
We’re excited to introduce major improvements to our API’s inference latency, with the majority of audio files now completing in well under 45 seconds regardless of audio duration, and with a Real-Time-Factor (RTF) as low as .008x.
Since AssemblyAI’s founding, we’ve been focused on democratizing fast, accurate, and highly capable Speech AI models to help developers build amazing new human-computer interfaces around voice data. We’re excited about today’s improvements and what they will help developers build.
To put an RTF of .008x into perspective, this means you can now convert a:
- 1h3min (75MB) meeting in 35 seconds
- 3h15min (191MB) podcast in 133 seconds
- 8h21min (464MB) video course in 300 seconds
We’ve also compared our API’s turnaround time for speech-to-text to several other popular models and APIs below.
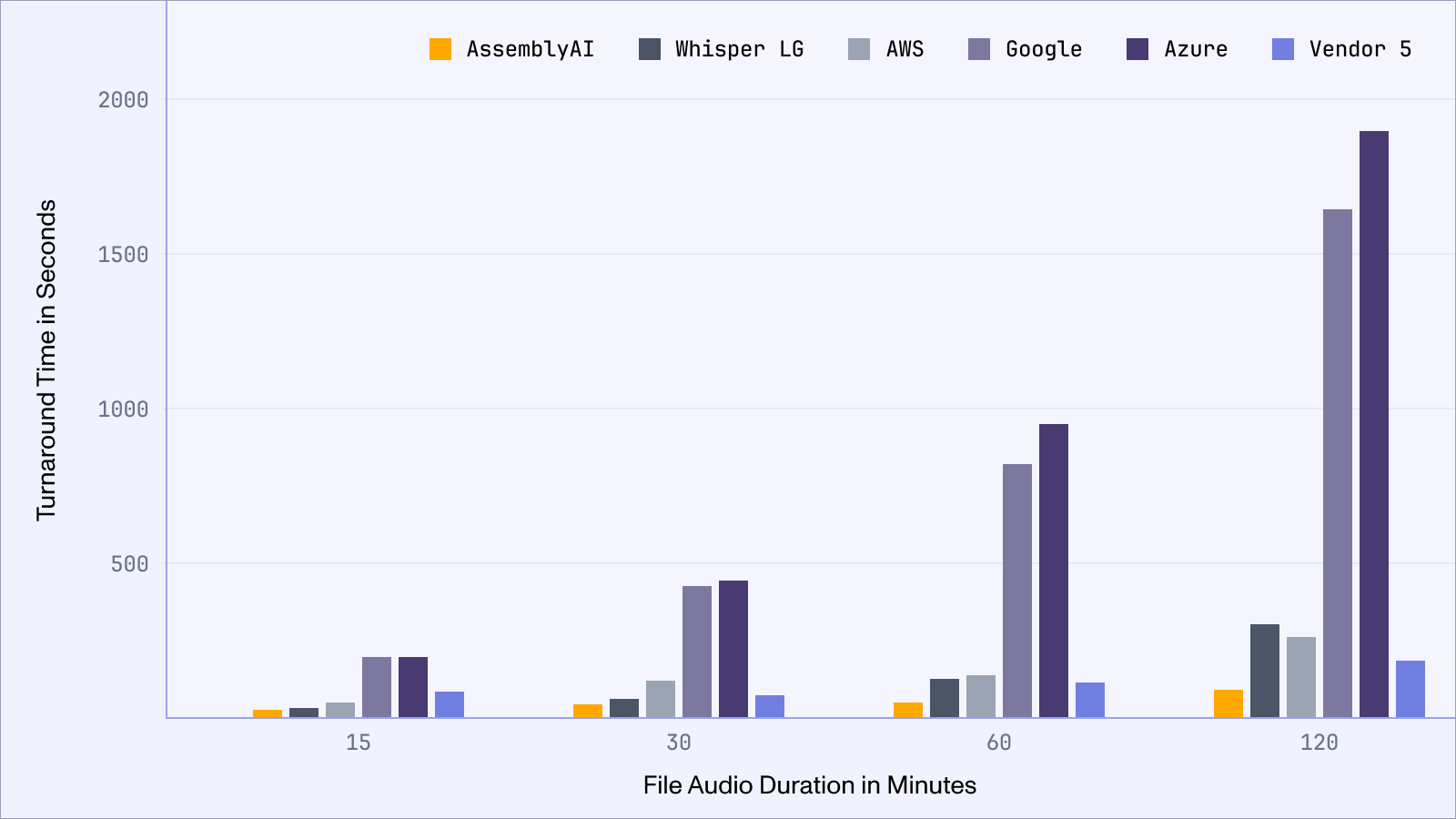
This boost in speed and turnaround time comes at no degradation to our industry-leading accuracy and is a result of our ongoing efforts in driving efficiency for inference workloads at large scale. With this change, we are excited to pass new cost-savings to our users with new, lower pricing for our async and real-time speech-to-text models starting today. The reduced pricing enables developers and organizations to build with our Speech AI models more easily, and continue to experience industry-leading accuracy.

Our fast turnaround times stem from the efficiencies that our incredible research and engineering teams drive at every level of our inference pipeline including optimized model compilation, intelligent mini batching, hardware parallelization, and optimized serving infrastructure. Here’s a look at how our batching system intelligently aggregates work across the requests to our API.
Intelligent Mini Batching
Our API operates at an extremely large scale, running on thousands of GPUs and handling tens of millions of calls per day. By aggregating all of the processing that needs to be done and distributing this work over our inference hardware intelligently, we are able to maximize hardware utilization across our entire inference cluster. Our intelligent mini batching system handles this aggregation and distribution of inference workloads.
Every Speech Recognition model has a context window, which defines the length of audio the model can process at once. For example, Conformer-2 has a 25 second context window, which means it transcribes 25 second segments of speech at a time.
To process a 75 second audio file, Conformer-2 processes three of these 25 second context windows, as well as two additional 25 second “peek” context windows of overlap for increased accuracy. When the file is processed, all 5 of these windows are passed into a GPU to be processed at once in parallel.

While this is traditionally how files are processed with AI models, it is not always optimally efficient for large-scale workloads. Every GPU has a set amount of memory, which defines the total amount of data it can process at once. The GPU in the example above has enough memory to fit 5 context windows, which perfectly fits a 75 second file, but if we instead need to transcribe a 50 second file then there is a significant amount of memory left unused during processing.

If we need to transcribe a file that is longer than 75 seconds, memory will once again be left unused during processing. In this case, since the file is too big to be processed by one GPU, it is processed by two GPUs concurrently (“hardware parallelization”) and the resulting partial transcripts are concatenated. Once again, memory is left unused on the second GPU.
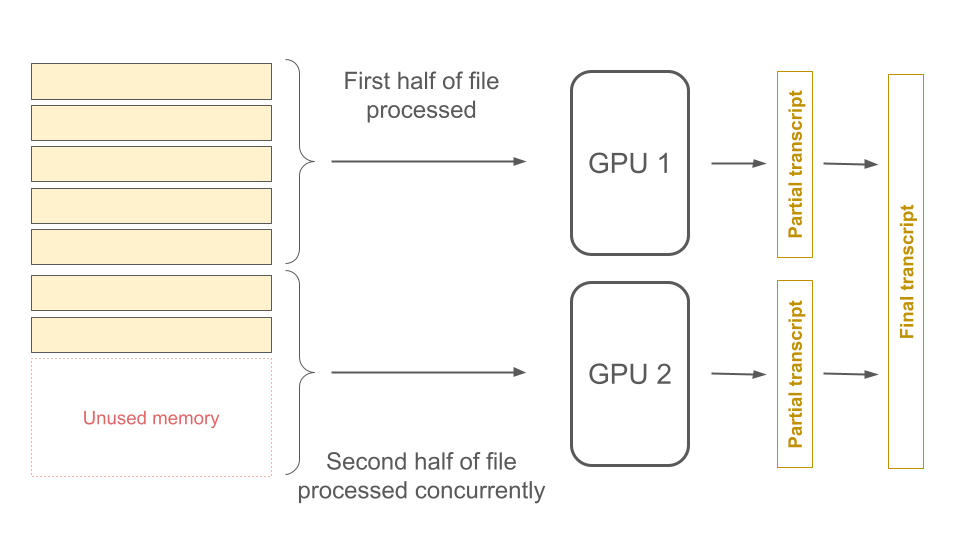
Our intelligent mini batching resolves this issue in order to efficiently process many files at once. Any time there is unused memory on one of our thousands of production GPUs, a queued file fills that available space to begin processing, even if only part of the file can fit into the unused memory. That is, within our serving infrastructure, batches of files processed by our production GPUs are not delineated by file boundaries, enabling maximum hardware utilization to efficiently process huge quantities of files quickly and without any sacrifice in transcript accuracy.
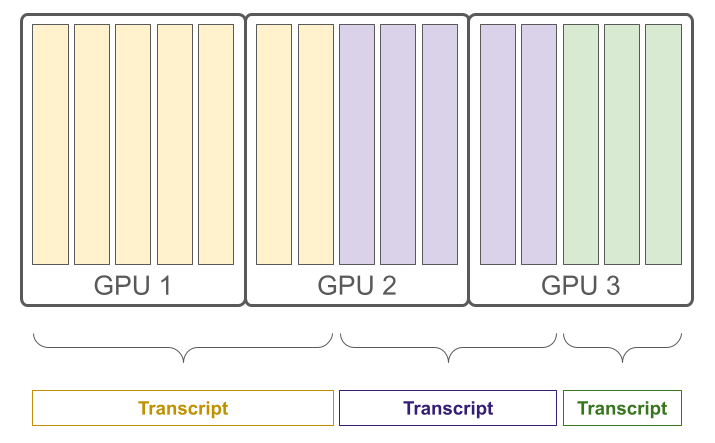
Our intelligent mini batching and hardware parallelization together allow us to maximize our hardware utilization and increase our raw throughput, contributing to the efficiency of our inference pipeline in processing the tens of millions of files sent to our API every day.
Faster turnaround times and lower costs for users
As part of the ongoing work to optimize our inference pipeline, we’ve lowered our pricing to pass along these new economies of scale to our users.
You can now access our Speech AI models with the below pricing:
- Async Speech-to-Text for $0.37 per hour (previously $0.65)
- Real-time Speech-to-Text for $0.47 per hour (previously $0.75)
We’re extremely excited about these updates putting near-human level AI speech-to-text in the hands of developers and organizations for orders of magnitude lower cost than humans, as we illustrate in the chart below, and the new use cases that will quickly become possible:
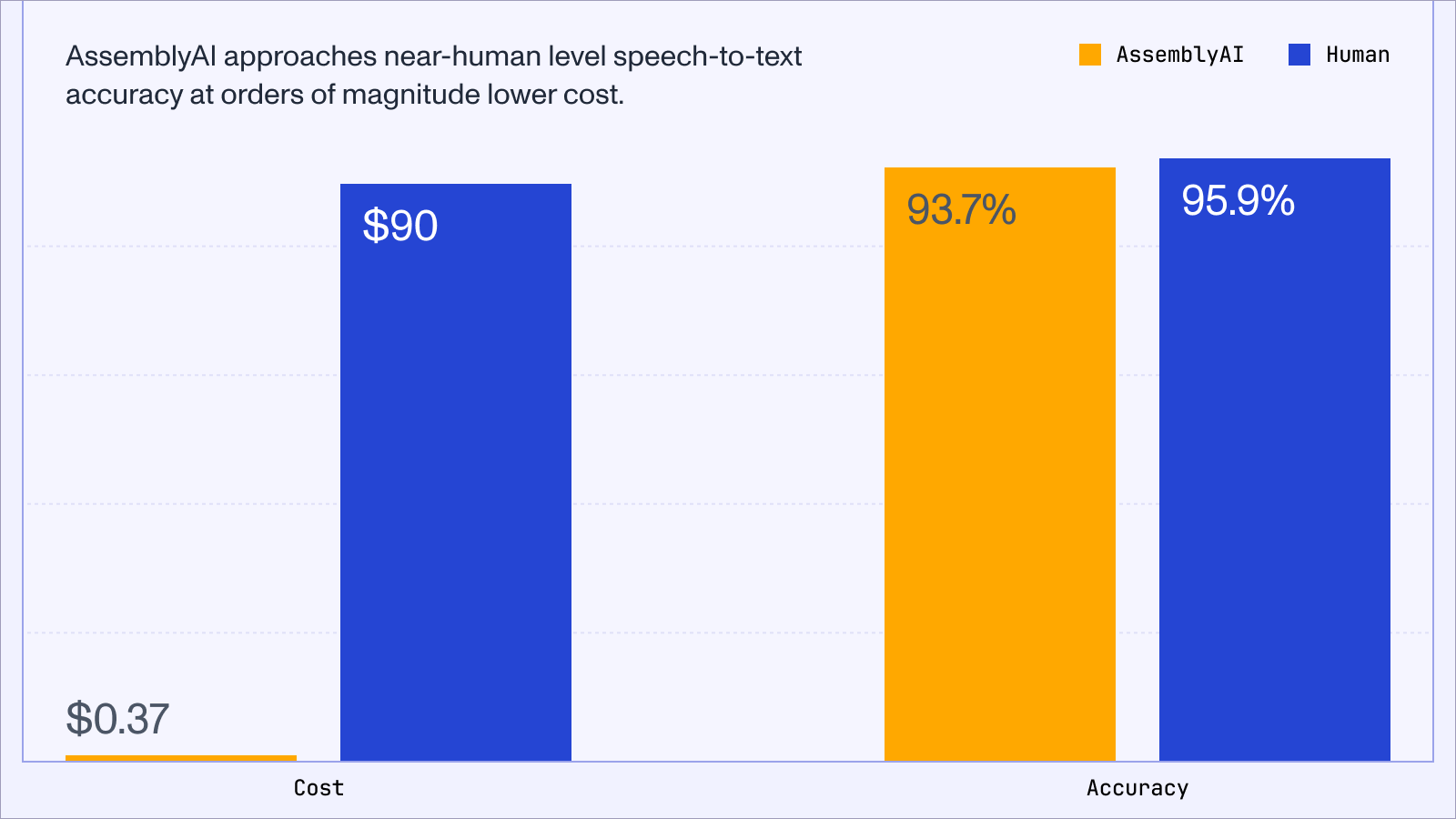
We’ve also reduced our pricing for the following Audio Intelligence models: Key Phrases, Sentiment Analysis, Summarization, PII Audio Redaction, PII Redaction, Auto Chapters, Entity Detection, Content Moderation, and Topic Detection. You can view the complete list of pricing updates on our Pricing page.
Finally, we are increasing the default concurrency limits for both our async and real-time services. These limits are increasing to 200 for async and 100 for real-time, up from the previous 32. This means that you can now have 200 files processing in parallel at once with our async API, and 100 concurrent real-time sessions open at once when using our real-time API. This change will be rolled out over the next couple of days.
This is just the start of what we plan to release over the next few months, and we're excited to see what developers and organizations continue to build with AssemblyAI. To stay up to date with the latest improvements, visit our Changelog and subscribe to our newsletter.




