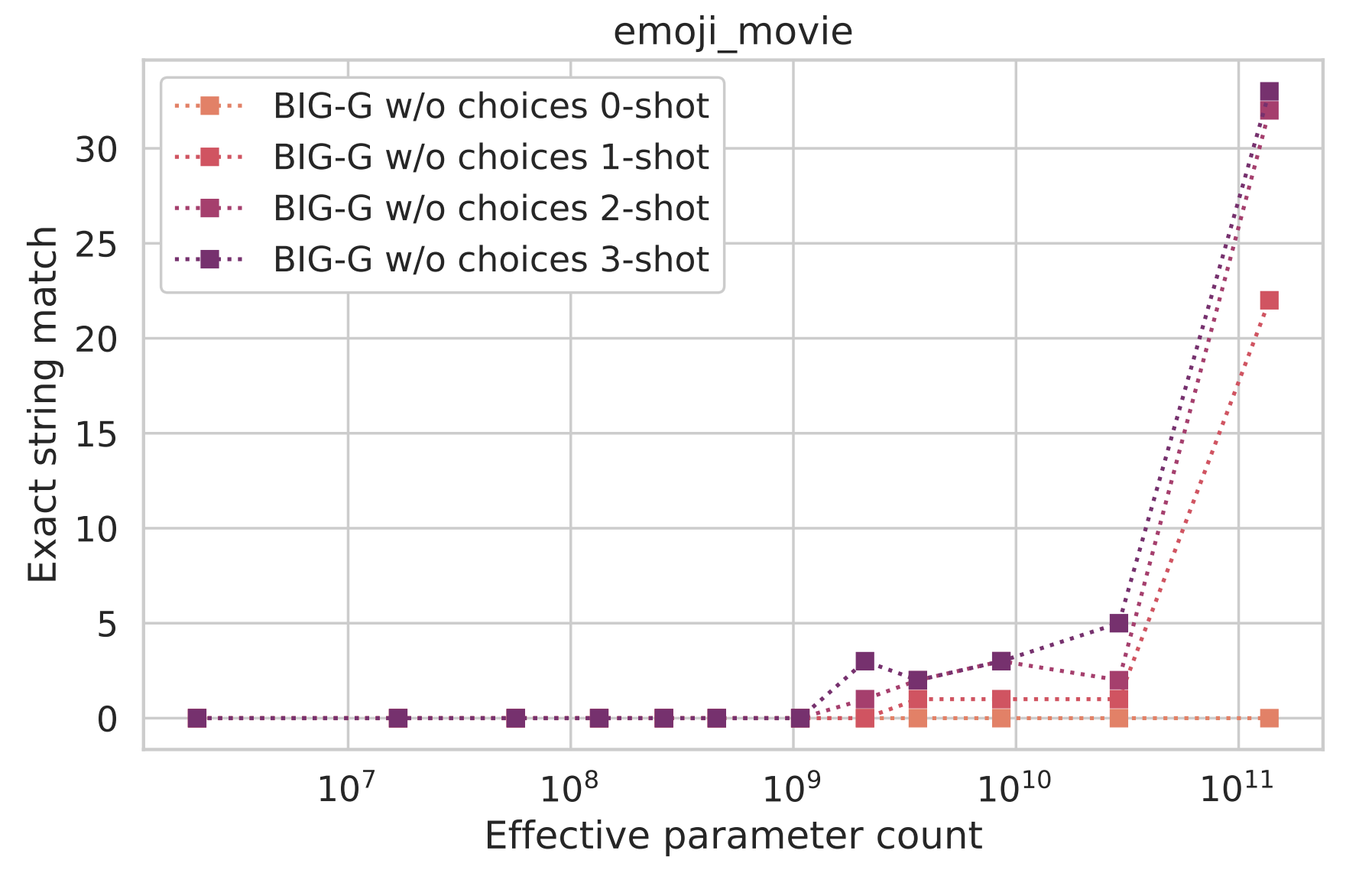
After crossing an apparent critical value (between 1010 and 1011 effective parameters), the model seems to be catapulted into a new regime in which it can complete this (fairly complicated) task with drastically increased accuracy.
Emergence across tasks
This accuracy boost is not the only one to emerge with scale - several other tasks in BIG-bench have been shown to exhibit similar behavior. Somewhat mysteriously, all of these abilities emerge at a similar scale despite being relatively unrelated.
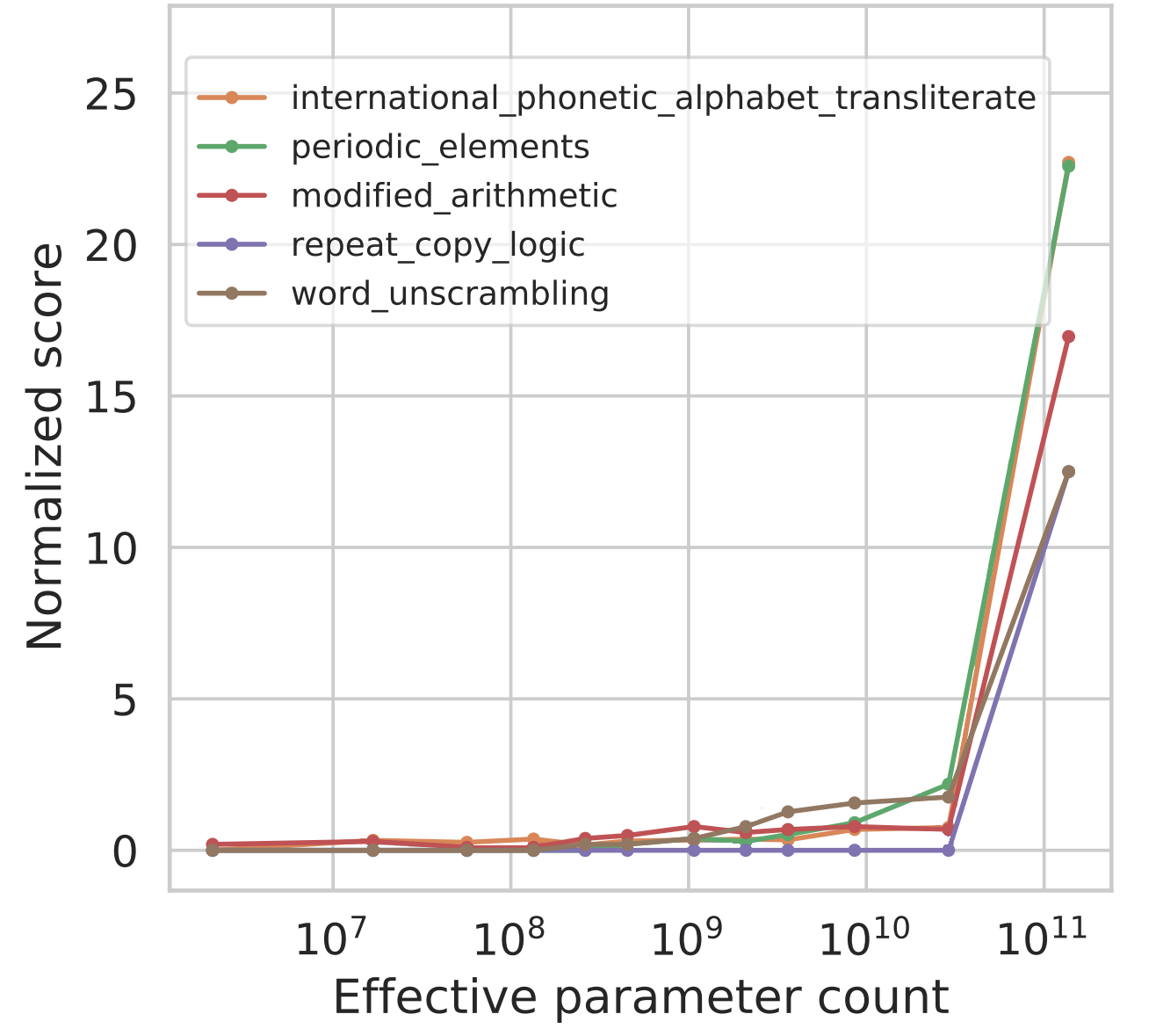
Task information
-
international_phonetic_alphabet_transliterate- transliterate an English sentence to the International Phonetic Alphabet -
periodic_elements- predict the name of a chemical element given its periodic number -
modified_arithmetic- given two 3-digit numbers, find their sum -
repeat_copy_logic- follow basic natural-language instructions -
word_unscrambling- given a scrambled English word, unscramble the letters to recover the original word
The important part about this phenomenon is that we, a priori, do not know that this will happen in advance or even at what scale it might happen. Therefore, while we may try to devise new architectures or some other novel invention to tackle complicated problems involving natural language, we may be able to solve these problems simply by scaling LLMs to be even larger.
Even if these problems could be solved by better architectures or some other innovation, the ever-improving hardware and AI ecosystem leaves open the possibility that time alone will solve these issues.
Emergent abilities - fact or illusion?
While these emergent abilities are exciting, it is now time for some healthy scientific skepticism. As we noted at the beginning of this piece, emergent phenomena as a concept are quite remarkable and generally follow a fundamental change in the regime of the system, in which "the rules of the game" change. It is unclear at this point what exactly this actually means with respect to Language Models.
Researchers have attempted to provide logical explanations for the mysterious phenomenon of emergence in LLMs - let’s take a look at two of them now.
Multi-step reasoning
One of the simplest explanations is that LLMs display apparently emergent phenomena because of what we are actually measuring. If LLMs get smoothly better at elementary reasoning with scale, these improvements could lead to highly nonlinear observations. If the complicated tasks that we are measuring performance on can be cast as a reasoning chain that must be fully intact to measure a "success", then incremental improvements to reasoning ability will be masked. This is briefly mentioned by [1] and [2], but let's expand on this idea and concretize it with an example.
Consider a model M that has a certain probability p of a successful single reasoning step. In addition, consider a multi-step reasoning problem which requires a chain of, say, ten successful reasoning steps to solve. Assuming the reasoning steps are independent, the probability of success for k steps is given by the binomial distribution. The below graph shows the probability of getting at least x successes, varying as a function of p. Therefore, the probability of solving the problem is given by the probability of the last point, where x = 10 (colored in red for differentiation).
There is a rapid increase in the probability of task success with a steady tuning of p. We can directly plot this as below, where the y-axis corresponds to the probability of full-chain success as a function of p given on the x-axis:
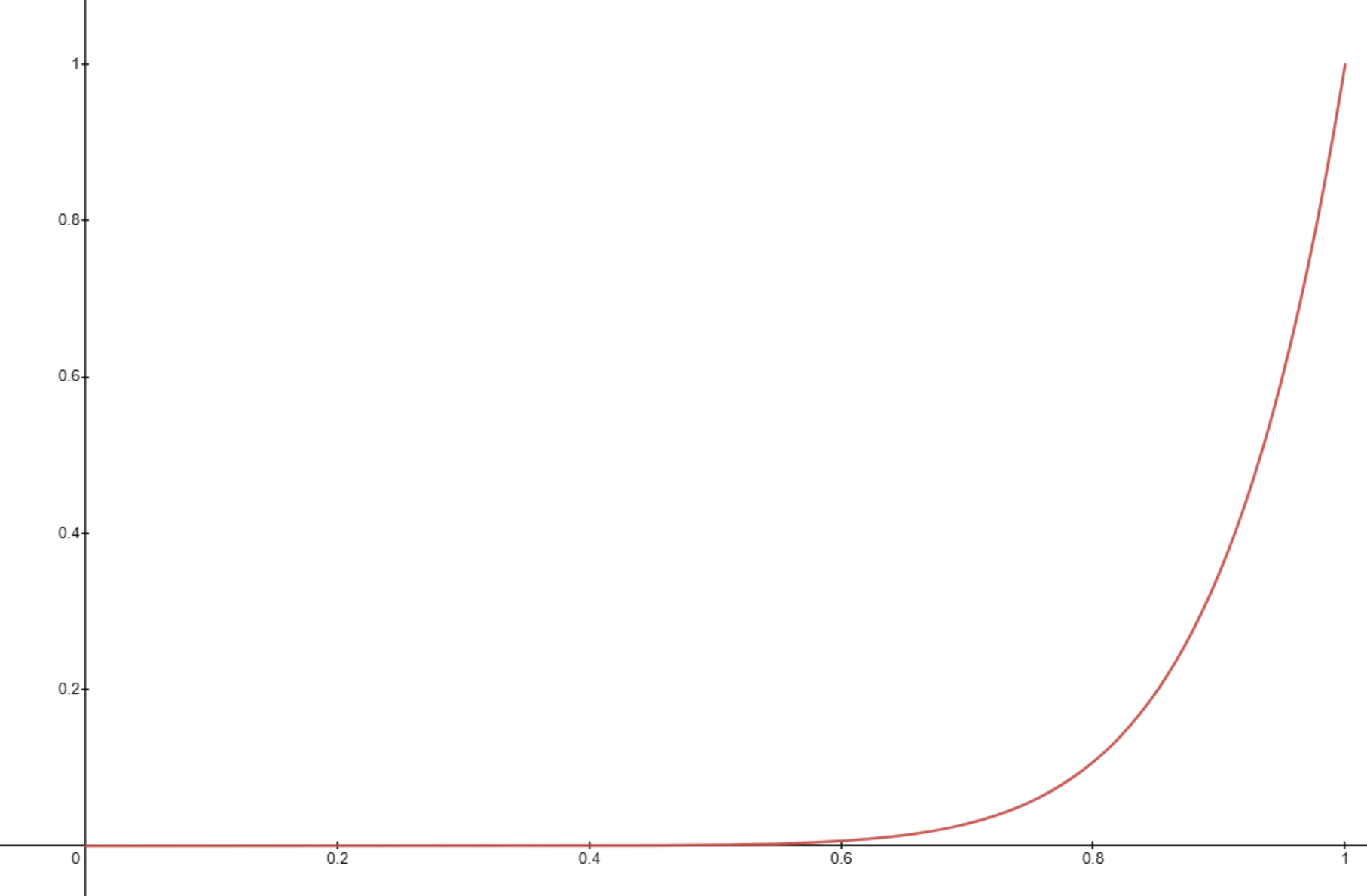
The steepness of the curve implies that those abilities which involve multi-step reasoning may not be "truly" emergent, but simply (or at least partly) a result of an increased ability to perform an elementary task (responding with answers that align with reasoning) that smoothly changes with scale.
Importantly, the above curve only becomes sharper as n (the number of steps in the reasoning chain) is increased. Below we see a plot of this curve changing with n.
Therefore, we would expect more complicated problems to be solvable only at the largest scales, and the rate of improvement for these problems to increase commensurately.
Note that this is a toy model and we have not defined what it means to "reason" nor implied how we might smoothly measure an LM's ability to generate responses that align with "reasoned" answers. This example is just to provide some intuition that small changes to elementary abilities may have a drastic cascade of effects observed in the LLMs' ability to solve more complicated problems.
Misaligned evaluation metrics
Above we considered how abilities may appear to be emergent when in reality they rely on the compounding effects of a steadily improving value. In addition to apparent emergent phenomena being attributable to what we're measuring, they may also be attributable to how we take these measurements - i.e. misaligned evaluation metrics.
Emergent behavior is necessarily coupled to a measurement with respect to which the emergence is observed. In our above example of the emoji_movie task, this evaluation metric was exact string match. If we instead make this evaluation metric multiple choice (right) rather than exact string match (left), we see more gradual improvements and the emergent behavior disappears.
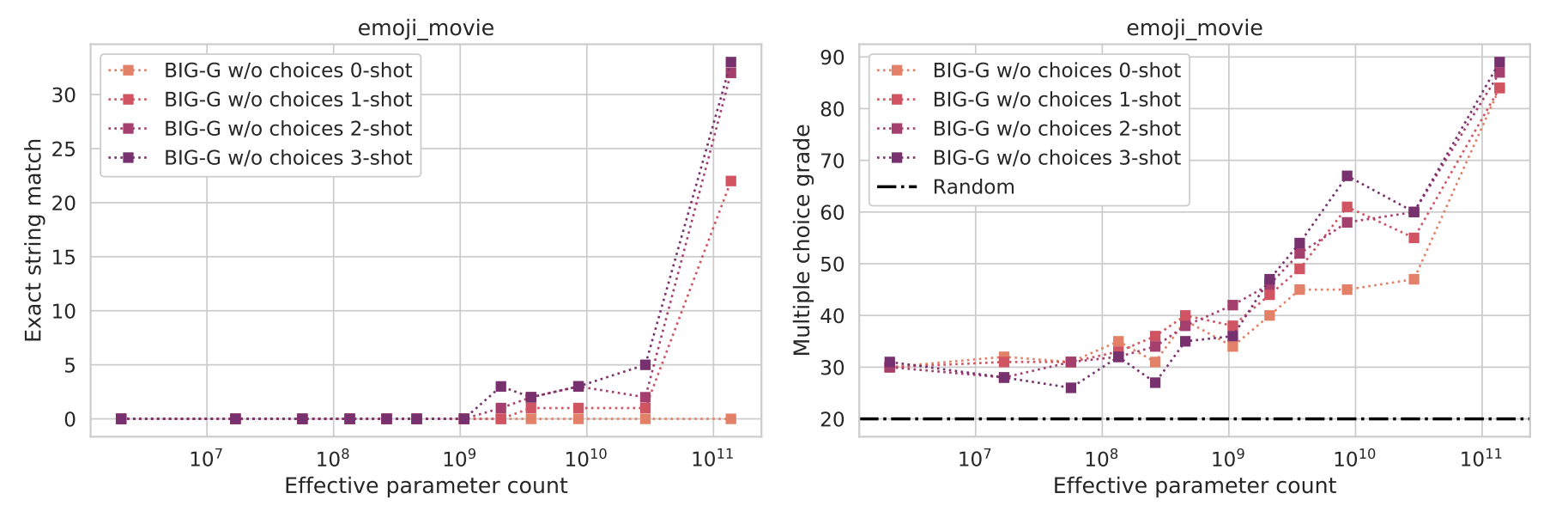
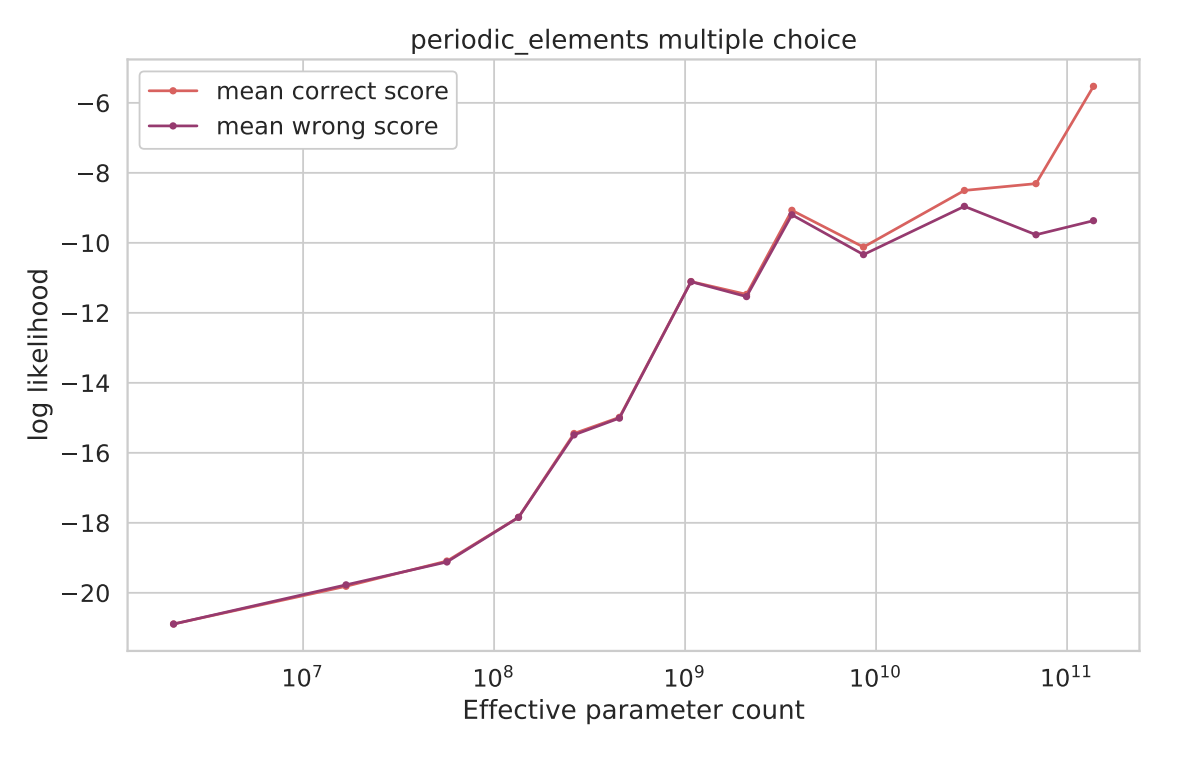
The existence of these emergent phenomena appear even more tenuous if we dive into the details of how each evaluation metric is actually calculated. For the periodic_elements task, in which the model must answer which element name corresponds to a given atomic number, the exact string match metric hid correct outputs as noted by the authors of [1]. For example, in some cases a model would output something like "The element with atomic number 1 is hydrogen", but since this did not exactly match the string "hydrogen", the apparent performance was deflated for which postprocessing was required to correct.
Taking this a step further, we can remove the "all-or-nothing" evaluation that is inherent to a metric like exact string match. Since we can directly calculate the probability of different responses, we can instead evaluate the log likelihood for the correct response. When we do this, we see gradual improvements to the probability of correct answers, and a growing divergence between the likelihood of correct and incorrect scores with scale.
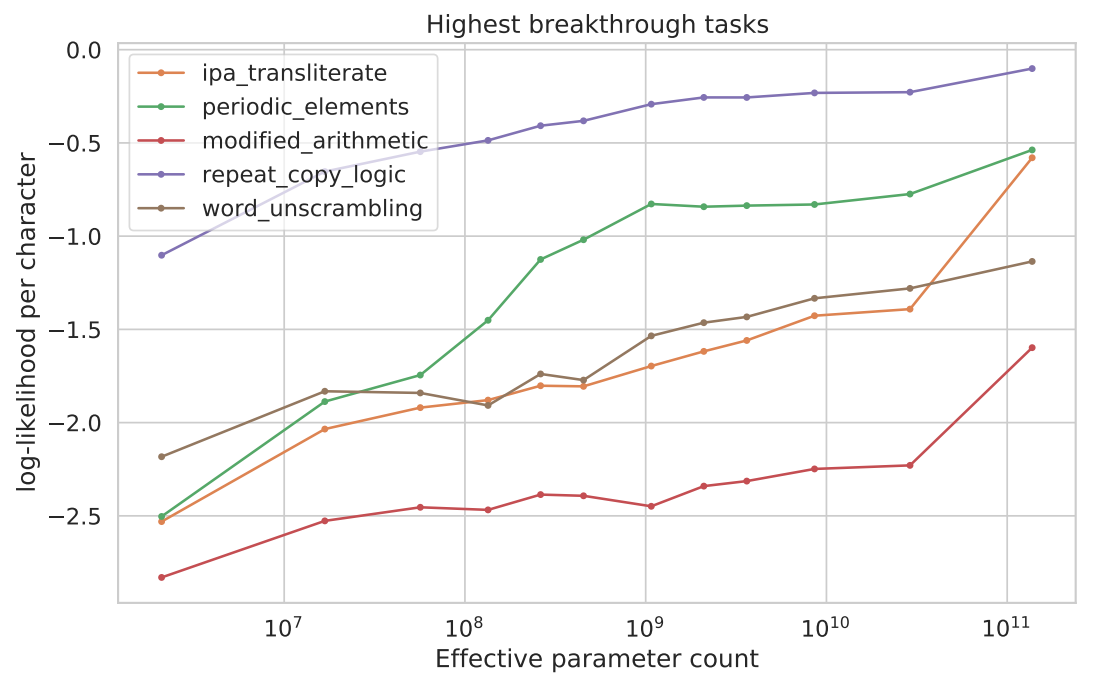
We can similarly evaluate log likelihoods for various apparently emergent abilities, and see gradual improvements with scale across all of them.
Evaluation metrics like exact string match are discontinuous and afford no notion of "closeness". If we were, for example, training an agent to throw a ball at a target, such evaluation metrics would be like measuring whether or not the agent can hit the target rather than how close it gets to the target. Even if the final goal is to train an agent to actually hit a target, being within 1 cm is substantially better than being within 1 km, and measuring actually hitting the target as an "emergent" ability isn't really capturing the entire picture.
A retort to this view is that, ultimately, we only care how AI performs on tasks that we as humans care about. If an AI agent cannot perform a certain task to a certain threshold, then we consider the agent a failure for all intents and purposes. But we must remember that the tasks like those which compose BIG-bench are individual probes that measure one specific ability - performance across all tasks in the aggregate is what gives us a more holistic measure of LLMs' overall behavior.
When we consider this holistic picture for a model like GPT-3 by looking at aggregate performance across benchmarks, we find that it is smooth with scale.
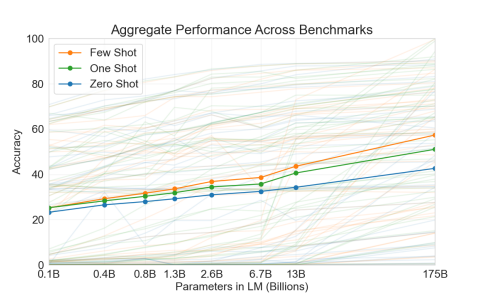
Even then, aggregate performance on a benchmark is not a complete characterization of the model, and its apparent performance will vary depending on how we curate the benchmark itself.
There are other potential explanations[1][2] for the emergent abilities of LLMs, but the above explanations suffice for our purposes.
What does this all mean?
We have talked about the concept of emergence, how it appears in large language models, and more. But what does this all mean? Where do we go from here?
In short, at this point, it is unclear. There are several important things about the emergent abilities of large language models to keep in mind.
- We don't know at what scale they will appear
- We don't know the level of ability until they do appear
- We don't know the landscape of potential abilities
Even if something simple like multi-step reasoning is a significant explanatory factor for emergent abilities, their mere existence is still important. Ultimately, if completing tasks we as humans actually care about requires multi-step reasoning, and many of them likely do, then it doesn't really matter if there is a simple explanation to emergent abilities. The simple observation that scaling models may increase their performance in real-world applications is enough.
The question then becomes, why don't we do this scaling? Just as we build larger and larger particle colliders in physics for the purposes of finding new particles, why don't we build larger and larger Language Models in search of new emergent abilities? The Large Hadron Collider alone cost almost 5 billion dollars, which is multiple times more than the total initial investment into OpenAI, and it was not built with practical applications in mind. Why have we not put this investment in for a technology that has huge transformative potential?
How much larger can we go?
A several-years-old analysis by Andy Jones at Anthropic postulated that we were then (in 2020) capable of building orders-of-magnitude larger models than those which had been built at that point. This analysis importantly came out after the release of the GPT-3 paper[7].
Early rumors about GPT-4 claimed that the model would scale up from the 175 B parameters of GPT-3 to 100,000 B (100 trillion) parameters in GPT-4. According to [1] such a model, if on-trend, would be approaching human-level performance across many existing benchmarks.
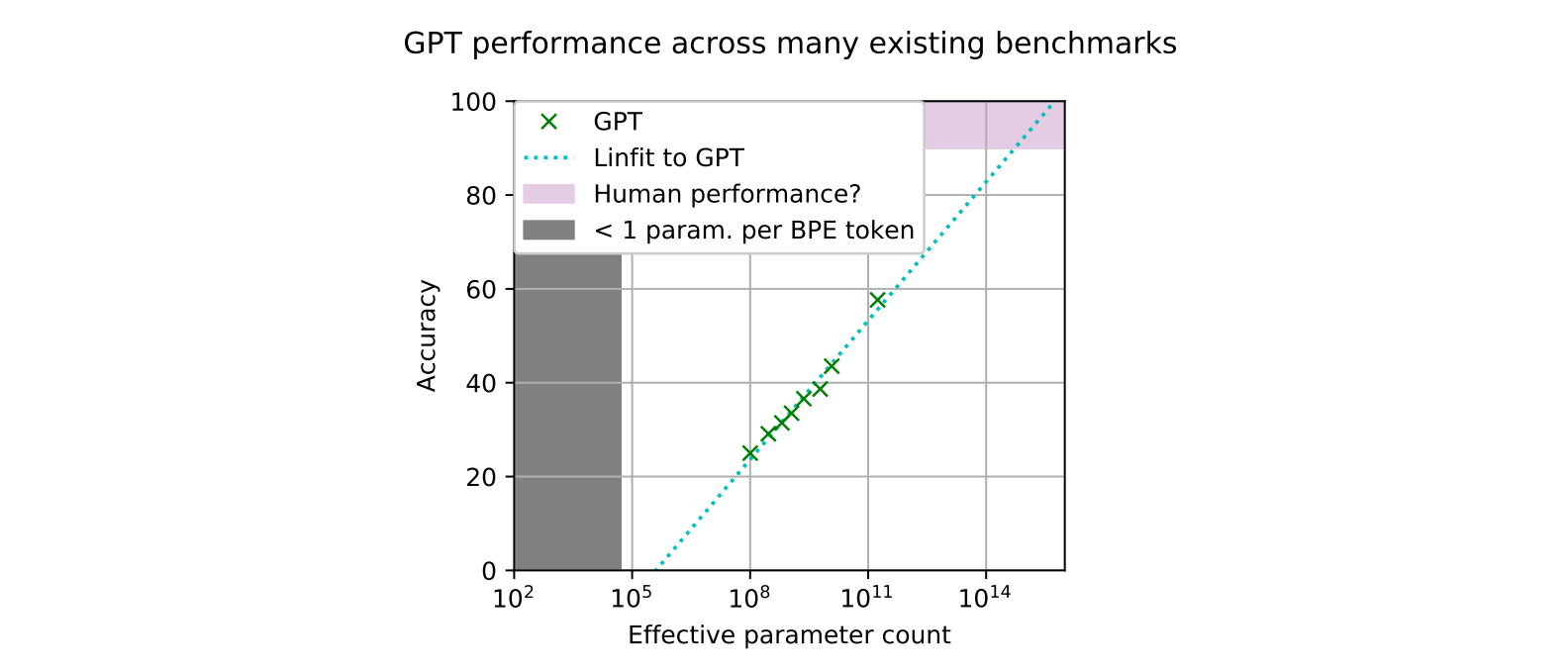
Sam Altman, the CEO of OpenAI, has dismissed the 100 T parameter claims as completely baseless, and GPT-4 is expected to not be much larger than GPT-3. But, if such an analysis is correct, why not build a much larger model, even if not a 100T parameter model?
Jones' analysis was heavily informed by a paper[3] from OpenAI, released in 2020, on scaling laws for neural language models. In particular, they studied, given a fixed increase in compute, how one should distribute this additional compute between increasing training data and increasing model size. The paper found that model size should consume a greater proportion of these additional resources, meaning that scaling model size is more important than scaling dataset size.
Specifically, model size should grow about three times as quickly as dataset size. Given a 10x increase in compute budget, dataset size should increase by about 1.83 times and model size should increase by 5.48 times.
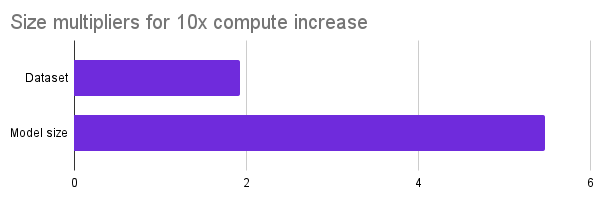
A 100 T parameter model would be about 571 times larger than GPT-3. Therefore, according to OpenAI's scaling law, we would expect such a model to require 190 times more data.
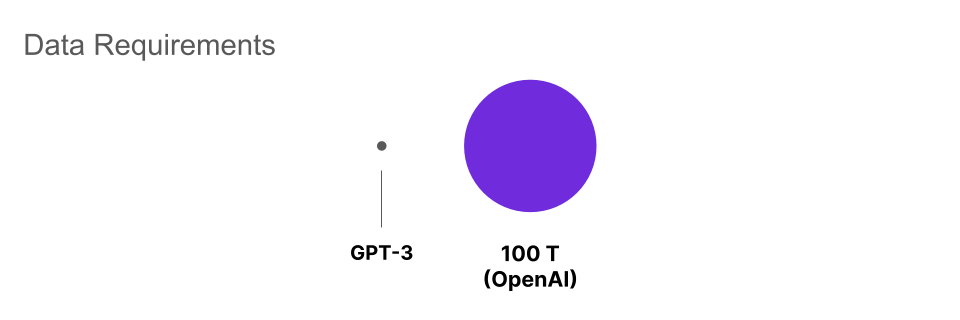
However, more recent research (from DeepMind) has found updated scaling laws. Indeed, the authors of the Chinchilla paper[4] find that data and model size should be scaled in equal proportions.
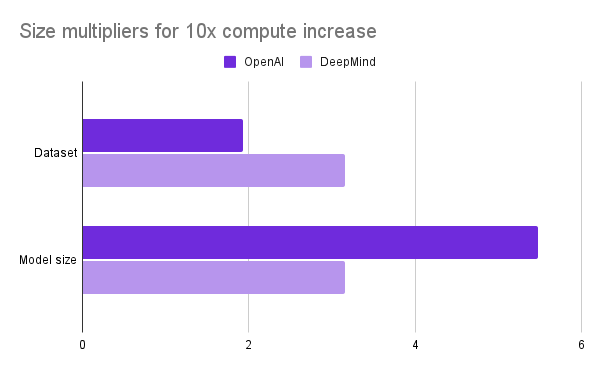
In particular, they find that the number of tokens required to optimally train an LLM should be about 20 times the number of (non-embedding) parameters. Given this scaling law, a 100 T parameter model would require about 2,000 T tokens. This is about 20 times more data than expected based on the scaling laws in [3], and a staggering 4,000 times more data than GPT-3.
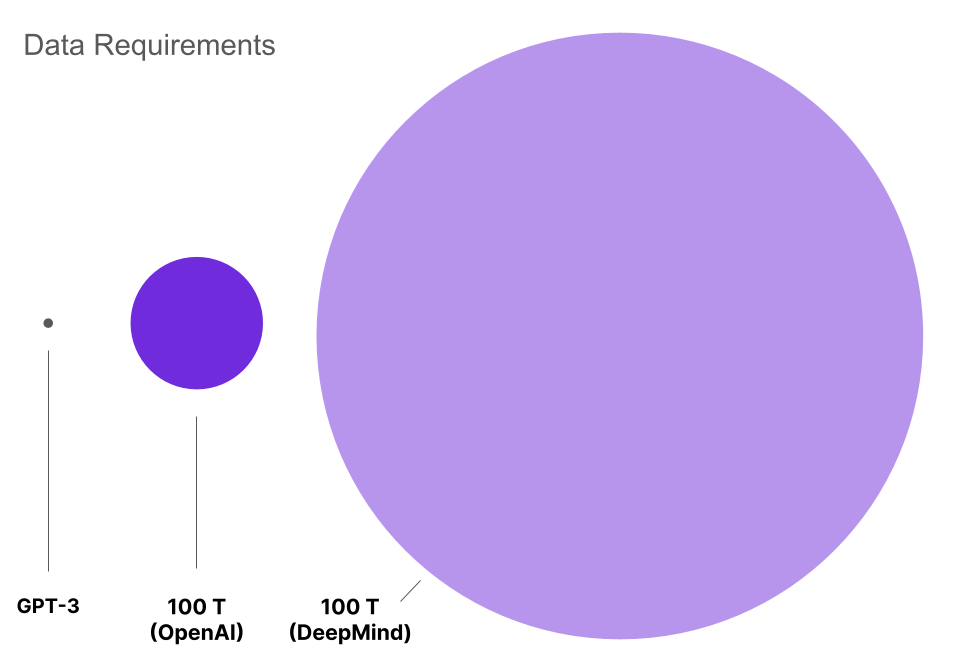
GPT-3 was trained on several datasets, with the bulk of the data coming from Common Crawl. OpenAI used 45 terabytes from Common Crawl, meaning that a 100 T parameter model would need 180 petabytes of such data to optimally train according to the Chinchilla scaling laws. The other datasets used to train GPT-3 would be dwarfed by data scales this large, meaning that all of the data used to train a 100 T parameter model would need to come from a dataset like Common Crawl. Add to this the fact that the non-Common Crawl datasets were preferentially sampled due to their higher quality, and we see that 180 petabytes is actually a lower bound on the amount of data that would be needed to train such a model. Common Crawl in its entirety is about 12 petabytes as of the writing of this article, so it falls a long way short of this number.
We can see why claims of 100 T parameters were so quickly dismissed by Altman. While the amount of data generated every day grows year over year, only a fraction is stored, textual, available, and suitable for training. Combining this fact with hardware and cost limitations means that scaling models to such astronomical sizes to search for emergent abilities is impractical at this point.
Final Words
The observation of emergent abilities of Large Language Models is an interesting development. More studies into this phenomenon are needed for a more complete picture, for example testing task performance on large models with early-stopped training to smaller models (with equivalent test loss and training compute) to see if scale alone is actually a critical factor for emergence in LLMs.
It would be useful to have an epistemological hierarchy of tasks, in which salient and measurable abilities are identified and listed as a required antecedent to more complicated tasks which utilize them. Such a hierarchy may help us begin to predict at what scale some emergent abilities may occur, or at least provide an ordering on the set.
Further, observing emergence with respect to a task like emoji_task doesn't mean much on its own. If a model also displays emergence with respect to other tasks in a similar "epistemological cluster" in such a hierarchy, then we may be able to say more about emergence with respect to fundamental reasoning concepts rather than isolated tasks like emoji_movie.
Ultimately, even if there are potentially simple factors that contribute to explanations for apparently emergent abilities, the fact that they exist at all is an exciting development. After all, we as humans ultimately care less about continuous performance curves than we do how AI can impact our lives. What other abilities might lay as yet undiscovered?
For further reading on AI, check out some of our other content like How ChatGPT Actually Works or An Introduction to Poisson Flow Generative Models. Alternatively, feel free to follow us on Twitter to stay in the loop when we release new content!
References
[1] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of large language models
[2] Emergent Abilities of Large Language Models
[3] Scaling Laws for Neural Language Models
[4] Training Compute-Optimal Large Language Models
[5] Improving Language Understanding by Generative Pre-Training
[6] Language Models are Unsupervised Multitask Learners
[7] Language Models are Few-Shot Learners
[8] Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance




