
Retrieval Augmented Generation (RAG) is a method to augment the relevance and transparency of Large Language Model (LLM) responses. In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. RAG therefore helps improve the relevancy of responses by including pertinent information in the context, and also improves transparency by letting the LLM reference and cite source documents.
While RAG is an increasingly popular method, it requires textual documents as references and cannot directly use the wealth of audio data that many organizations have or that is available online, like meeting recordings, lectures, webinars, and more.
In this tutorial, we will demonstrate how to perform Retrieval Augmented Generation with audio data by leveraging AssemblyAI’s document loader for LangChain, a popular framework that provides building blocks for LLM-based applications, using Chroma as the vector database to store our document embeddings.
The source code for this tutorial can be found in this repo, and you can watch a video version of this tutorial on YouTube.
Getting started
To follow this tutorial, you’ll need an AssemblyAI API key. You can get one for free here if you don’t already have one. Additionally, we’ll be using GPT 3.5 for this tutorial, so you’ll need an OpenAI API key as well - sign up here if you don’t have one already.
Setting up the virtual environment
In a terminal, create a directory for this project and navigate into it:
mkdir ragaudio && cd ragaudioNow, enter the following command to create a virtual environment called venv
python -m venv venvNext, activate the environment. If you’re on MacOS/Linux, enter
source ./venv/bin/activateIf you are on Windows, enter
.\venv\Scripts\activate.batNext, install the libraries we’ll need for this tutorial:
pip install assemblyai langchain openai python-dotenv chromadb sentence-transformersSetting up the environment file
We’ll use python-dotenv to load environment variables for our project. In order to do so, we’ll need to store our environment variables in a file that the package can read. In your project directory, create a file called .env and paste your API keys as the values for the corresponding environment variables:
ASSEMBLYAI_API_KEY=your-key-here
OPENAI_API_KEY=your-key-hereNote, it is extremely important to not share this file or check it into source control. Anybody who has access to these keys can use your respective accounts, so it is a good idea to create a .gitignore file to make sure that this does not accidentally happen. Additionally, we can exclude the virtual environment from source control. The .gitignore file should therefore contain the following lines:
.env
venvWriting the application
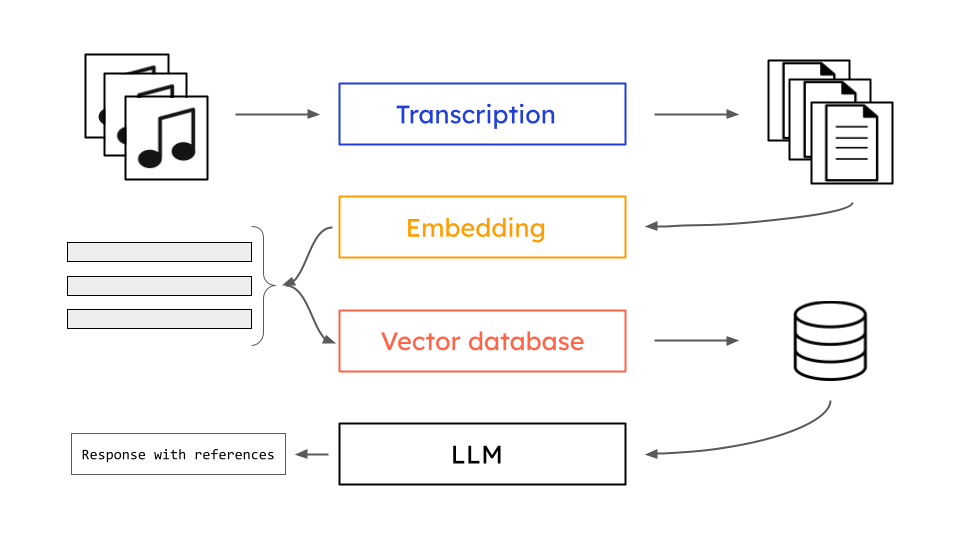
Now we’re ready to write the application. Overall, the application will work as follows:
- First, we will load our documents using AssemblyAI’s document loader for LangChain
- Next, we will split these documents in order to have smaller chunks that can be retrieved by LangChain during RAG
- We will then embed these chunks with HuggingFace, yielding one vector for each chunk
- After that, we will store these embeddings in a Chroma vector database
- Finally, we will use LangChain’s built in QA chain to write a simple loop that lets us query OpenAI’s GPT 3.5. We will be shown the answer along with the texts retrieved for RAG when generating the answer
We can see this process pictorially as below:

Imports and environment variables
Open a new file in your project directory called main.py. First, we’ll add all imports required for this project. Additionally, we'll use the load_dotenv() function in order to load the contents of our .env file as environment variables.
from dotenv import load_dotenv
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import AssemblyAIAudioTranscriptLoader
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
load_dotenv()Loading the documents
The AssemblyAIAudioTranscriptLoader allows us to load audio files, local or remote, into LangChain applications. In this example, we will use several audio files from LangChain’s webinar series on YouTube, but feel free to use any files you’d like. Note that remote files must be publicly accessible for the loader to work properly.
Since the AssemblyAIAudioTranscriptLoader can only accept one input at a time, we write a small function that wraps a for loop to load each audio file, printing the url each time a new file begins loading. We then simply pass in our list of URLs to generate a list of LangChain Documents:
URLs = [
"https://storage.googleapis.com/aai-web-samples/langchain_agents_webinar.opus",
"https://storage.googleapis.com/aai-web-samples/langchain_document_qna_webinar.opus",
"https://storage.googleapis.com/aai-web-samples/langchain_retrieval_webinar.opus"
]
def create_docs(urls_list):
l = []
for url in urls_list:
print(f'Transcribing {url}')
l.append(AssemblyAIAudioTranscriptLoader(file_path=url).load()[0])
return l
docs = create_docs(URLs)Document splitting and metadata
Now, we need code that can split all of the Documents into chunks by using a RecursiveCharacterTextSplitter:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(docs)Next, set the metadata for each chunk to contain only its source (i.e. filepath/URL). The AssemblyAIAudioTranscriptLoader returns a large amount of metadata about the transcribed audio file, and some of the types are incompatible with the Chroma database that we will use later, so for the sake of simplicity we strip off everything extraneous that we don’t need for this tutorial.
for text in texts:
text.metadata = {"audio_url": text.metadata["audio_url"]}Embed texts
Next up we create embeddings for all of our texts and load them into a Chroma vector database. For this, we write a make_embedder function that wraps the process for instantiating an embedding model from HuggingFace. Then we simply pass this object and our texts into the function to create a Chroma vector database.
def make_embedder():
model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
return HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
hf = make_embedder()
db = Chroma.from_documents(texts, hf)Create the Q&A chain
Finally, we create the Q&A chain that ties all of these components together. Write a function make_qa_chain that returns a RetrievalQA chain with GPT-3.5 as the LLM and Chroma as the retriever vector database. The RetrievalQA chain will also return source documents used as references during RAG.
def make_qa_chain():
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
return RetrievalQA.from_chain_type(
llm,
retriever=db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}),
return_source_documents=True
)Then we write a loop to take in questions, pass them into the Q&A chain, and display the answers/sources:
print('\nEnter `e` to exit')
qa_chain = make_qa_chain()
while True:
q = input('enter your question: ')
if q == 'e':
break
result = qa_chain({"query": q})
print(f"Q: {result['query'].strip()}")
print(f"A: {result['result'].strip()}\n")
print("SOURCES:")
for idx, elt in enumerate(result['source_documents']):
print(f" Source {idx}:")
print(f" Filepath: {elt.metadata['audio_url']}")
print(f" Contents: {elt.page_content}")
print('\n')You can find all of the source code for this project in this repository.
Running the application
To run the app, execute python main.py or python3 main.py from the project directory with your virtual environment activated. The transcription of the file (i.e. loading with the AssemblyAI loader) may take several minutes depending on the lengths of the files. To speed this up, you can consider extending the application to do this in parallel so each file does not have to be transcribed before starting the transcription of the next file.
Note
If you receive an error huggingface/tokenizers: The current process just got forked, you can add TOKENIZERS_PARALLELISM=false to your .env file. See here for additional details.
Simply enter a question into the terminal and a response will be generated, along with a list of sources (with location and source content).
Example
Q: What is retrieval augmented generation (RAG)?
A: Retrieval augmented generation (RAG) is a method that combines information retrieval and language generation techniques. It involves using a retrieval system, such as a search engine or a vector database, to find relevant context or documents. This retrieved information is then used to augment a language model prompt or input. The language model generates a response or output based on both the retrieved context and its own parametric weights. RAG is used to address limitations of language models, such as token length restrictions and the need for additional data sources. It can help reduce hallucinations and improve the performance of language generation systems.
SOURCES:
Source 0:
Filepath: https://storage.googleapis.com/aai-web-samples/langchain_retrieval_webinar.opus
Contents: types of retrieval methods to see how they compare and how they perform. So I'll dive into that in the context of doing retrieval for generation, we want to find relevant context, and we want to stuff that into a prompt or a language model prompt. And we want to use some kind of information retrieval system, right? And this might be a search engine, might be a vector database, SQL, graph, hyperdb, NumPy array, whatever. And that's why we love the new abstraction in Lang train around retrievers. And some of the motivation is basically these language models, they are large, they are expensive, and they have limited token lengths. So if you cross those multiple different dimensions, that's the kind of thing that we want to address by retrieval augmenting. And of course, there's a lot of knowledge in the parametric weights of the language models, and we want to augment that with our private data or data that the model hasn't been really trained on. And as Harrison said, last webinar was
Source 1:
Filepath: https://storage.googleapis.com/aai-web-samples/langchain_retrieval_webinar.opus
Contents: about reducing hallucinations. Retrieval improves on that, but it doesn't, my experience eliminate it entirely, but it does reduce satellites and also allows you to scale to larger data sets than just whatever token length limitation your language model of reference is at. So retrieval augmentation is not really a brand new concept, as far as I know. It was introduced actually back in 2020 at Nearips, where researchers from Meta did build a system where they will retrieve, and then they would augment sequence to sequence language model and generate the answer for open domain question answering. And just before that, the state of the art and open domain question answering was extractive question answering, where you would retrieve with a retriever, and then you would extract or predict the best answer span in the retrieved text. So it wouldn't actually generate text, it would just pick out the most probable answer from the retrieve context. But obviously now we have much larger models,
Source 2:
Filepath: https://storage.googleapis.com/aai-web-samples/langchain_retrieval_webinar.opus
Contents: in, kind of what people familiar with LangCchain might recognize. So I should be sharing my screen now. This is from a blog post we did in February. The main usage of retrieval and langchain is basically to enable connecting your data with language models. And so the way that we've traditionally done this is we've done everything largely based on kind of like embeddings and vectors. And we've taken documents, split them into chunks, created embeddings for those chunks, and then stuffed them in a vector store. And then we've used that to create a chat bot where you basically have a question that comes in, you look up in the vector store relevant pieces of text, you then pass that along with the original question into a language model, and it grounds its answer in the documents that it's passed in. We discussed hallucinations last week, and the retrieval augmented generation was one of the most popular methods for reducing hallucinations. And a lot of the comments on that webinar was
Final words
In this tutorial, we learned how to combine several tools to perform Retrieval Augmented Generation (RAG) with audio data. In particular, we used the LangChain framework to load audio files with AssemblyAI, embed the files with HuggingFace into a Chroma vector database, and then perform queries with GPT 3.5.
For more tutorials like this, check out the tutorials section of our blog. Alternatively, check out our YouTube channel for other learning resources on Machine Learning. Finally, feel free to follow us on Twitter in order to stay in the loop when we release new content.




