

In this week's Deep Learning Paper Review, we look at the following paper: Pretraining Representations for Data-Efficient Reinforcement Learning.
What's Exciting about this Paper
In recent years, pretraining has proved to be an essential ingredient for success in the fields of NLP and computer vision. The idea is to first pretrain a general model in an unsupervised manner, before fine tuning it on smaller supervised datasets. This simultaneously makes the fine tuning part much more data efficient and achieves superior performance at the same time. Nevertheless, in the field of reinforcement learning, pretraining has yet to become the standard. As a result, RL algorithms are notoriously data inefficient: a simple Atari game requires tens of millions of frames of training data to converge to human performance. Intuitively, this is because the RL agent has to learn two difficult tasks at once: visual representation from raw pixels and learning the policy and value functions.
This paper introduces a technique called SGI that decouples representation learning from reinforcement learning. First, the encoder of the RL agent is pretrained in an unsupervised manner using observed trajectories; the unsupervised objectives include predicting the next state based on the current state and action, and predicting the action responsible for state transitions. A key difference between this and previous work is that the next-state prediction occurs purely in the latent space and avoids using contrastive samples, therefore alleviating the needs for image reconstruction or large batch sizes (the latter of which is crucial for contrastive learning). After the pretraining, a downstream RL agent is instantiated with the pretrained encoder, and trained on Atari tasks (figure 1).
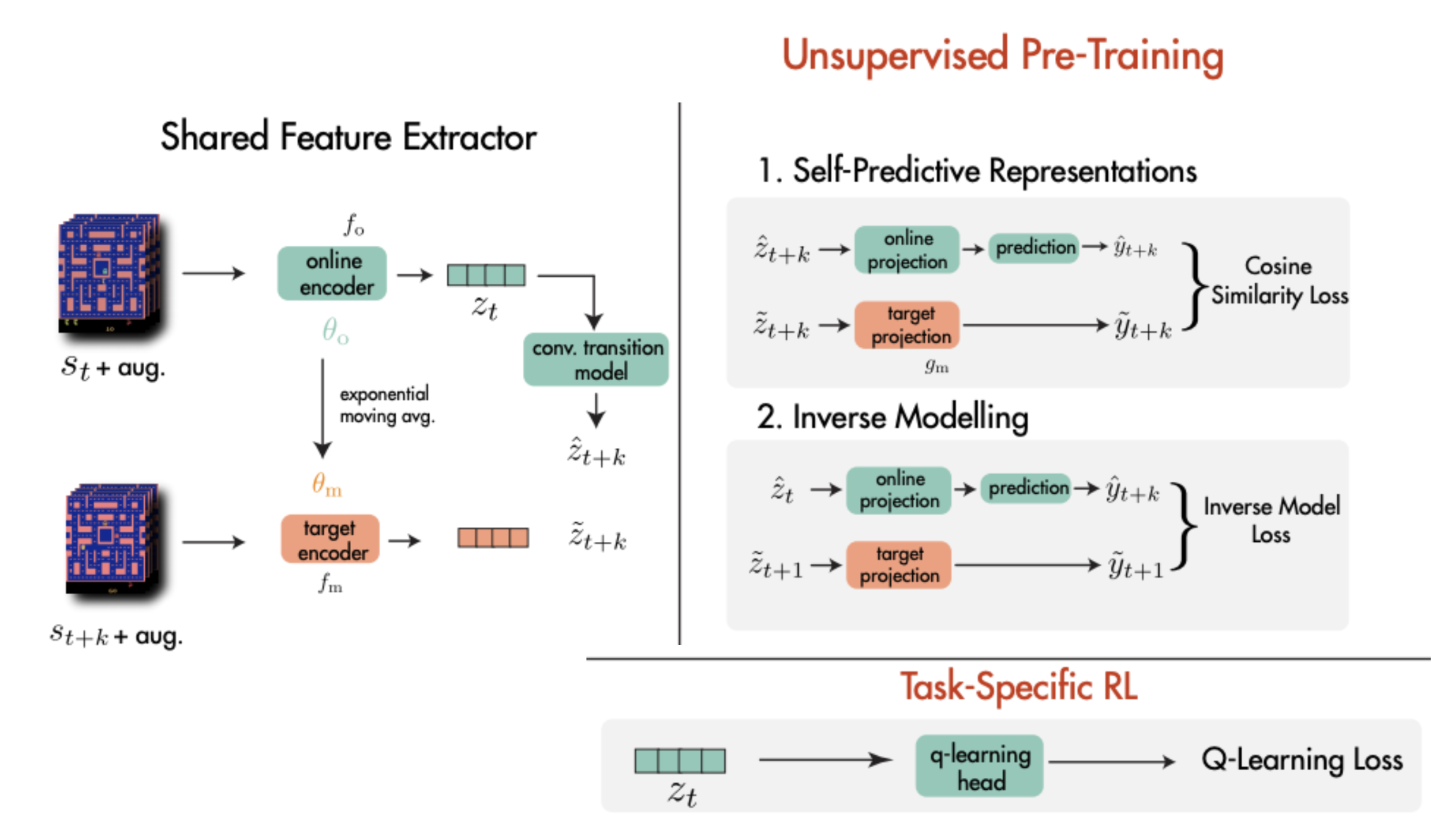
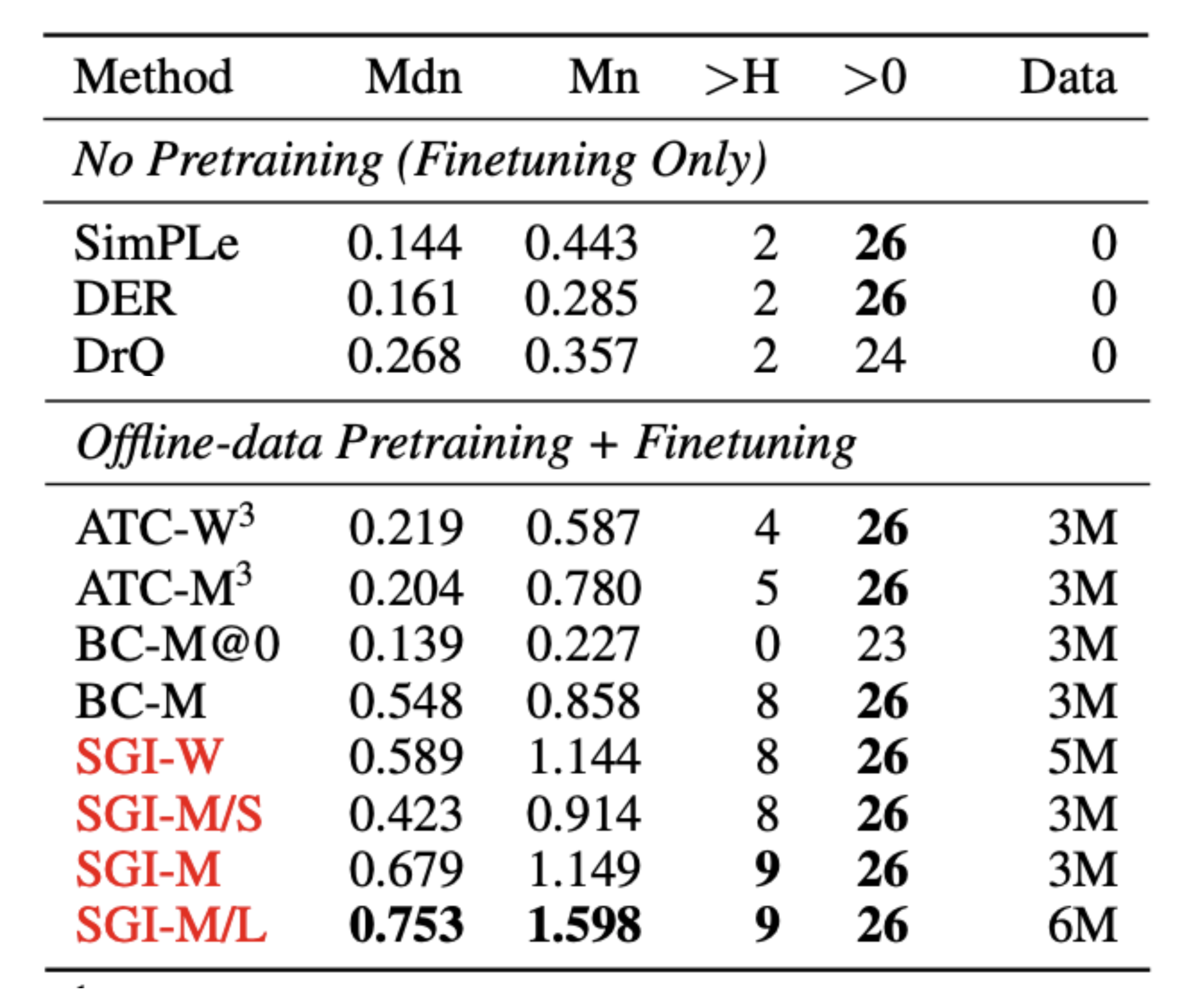
The authors demonstrate that 1) pretraining enables the RL agent to achieve much greater performance under limited training data, compared with agents initiated from scratch; 2) pretraining allows the RL agent to take advantage of much bigger encoders, while agents without pretraining fail to learn effectively using them.
Our Takeaways
This paper is exciting because it moves the field of RL towards the trend of building more generalized agents. When we learn a new video game as humans, we leverage our pretrained visual system and prior knowledge of the world to aid us. Similarly, we believe that a key feature for a truly general AI is the ability to utilize prior knowledge to solve new tasks. On a more practical level, techniques like SGI can make RL more data efficient, which is important for most real world applications where simulation is either impossible or computationally expensive.







