

Generative AI has made great strides in the language domain. OpenAI’s ChatGPT can have context-relevant conversations, even helping with things like debugging code (or generating code from scratch).
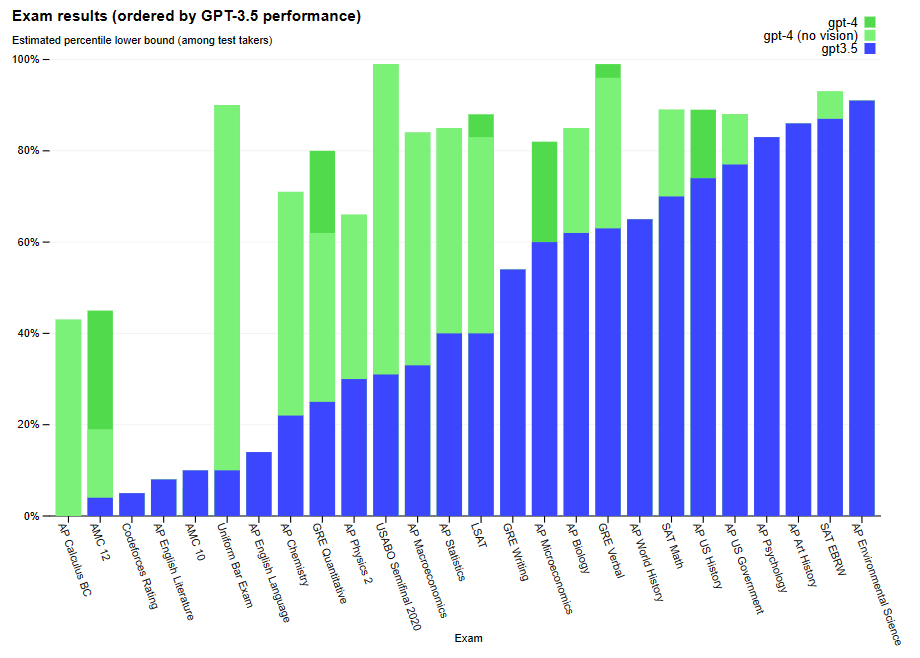
More recently, the Large Language Model GPT-4 has hit the scene and made ripples for its reported performance, reaching the 90th percentile of human test takers on the Uniform BAR Exam, which is an exam in the United States that is required to become a certified lawyer. It even reaches nearly the 40th percentile on the AP Calculus BC exam, which is a low-level undergraduate-equivalent Calculus exam in the United States.
These Generative AI models are progressively migrating from the ivory tower and finding themselves integrated into our everyday lives through tools like Microsoft’s Copilot. What is behind this recent wave of progress? How do these models actually work, and why are they so capable?
In this article, part of our Everything you need to know about Generative AI series, we will answer these questions and more. This article is designed to help all audiences understand these recent developments and how they find themselves situated in our lives.
We will assume only a basic understanding of AI, so feel free to check out our Introduction to Generative AI if you haven’t already.
What are Language Models?
Many of the advancements in Generative AI on the language front rely on Large Language Models. To understand these models, we must first familiarize ourselves with Language Models in general.
Language Models (LMs) are simply probability distributions over word sequences. They tell us that the word sequence “I am going to the store” is more probable than the word sequence “store the going am to I”, and more probable than the word sequence “jumped scissors bridge to skate elephant”
LMs were traditionally used as parts of other systems. For example, Automatic Speech Recognition (ASR) models like Conformer-1 take in sound waves and produce a transcription of what was said in the audio. Here you can see the transcript for the audio that was automatically generated with Conformer-1.
Transcript
We'll get in a minute, but he is still crying tears of joy. LeBron. I'm sorry, Doris.
No. No worries, Kyrie. LeBron, as soon as that buzzer sounded, your emotions let loose.
Can you describe what you're feeling right now? I set out a goal two years when I came back to bring a championship to the city. I gave everything that I had. I put my heart, my blood, my sweat, my tears to this game.
LMs can be used as part of these ASR systems to score potential outputs. For example, let’s say we put in the below audio wave into an ASR model.
An ASR model will take in this audio wave and process it, eventually passing the processed audio into the Language Model. The Language Model is then used to determine that the input audio wave is more likely to correspond to the word sequence “I saw a beer” than the phonetically-equivalent “eyes awe ab ear”.
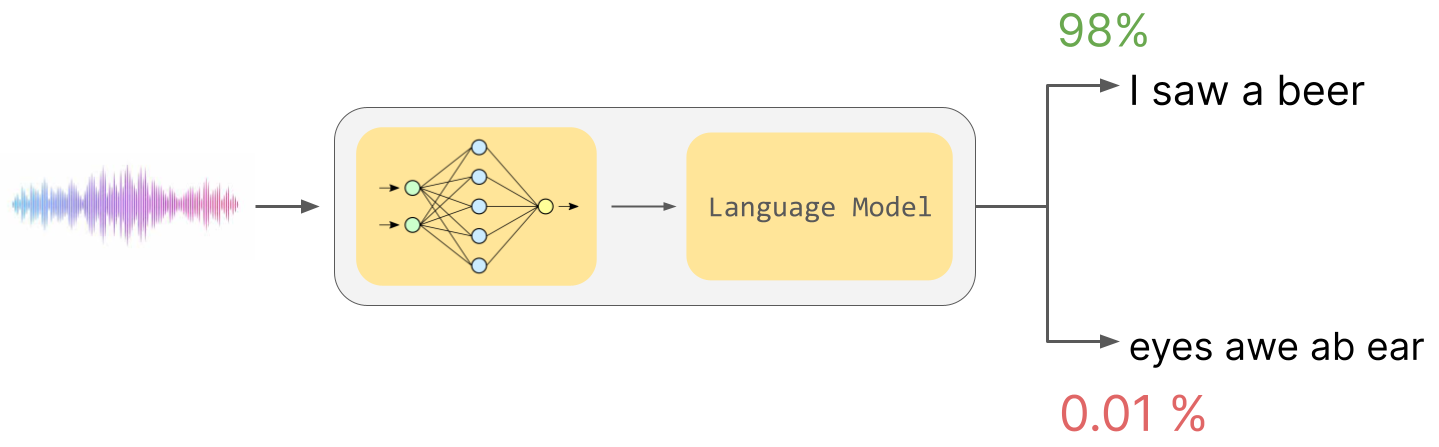
Note that, a priori, there is no way to know this. If you gave an alien a phonetic dictionary of the English language and asked it to transcribe the above audio wave, it would not be able to tell whether “I saw a beer” or “eyes awe ab ear” is more likely.
Since the release of the Language Model GPT-3 in 2020, LMs have been used in isolation to complete tasks on their own, rather than being used as parts of other systems. Let’s take a look at how this works now.
Language Models for Generative AI
Language Models can be used for generative purposes in isolation. In their simplest and most straightforward use case, they can be used to, say, generate the end of a story given its beginning. The below animation demonstrates this process:
Since the Language Model is, by definition, a probability distribution over word sequences, we generate text by simply recursively asking for the most likely next word given all of our previous words. Yes, it really is that simple.
How do Generative AI models for language complete other tasks, like translation or summarization? We’ll take a look at how this works below, but first let’s look at how Language Models are trained, which is critically important to their success.
How are Language Models trained?
This section will be lightly technical, going only into as much detail as is helpful in understanding the modern wave of Generative AI. While we encourage all readers to read this section, even if only for high-level ideas, you can jump down to the next section if you find the content too technical.
From our previous article on Modern Generative AI for images, you may recall that the training procedure for current Generative AI image models was quite complicated. It relied on a complicated mathematical framework and some massaging of the objective in order to reach a tenable problem.
The training process is actually much simpler for Language Models. Let’s first take a look at the process of supervised learning as motivation.
Supervised learning
The term supervised learning describes, at a high-level, one paradigm in which data can be used to train an AI model. In this learning paradigm, we have a set of data, like the images of hand-written digits below:

We can have a human sit down and label each of the images in this dataset. In particular, he will label the entire top row as “zero”, the second row as “one”, and so on. Once we have these labels, we can train a model to predict labels by supplying it with many examples of such inputs and human-generated labels. Once the model is trained, it can be used to predict the labels of new data - a process called “inference”.
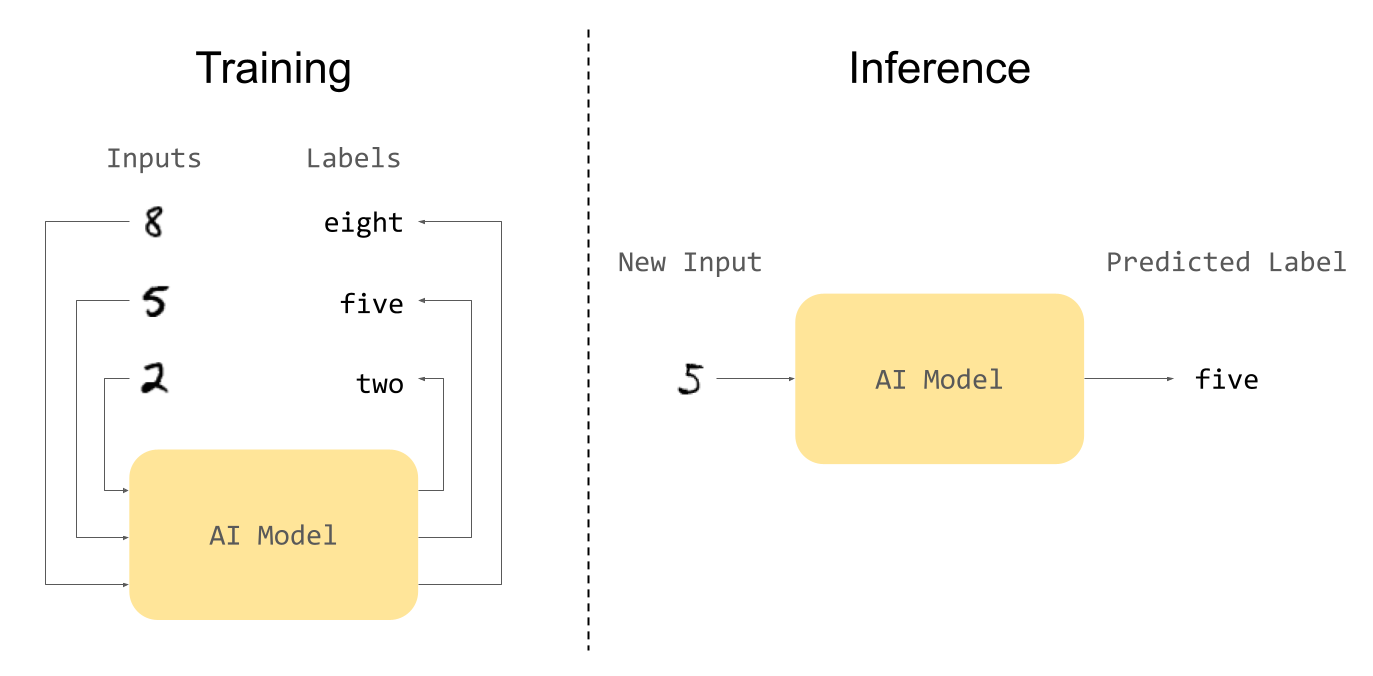
Supervised learning is precisely this process of using many pairs of inputs and labels to train a model. Once trained, the model can be used to automatically e.g. read phone numbers off of a piece of paper, or read a zip code on a letter. In this way, such a model can eliminate the tedious and error-prone process of human data entry.
The supervised learning paradigm is very powerful and can yield high-performing models, but it is very laborious. At some point, humans need to sit down and label all of the training data. As models are scaled up into more powerful versions, they require more data, and scaling this data-labeling procedure is more difficult than scaling the models themselves. Therefore, the data labeling procedure becomes the bottleneck for supervised learning when considering the powerful models that we see today.
Can we do better?
Self-supervised learning
Language Models exploit a different training paradigm called self-supervised learning. Rather than having a dataset with labels created by humans, we automatically “generate” these labels programmatically. How does this work?
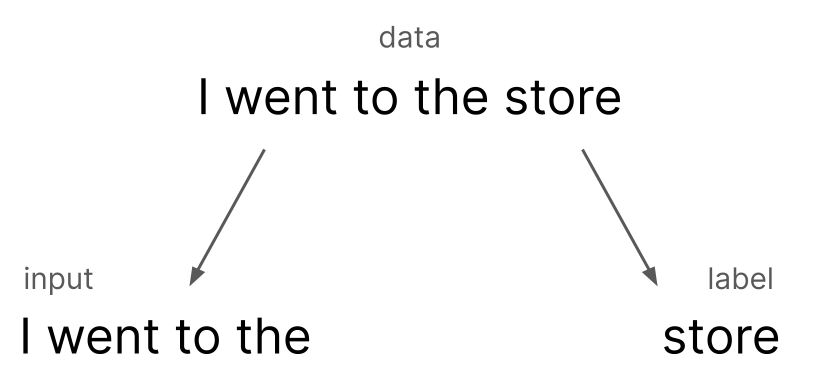
Suppose we want to train an Language Model. To do this, we will need a lot of data, so we’ll scrape the internet for huge amounts of text. Let’s say we scrape the sentence “I went to the store today”. How does the Language Model use this data?
We partition the data into an artificial input and artificial label by simply chopping off the final word, “today”, and making it the label. Remember, we want to train our model to be good at next-word prediction so that we can use it for Generative purposes, as outlined above. So by removing the “next word” and having the model guess it, we can compare the prediction to the actual word that we got from scraping the internet and teach the model to guess the proper word.
In this way we have managed to generate the labels from the data itself, thus removing the data-labeling bottleneck and allowing our dataset to scale up proportionally with our model - a requirement to properly train an LM. This paradigm is called self-supervised training, and is critically important to the success of Large Language Models (LLMs). It is precisely what makes training such large, powerful models feasible.
As interesting as it is to watch LLMs generate the ends of stories as we saw above, they actually have a host of other abilities. They can summarize documents, translate between languages, answer questions, and more. Let’s take a look at these abilities now.
Other abilities of LLMs
As Language Models get bigger and graduate to Large Language Models, they grain a variety of useful abilities. Before we discuss these abilities themselves, let’s take a brief aside to concretely understand what we mean when we say a “bigger” model.
What is a “bigger” model?
From a non-technical perspective, the “size” of a model can be considered the holistic scale at which they operate. “Bigger” models require more memory, more computational power, better hardware, and more data to train. If you would like to skip the slightly technical (but intuitive) explanation below, you can jump down to the next subsection.
Now, what is a “bigger” AI model more concretely? Let’s say we have some data of interest, as depicted below. The graph shows two variables - the y variable on the vertical axis, and the x variable on the horizontal axis. What the variables represent doesn’t really matter - it could be height vs. weight, company size vs. market cap, or something else entirely.
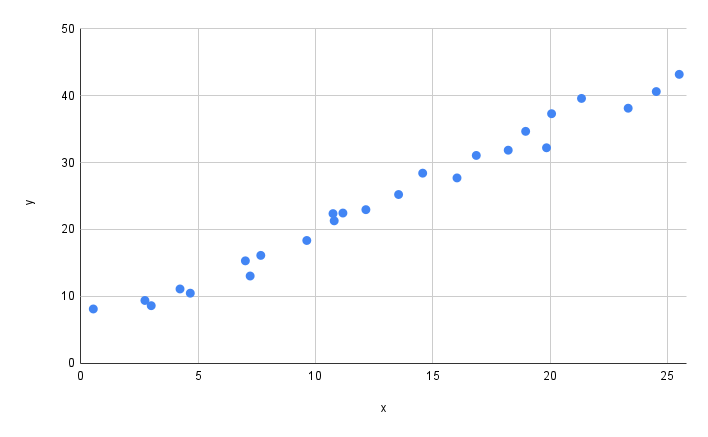
A common desire is to model this data. A model is simply a mathematical relationship between the variables. If we have a good model, we can use it for things like extrapolation and interpolation. To begin, let’s define our mathematical model that relates the values on the x and y axes by a simple proportionality constant, p_1. This value p_1 is called a parameter.
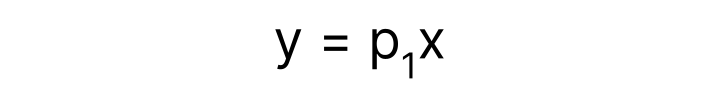
We can use Machine Learning to find the optimal p_1 that best fits this data. Intuitively, we are finding the optimal angle of the line that makes all the points as close to the line (on average) as possible.
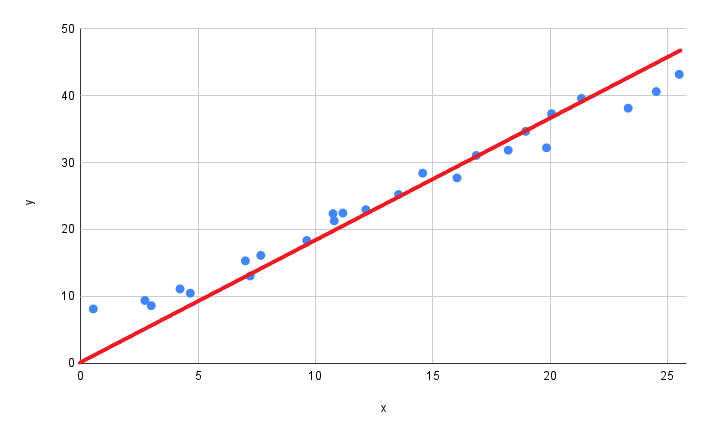
This is a pretty good fit, but we can do better. Let’s update our model, this time adding a new parameter that corresponds to the y intercept. Before, our line had to go through the point (0, 0) where the axes meet. The addition of p_0 removes this requirement.
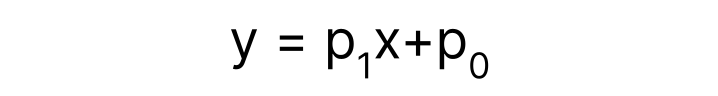
Again, we can use Machine Learning to find an optimal fit, where now we are finding both the angle of the line and the vertical offset of the line that, together, best fit the data.
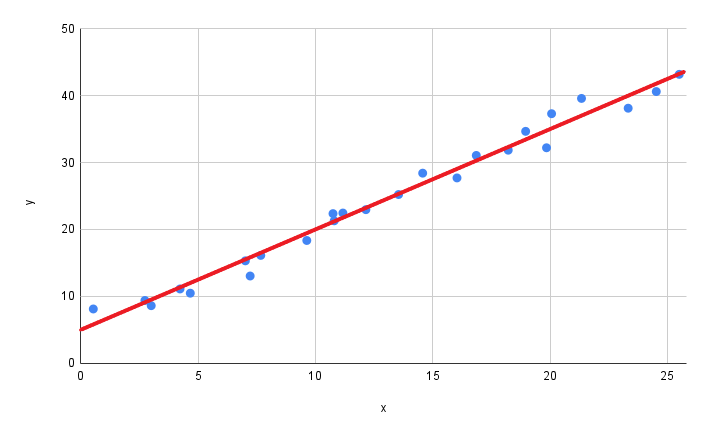
As we can see, the second model has a better fit - it is, on average, closer to the points in our dataset. That means that it will be better, in general, for our tasks of interest (extrapolation, interpolation, etc.). The number of parameters is the “size” of the model. The optimal values of these parameters are found using Machine Learning, and it is precisely their values that determine the performance of a model relative to another in the same family.
As we saw in this example, increasing the size of the model improved its performance. In general, this is true (assuming proper training). Larger models have more “capacity” to solve more complicated problems. In this case, we saw models with one and two parameters, respectively. In the case of GPT-3 (a version of which originally powered ChatGPT), there are 175 billion parameters. If adding just one parameter is enough to improve a model, what are the effects of adding billions?
The abilities of LLMs
Now that we understand what we mean when we say, “bigger” models, we can talk more concretely about the abilities of Large Language Models. As we saw in the above section, Language Models can be used in a straightforward way to generate text via next-word prediction. Interestingly, as they scale up they also gain a variety of other abilities, as shown in the animation below
As LLMs scale, they gain the ability to summarize, translate, and more. How does this work in practice? Previously, we used to have a specific model for summarization, and a specific model for translation, etc.
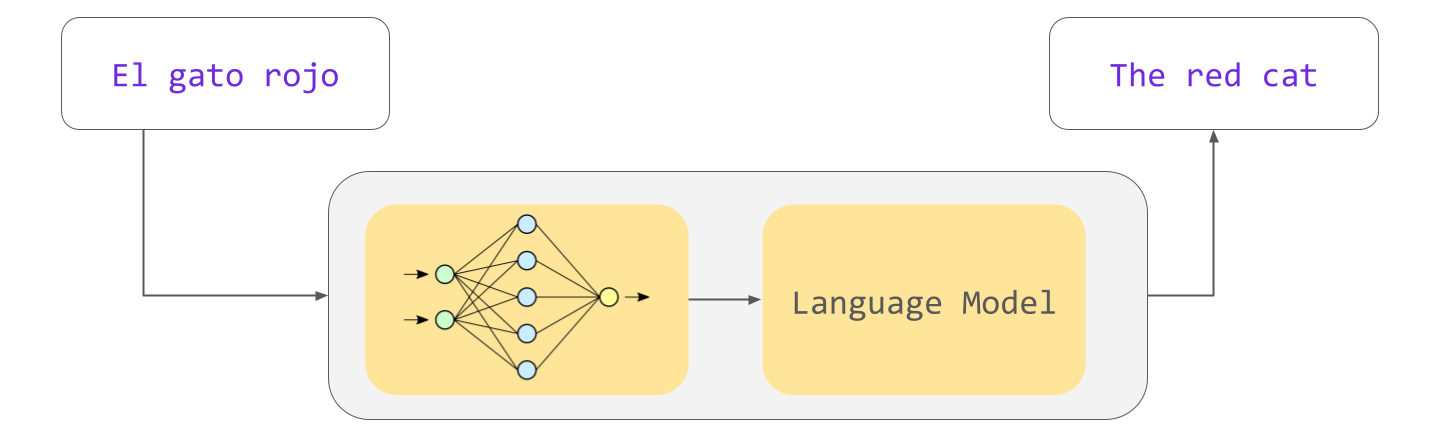
If a single LLM can perform many of these tasks, how does it know which task it is supposed to perform? For example, if we input a page of Spanish text into an LLM, how does it know if it should summarize the page (in Spanish) or translate it to English?
As it turns out, you literally just tell the model. You literally input into the model the string 'Translate this from Spanish to English: “El gato rojo" ' and it will output the translation.

You are conditioning on the task in natural language through the input. Interestingly, the manner in which LLMs gain these abilities is not smooth. Indeed, steady increases in performance are coupled with sudden critical thresholds, at which these abilities appear to emerge. This is a very interesting phenomenon that is not within the purview of this article, but interested readers can check out our dedicated piece on the Emergent Abilities of Large Language Models.
What about ChatGPT?
LLMs as discussed above are great for obtaining answers for specific queries, but what about models like ChatGPT? ChatGPT is a conversational model that can have human-like conversations, seemingly “remembering” what has already been discussed in the conversation and providing relevant answers in ways that humans find useful. ChatGPT differs from a standard Language Model by incorporating human feedback into its training process.
In particular, the unique feature that sets ChatGPT apart from many other LLMs is the implementation of a technique called Reinforcement Learning from Human Feedback (RLHF). This method enhances the conversational capabilities of the model while simultaneously addressing a wide range of safety issues associated with general purpose conversational chatbots. Through RLHF, ChatGPT can learn and align more closely with human values and preferences, enabling it to generate more engaging and accurate responses.
At a high level, RLHF works by combining a baseline LLM with a secondary model, called reward model. The reward model's role is to determine which kind of responses a human would prefer within a given list of possibilities. It assigns a numerical score to a language model’s response to a given request or prompt, which reflects the degree of preference: the higher the score, the higher the likelihood that the response is aligned with the intention of the original prompt.
To learn more about ChatGPT, you can read our dedicated piece
LLMs in action - LeMUR
Large Language Models have seen a meteoric rise to public attention, which has spurred a lot of interest in using and developing with LLMs. In general, there is not a mature ecosystem of tools to apply LLMs to real-world applications given that, only a few years ago, LLMs were almost exclusively a subject of academic study.
To this end, we've built the LeMUR framework to make it easy to use and embed LLMs. You can try LeMUR in a no-code way through our Playground, as seen below where we asked LeMUR to summarize a 73 minute State of the Union address in a bulleted list with two bullet levels:
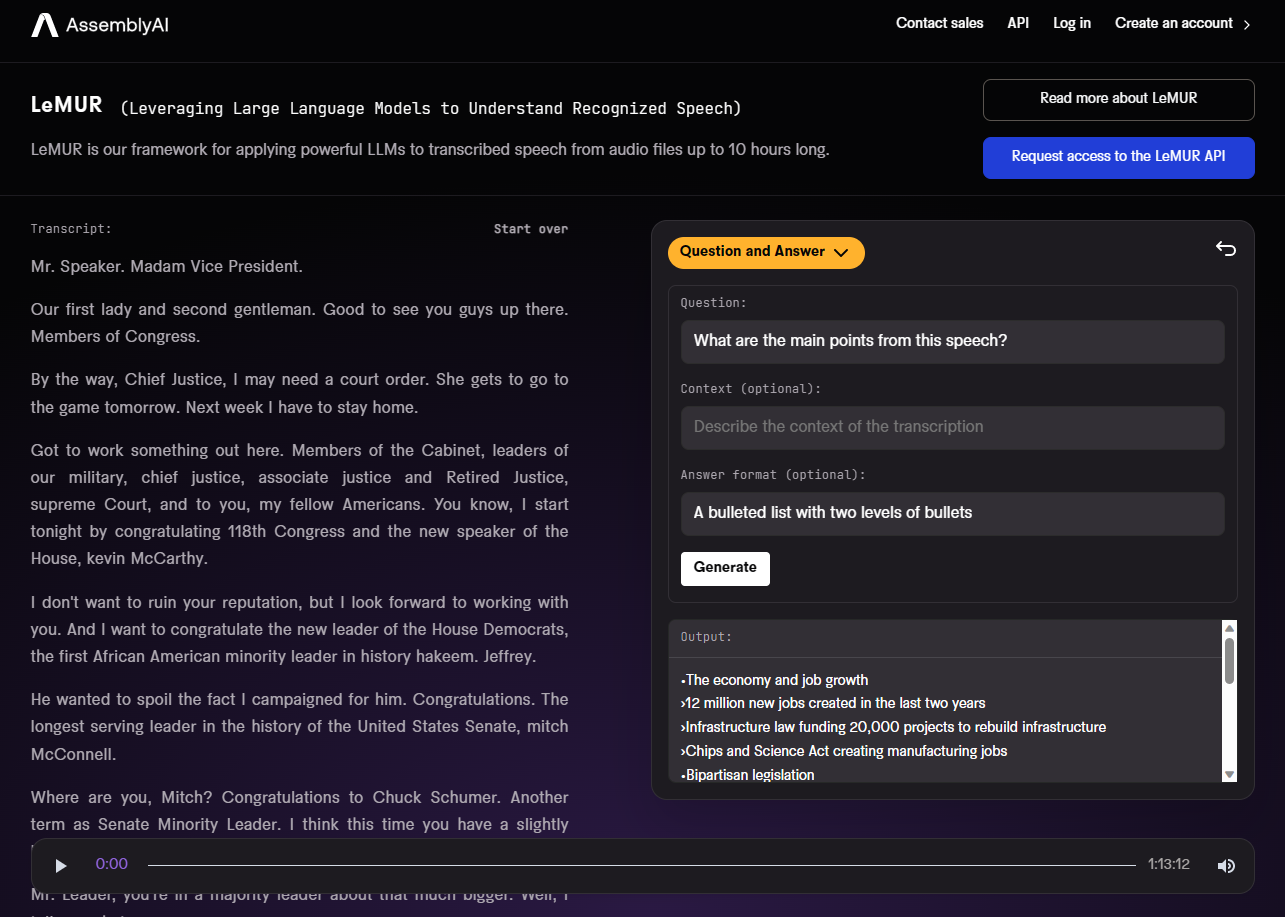
Here's what LeMUR returned:
Summary
-
The economy and job growth
- 12 million new jobs created in the last two years
- Infrastructure law funding 20,000 projects to rebuild infrastructure
- Chips and Science Act creating manufacturing jobs
-
Bipartisan legislation
- Over 300 bipartisan bills signed
- Infrastructure law and bills helping veterans
-
Lowering costs for Americans
- Capping insulin costs at $35/month for seniors
- Limiting out-of-pocket drug costs to $2,000 for seniors
- Cutting shipping costs by 90%
- Banning junk fees like resort fees
-
Tackling climate change
- Investing in clean energy and protecting against natural disasters
-
Making the wealthy and corporations pay their fair share
- No billionaire should pay lower taxes than teachers/firefighters
Final Words
We’ve taken a look in this article at the progress in Generative AI in the language domain. LLMs are the workhorse behind a range of cutting-edge applications, both in academia and in industry, and it is precisely their large scale that provides these capabilities.
In the next article in our Everything you need to know about Generative AI series, we will look at recent progress in Generative AI in the audio domain. In the meantime, you can check out our previous similar article on modern Generative AI for images. If you enjoyed this article, make sure to follow our newsletter to be notified when our next article drops.




