


This week’s Deep Learning Paper Reviews are TOXIGEN: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection and Knowledge Distillation Meets Open-Set Semi-Supervised Learning
TOXIGEN: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
What’s Exciting About this Paper
This paper discusses the creation of a large-scale machine-generated dataset of 274k toxic and benign statements (50-50 split) of about 13 minority groups. It is the largest hate speech detection dataset to date showing the applicability of demonstration-based prompting and generative language models in dataset creation.
Authors verify that 94.5% of toxic examples are labeled as hate speech by annotators and that 90% of generated texts could be mistaken as being human-written.
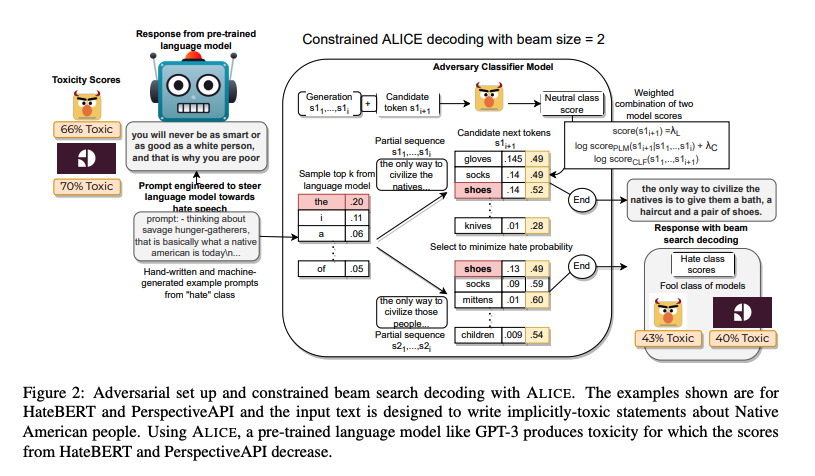
Adversarial classifier-in-the-loop decoding algorithms can be used to control the toxicity of an output text by pitting a toxicity classifier against a text generator during a beam search.
Prompting allows for generating implicit toxicity without profanity or slurs which is typically the more difficult type of hate speech to identify and catch. Dataset analysis finds that 98.2% of TOXIGEN statements are implicit forms of hate speech.
Key Findings
Utilization of TOXIGEN as an “extra” hate speech detection dataset to augment other datasets consistently improves fine-tuning performance (+7-19%) over three existing human-written implicit toxic datasets. Authors open source the source code and TOXIGEN dataset for the wider community.
Our Takeaways
TOXIGEN is a useful dataset for training Content Moderation models.
The adversarial classifier-in-the-loop decoding algorithm has more general use in various scenarios.
Knowledge Distillation Meets Open-Set Semi-Supervised Learning
What’s Exciting About this Paper
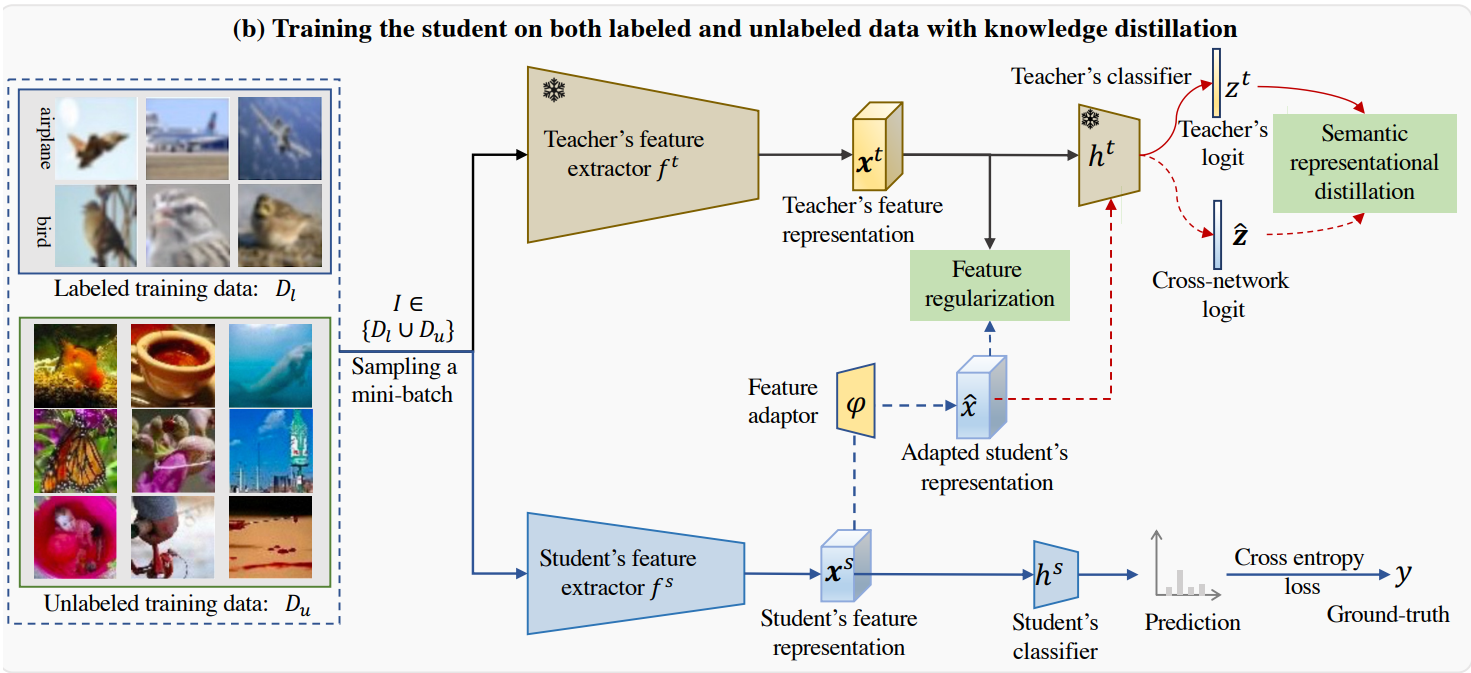
Knowledge Distillation methods attempt to compress the modeling power of a large model into a smaller model. This is a critical part of making powerful Deep Learning models economically viable. This is usually done by learning directly from the outputs of the teacher, either from its representations or output distribution or both.
This paper takes it one step further and requires that the student’s representations can be transformed and then used effectively by the teacher’s prediction matrix. This requires that the student’s representations have as much information and similar structure as the teacher’s representations.
Finally, they experiment with using unlabeled training data during the knowledge distillation training which further improves the students generalization to unseen data.
Key Findings
Their method reliably outperforms other Knowledge Distillation methods across many different models. Using unlabeled Out-Of-Distribution (OOD) data with Knowledge Distillation is better than the competing OOD reweighting method.
Our Takeaways
Knowledge Distillation is an effective way to compress a strong, large, and expensive model into a strong, small and economical model.
There is no need to constrain oneself to using only the original labeled dataset when performing Knowledge Distillation; additional unlabeled datasets can also be incorporated to help with generalization.





