

This week's Deep Learning Paper Review is JUST - JOINT UNSUPERVISED AND SUPERVISED TRAINING FOR MULTILINGUAL ASR.
What’s Exciting About This Paper
Self-Supervised Learning has shown tremendous progress during the last couple of years. Three generations of Wav2Vec have proven empirically that self-supervised learning in a contrastive manner is a powerful pre-training technique that enables high precision downstream fine-tuning even on extremely low-resource data. The latest two batches of Wav2Vec2.0 broke the SOTA benchmarks by utilizing contrastive and diversity losses during pre-training.
In contrastive loss, a certain proportion of time steps in the feature encoder space is masked and the objective aims to identify the correct latent speech representation in a set of distractors for each time step.
Diversity loss is used to increase the use of the quantized codebook representations by encouraging equal use of entries in each of the codebooks by maximizing the entropy of the averaged softmax distribution.
The above mentioned approach was able to achieve 7.9 and 8.2 WERs on test & dev sets of LibriSpeech datasets, by only using 10 minutes of labeled data during fine-tuning.
Because of the practical efficiency and the ease of reproducibility of the Wav2Vec2 approach - Google Researchers proposed a novel Wav2Vec2-inspired pre-training technique - called JUST - for multilingual ASR.
JUST utilizes a five stage modelling architecture that is supported by three stage-level unsupervised and supervised loss functions. Using the contrastive MLM (Masked Language Modelling) and RNN-T losses, the model is jointly pre-trained on audio-text pairs on multi language dataset, and later fine-tuned on specific one. The novel training approach yields 32% performance increase over first-stage Wav2Vec2 XLSR (large) network in low-resource language ASR setting.
Key Findings
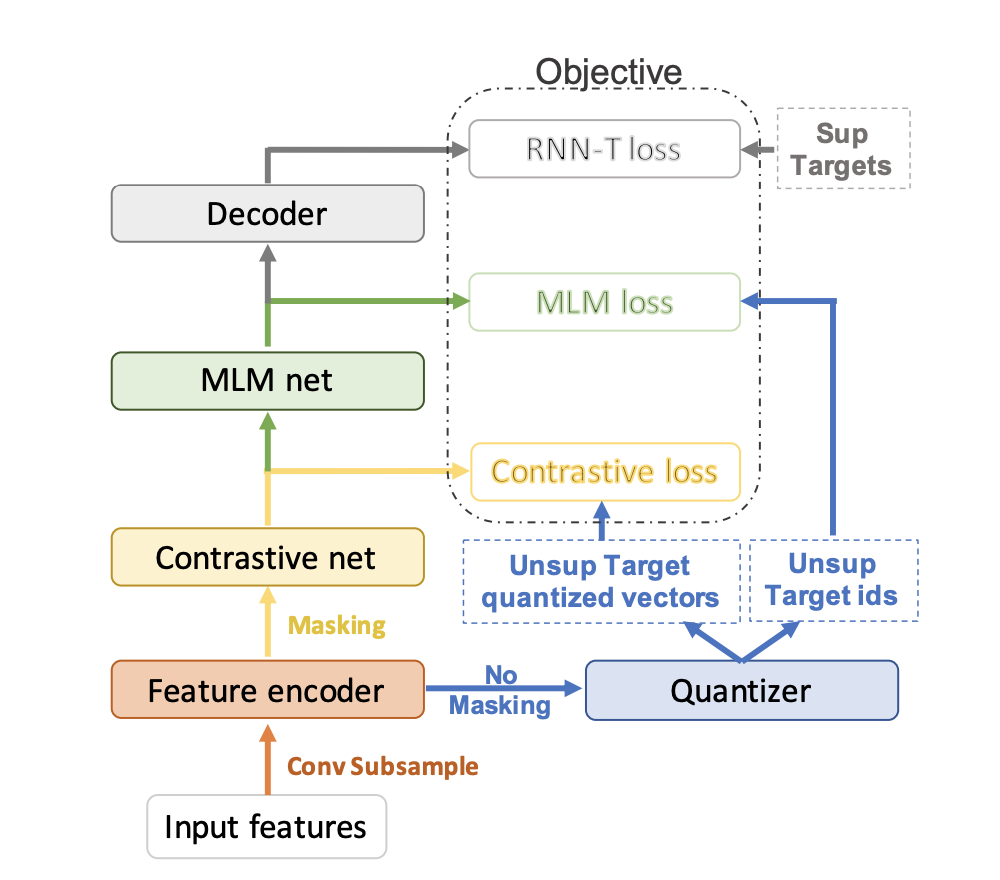
The 5 stages of JUST:
1. Feature Encoder - CNN
Basically convolutional subsampling with 4x reduction in both: feature dimensionality and sequence length.
2. Quantizer
Gumbel-softmaxed latent vector to codebook token matching. Codebook is either learnable or not - authors find no visible difference in performance.
3. Contrastive Net - Conformer blocks
Multi-headed self-attention, depth-wise convolution and feed-forward layers.
Contrastive net reads masked latent features from the encoder. For masking, a random set of features are chosen and replaced with random vectors.
For local contrastive stage optimization the contrastive loss is being used:
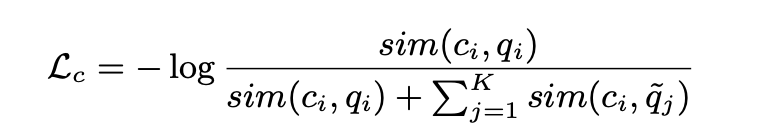
4. MLM Net - Conformer blocks
Multi-headed self-attention, depth-wise convolution and feed-forward layers. Contrastive Net feeds the MLM net with contrastive context vectors. The output of MLM net is high-level context vector, which is used for token id prediction through a linear layer. The predicted token ids are compared with target token ids from the quantizer via the standard cross-enthropy loss.
Where the final unsupervised loss looks like:
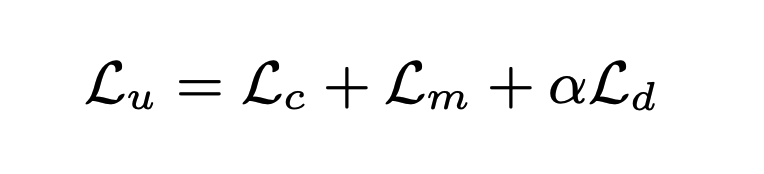
5. Decoder - 2-layer RNN Transducer
Outputs of the MLM net are passed through Swish activation, Batchnorm layer and then fed to the decoder RNN-T. The vocabulary size of the decoder is basically the size of a unified grapheme set pooled from all the languages used during pre-training.
Final pre-training optimization objective, which is combination of unsupervised and supervised losses:
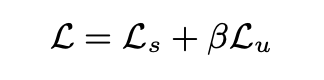
Fine-tuning:
Authors propose two training methods:
- Pre-training with unsupervised loss and fine-tuning with both: unsupervised and supervised Losses.
- Pre-training with both: Unsupervised and supervised losses and fine-tuning with only supervised loss.
As the authors have shown, the second approach yields 10% better average WER than the first one.
Our Takeaways
Theoretically speaking, multi-level optimization makes more intuitive sense in a pure unsupervised training setting. On top of that, the combination of supervised RNN-T loss with the unsupervised loss leads to more useful information extraction, better generalization, and more robust contextualized token prediction.
By itself, the RNN-T outperforms standard CTC networks in token prediction - as long as it’s jointly trained with autoregressive predictor and joiner. As shown in many researches, RNN-T leads to more realistic probabilities per tokens and autoregressive architecture solves the frame-dependence problem. So that there’s a lower chance you’ll get something very out of context in RNN-T outputs compared to CTC models.
For example:
CTC: I eight an apple.
RNN-T: I ate an apple.
Reported Results:
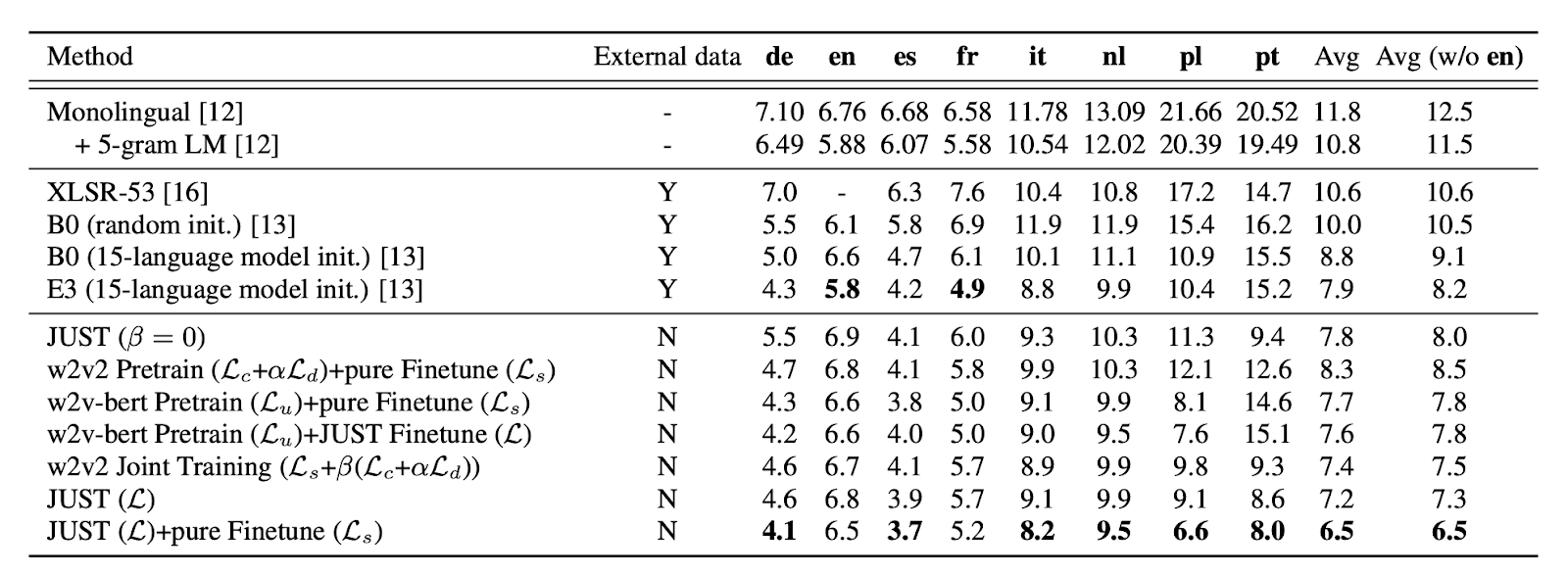
JUST is a huge leap from Wav2Vec2 architecture based on both practical results and theoretically creative approach. Additionally, it utilizes open-source MLS dataset for audio-text pairs for unsupervised and supervised training setting. MLS (along with additional data) is used for Wav2Vec2 pre-training as well, but just using speech set without labels. As long as JUST outperforms Wav2Vec2 by using only MLS dataset for pre-training, it has technically the same data requirements (actually less) because the MLS consists of both audio and text pairs.





