

This week’s AI Research Review is Git Re-Basin: Merging Models Modulo Permutation Symmetries.
Git Re-Basin: Merging Models Modulo Permutation Symmetries
What’s Exciting About this Paper
In this paper, the authors show that the loss landscape of a wide enough neural network has essentially a single basin. This leads to many permutations of the same model weights calculating the same function.
Key Findings
The linear interpolation between model weights is an emergent behavior of SGD (stochastic gradient descent), not a model property.
Two models (with the same architecture), trained on two different datasets, with different sets of parameters such as learning rate, dropout, etc, can be merged with no cost to the loss.
The authors have proposed three methods to find mappings between neurons of different models.
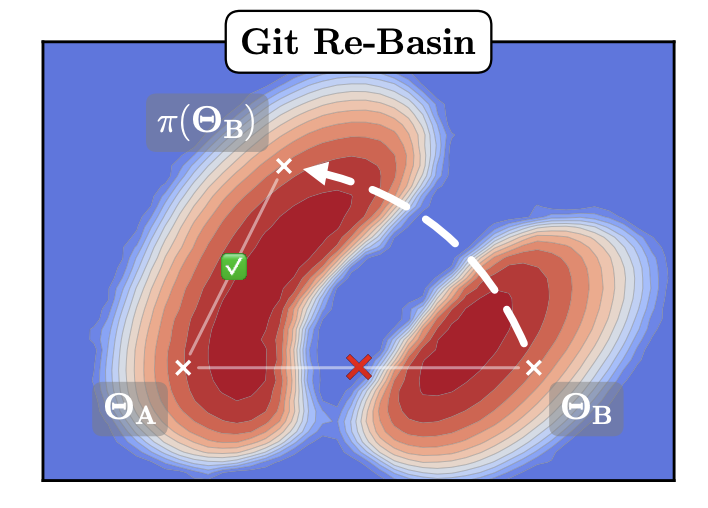
The authors discuss three methods for selecting permutations:
- Matching activations: Two models must learn similar features in order to accomplish the same task - it can be assumed that in such a case, there will be a linear relation between the activations.
- Matching weights: Instead of the activations, inspect model weights directly.
- Learning permutations with a straight-through estimator
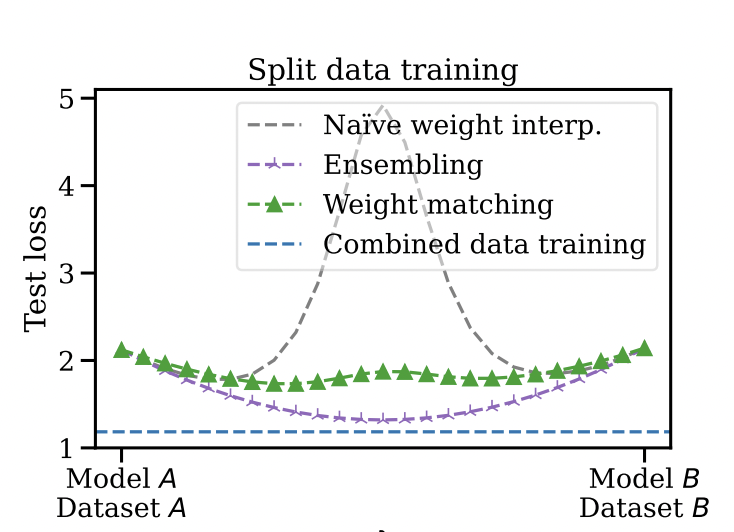
Our Takeaways
The findings in this paper could potentially help in distributed model training.
It also introduces new avenues for federated learning - a model can be trained on a dataset without compromising on privacy and then be merged with an existing model to enhance performance.
Finally, the paper also offers new avenues for model optimization - different models trained on different data, converging to nearly the same basin, suggests the presence of a global minima.







