How to run OpenAI's Whisper speech recognition model
OpenAI's Whisper model can perform speech recognition on a wide selection of languages. We'll learn how to run Whisper before checking out a performance analysis in this simple guide.



OpenAI's Whisper is an open-source speech recognition model that supports multilingual transcription and translation across 99 languages. According to a developer overview, since its release in September 2022, Whisper has gained significant popularity for its high accuracy and open-source availability. This guide covers how to install and run Whisper, benchmark its accuracy and inference time across model sizes, and decide when a managed Voice AI API is the better choice for your use case.
Whisper joins other open-source speech-to-text models—like Kaldi, Vosk, and wav2vec 2.0—and delivers strong accuracy across a wide range of audio conditions.
What is OpenAI Whisper
OpenAI's Whisper is an open-source speech recognition model trained on 680,000 hours of multilingual and multitask supervised data. As a recent analysis explains, this was achieved through "weak supervision," where the model learned from a massive, diverse, and not always perfectly clean dataset of audio collected from the internet. It supports transcription in 99 languages and translation into English, with strong robustness to accents, background noise, and technical language.
How to install and run OpenAI Whisper
Before installing Whisper, confirm you have the following:
- Python 3.8–3.11
- PyTorch 1.10.1 or newer
- FFmpeg (covered in Step 1)
- GPU recommended for
mediumandlargemodels
Step 1: Install dependencies
Whisper requires Python 3.8-3.11 and a recent version of PyTorch (version 1.10.1 or newer is required). Install Python and PyTorch now if you don't have them already.
Whisper also requires FFmpeg, an audio-processing library. If FFmpeg is not already installed on your machine, use one of the below commands to install it.
Finally, if using Windows, ensure that Developer Mode is enabled. In your system settings, navigate to Privacy & security > For developers and turn the top toggle switch on to turn Developer Mode on if it is not already.
Step 2: Install Whisper
Now we are ready to install Whisper. Open up a command line and execute the below command to install Whisper:
pip install -U openai-whisperStep 3: Run Whisper
Command line
First, we'll use Whisper from the command line. Open a terminal and navigate to the directory containing your audio file. We will be using a file called audio.wav, which is the first line of the Gettysburg Address.
To transcribe this file, run the following command:
whisper audio.wavThe output will be displayed in the terminal:
[00:00.000 --> 00:07.000] Four score and seven years ago, our fathers
brought forth on this continent a new nation.The transcription is also saved to audio.wav.txt, along with a file audio.wav.vtt to be used for closed captioning.
Python
Using Whisper for transcription in Python is straightforward. Import whisper, specify a model, and transcribe the audio.
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.wav")
print(result["text"])The transcription text can be accessed with result["text"]. The result object itself contains other useful information:
{
"text": " Four score and seven years ago...",
"segments": [...],
"language": "en"
}Whisper advanced usage
This example walks through a modified version of the multilingual ASR notebook, transcribing and translating Korean audio files into English. Clone the repo and install dependencies:
git clone https://github.com/AssemblyAI-Examples/whisper-
multilingual.git
cd whisper-multilingual
pip install -r requirements.txtNext, run python main.py to transcribe and translate several Korean audio files into English. Each datum will take about 3 minutes to process on CPU. We use a total of 10 data points, so let the process run in the background while we examine the main.py code.
First, we perform all necessary imports, and then define a class that will be used to download and store the audio data. The details of this class are not relevant, so they have been omitted for brevity.
import io
import os
import torch
import pandas as pd
import urllib
import tarfile
import whisper
from scipy.io import wavfile
from tqdm import tqdm
class Fleurs(torch.utils.data.Dataset):
passNext, configure the parameters for the multilingual example:
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
LANGUAGE = "Korean"
LANGUAGE_CODE = "ko_kr"Now we create the dataset using the class we defined above, selecting a subsample of 10 audio files to make the processing quicker:
dataset = Fleurs(LANGUAGE_CODE, subsample_rate=10)Next, we load the Whisper model that we will be using, opting for the "tiny" model version to make inference quicker. We then set transcription and translation options:
model = whisper.load_model("tiny").to(DEVICE)
# Set transcription and translation options as dictionaries
transcribe_options = {"language": LANGUAGE, "without_timestamps": True}
translate_options = {"language": LANGUAGE, "task": "translate",
"without_timestamps": True}Finally, iterate through the dataset to process each audio file. The model transcribes to Korean and translates directly to English from audio—not from the transcription text.
for audio, text in tqdm(dataset):
# The model.transcribe() method handles padding/trimming and mel
spectrogram conversion internally
audio_tensor = torch.from_numpy(audio).to(DEVICE)
# Transcribe to Korean
result_transcribe = model.transcribe(audio_tensor,
**transcribe_options)
transcription = result_transcribe['text']
# Translate to English
result_translate = model.transcribe(audio_tensor,
**translate_options)
translation = result_translate['text']Save results to lists alongside ground truth references for comparison.
hypotheses.append(transcription)
translations.append(translation)
references.append(text)Finally, we create the pandas DataFrame which stores the results, and then print the results and save them to CSV.
df = pd.DataFrame({
"reference": references,
"transcription": hypotheses,
"translation": translations
})
print(df)
df.to_csv("results.csv", index=False)OpenAI Whisper performance analysis
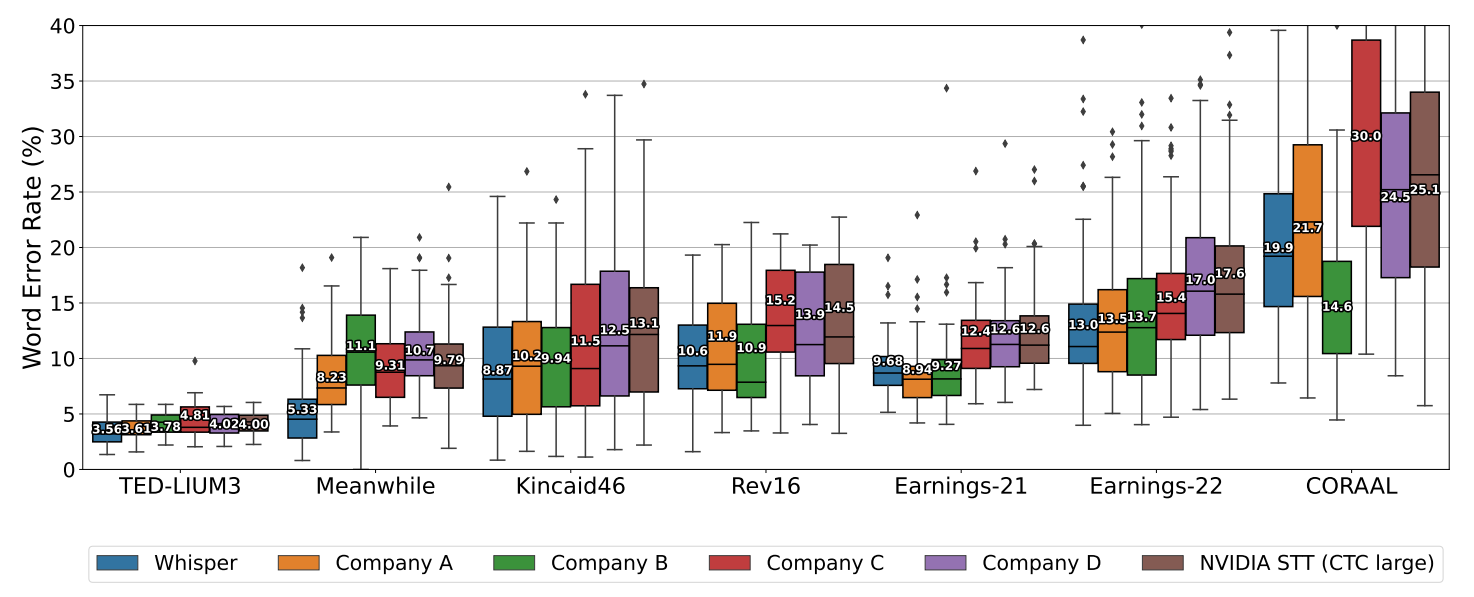
The figure below, sourced from the Whisper paper, compares Whisper's Word-Error-Rate (WER) against other speech recognition models across standard benchmarks. Whisper matches or exceeds the best available models on several English benchmarks—notable for an open-source model with no fine-tuning—though some benchmarks show it has an increased propensity for hallucinations and weaknesses in real-world use cases like proper noun detection.
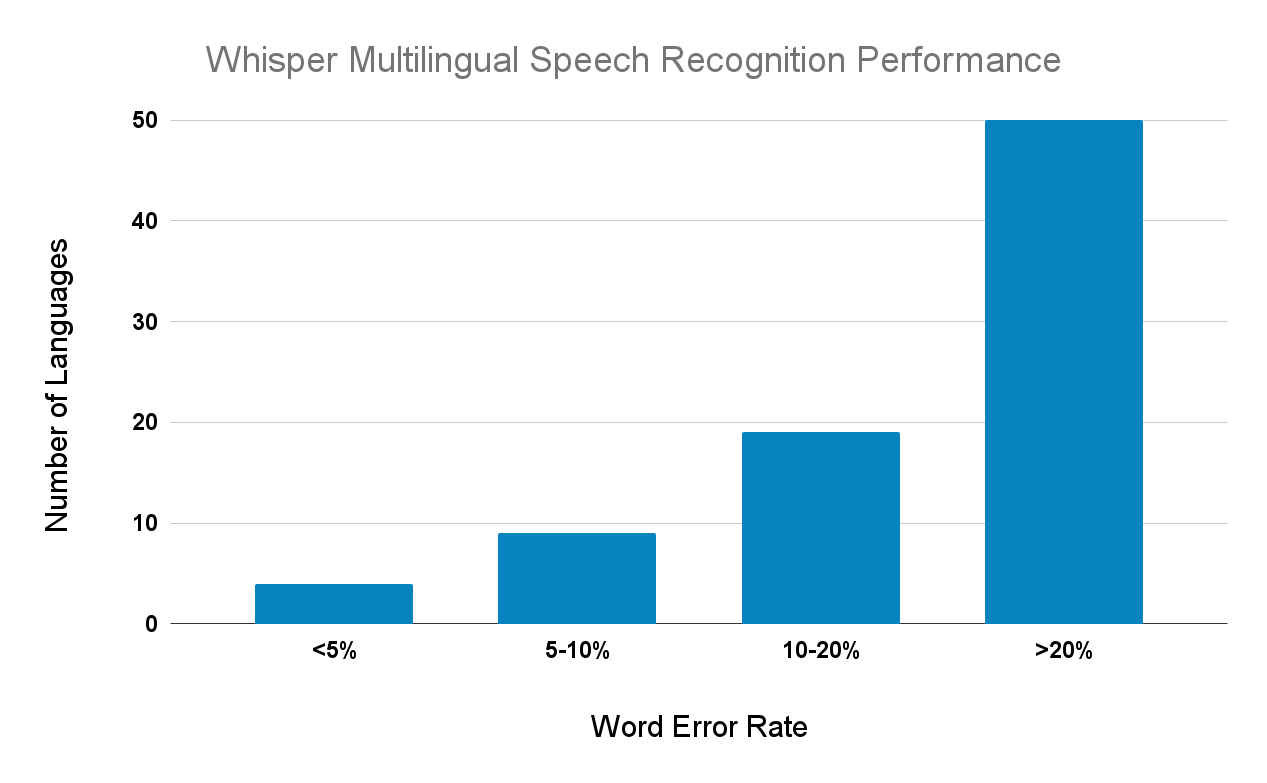
Multilingual performance varies significantly. Whisper performs well on Romance languages, German, and Japanese, but speech recognition remains an open problem for many other languages. Of the 82 languages evaluated, 50 have Word-Error-Rates above 20%.
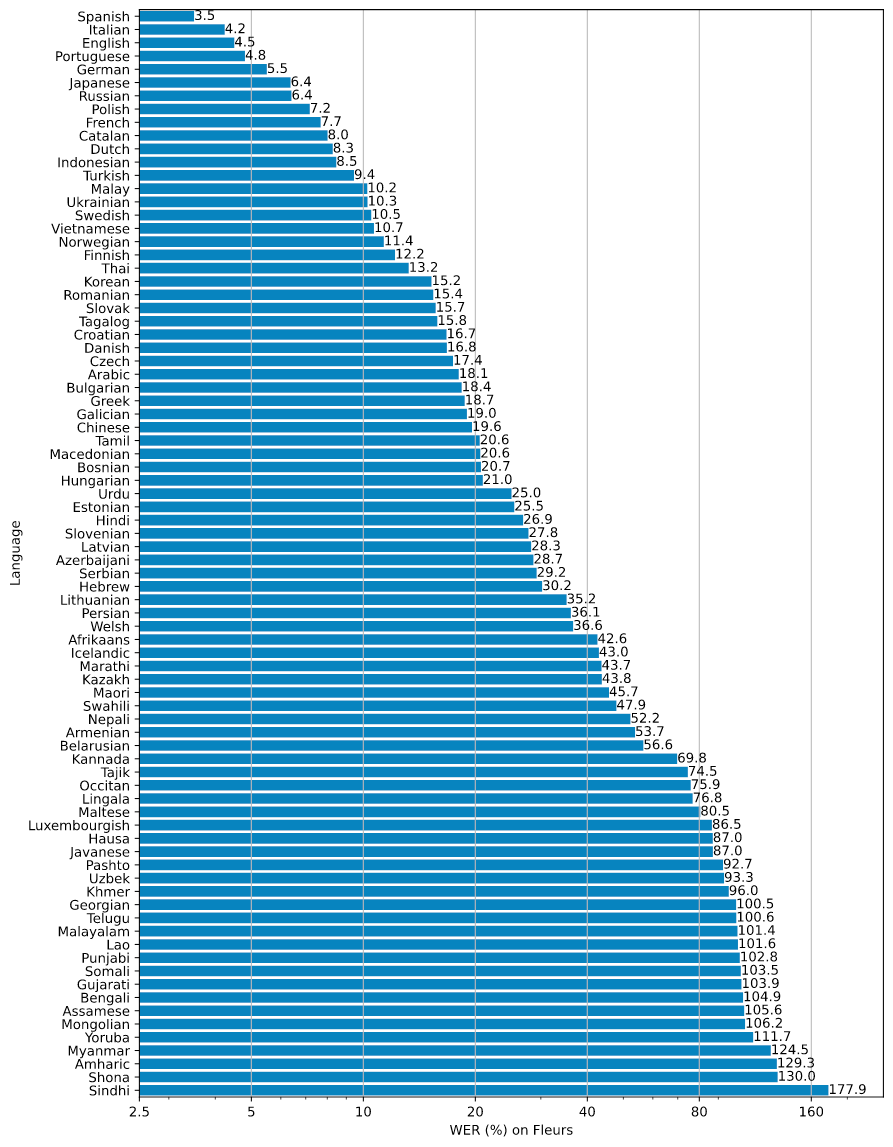
Whisper word error rate as a function of language
Anecdotal comparisons
The comparisons below pit Whisper against AssemblyAI's Universal-3 Pro model and Google Speech-to-Text across three real-world audio types: fast speech, conversational podcast audio, and a formal meeting recording.
First, we show a comparison of the Micro Machines example from the Whisper announcement post:
ModelTranscription OutputAssemblyAI (Universal-3 Pro)This is the Micro Machine Man, presenting the most midget miniature motorcade of Micro Machines. Each one has dramatic details, terrific trim, precision paint jobs, plus incredible Micro Machine Pocket Play Sets. There's a police station, fire station, restaurant, service station, and more. Perfect pocket portables to take any place. And there are many miniature play sets to play with. Each one comes with its own special edition Micro Machine vehicle and fun, fantastic features that miraculously move. Ooh, raise the boat lift at the airport marina. Man the gun turret at the army base. Clean your car at the car wash. Raise the toll bridge. And these play sets fit together to form a Micro Machine world. Micro Machine Pocket Play Sets, so tremendously tiny, so perfectly precise, so dazzlingly detailed, you'll want to pocket them all. Micro Machines are Micro Machine Pocket Play Sets sold separately from Galoob. The smaller they are, the better they are.Google Speech-to-Textthis is Michael presenting the most midget miniature motorcade of micro machine which one has dramatic details terrific current position paying jobs plus incredible Michael Schumacher place that's there's a police station Fire Station restaurant service station and more perfect bucket portable to take any place and there are many many other places to play with of each one comes with its own special edition Mike eruzione vehicle and fun fantastic features that miraculously move raise the boat looks at the airport Marina men the gun turret at the Army Base clean your car at the car wash raised the toll bridge and these play sets fit together to form a micro machine world like regime Parker Place that's so tremendously tiny so perfectly precise so dazzlingly detail Joanna pocket them all my questions are microscopic play set sold separately from glue the smaller they are the better they areWhisperThis is the Micro Machine Man presenting the most midget miniature motorcade of Micro Machines. Each one has dramatic details, terrific trim, precision paint jobs, plus incredible Micro Machine Pocket Play Sets. There's a police station, fire station, restaurant, service station, and more. Perfect pocket portables to take any place. And there are many miniature play sets to play with, and each one comes with its own special edition Micro Machine vehicle and fun, fantastic features that miraculously move. Raise the boatlift at the airport marina. Man the gun turret at the army base. Clean your car at the car wash. Raise the toll bridge. And these play sets fit together to form a Micro Machine world. Micro Machine Pocket Play Sets, so tremendously tiny, so perfectly precise, so dazzlingly detailed, you'll want to pocket them all. Micro Machines are Micro Machine Pocket Play Sets sold separately from Galoob. The smaller they are, the better they are.
The second example is a clip from a podcast:
ModelTranscription OutputAssemblyAI (Universal-3 Pro)One of them is, I made the claim, I think most civilizations going from simple bacteria-like things to space-colonizing civilizations, they spend only a very, very tiny fraction of their life being where we are. That I could be wrong about. The other one I could be wrong about is the quite different statement that I think that, actually, I'm guessing that we are the only civilization in our observable universe from which light has reached us so far that's actually gotten far enough to invent telescopes. So let's talk about maybe both of them in turn, because they really are different. The first one, if you look at the N equals one, the datum for one we have on this planet, right? So we spent four and a half billion years fucking around on this planet with life, right? We got, and most of it was pretty lame stuff from an intelligence perspective. Bacteria, and then the dinosaurs spent, then the things greatly accelerated. And the dinosaurs spent over 100 million years stomping around here without even inventing smartphones. And then very recently, we've only spent 400 years going from Newton to us, right? In terms of technology, and look what we've done even.Google Speech-to-Textone of them is I made the claim I think most civilizations going from simple bacteria are like things to space space colonizing civilization they spend only a very very tiny fraction of their other other life being where we are. I could be wrong about the other one I could be wrong about this quite different statements and I think that actually I'm guessing that we are the only civilization in the observable universe from which life has weeks or so far that's actually gotten far enough to men's telescopes but if you look at the antique was one of the date of when we have on this planet right so we spent four and a half billion years fucking around on this planet with life we got most of it was it was pretty lame stuff from an intelligence perspective he does bacteria and then the dinosaurs spent then the things right The Accelerated by then the dinosaurs spent over a hundred million a year is stomping around here without even inventing smartphone and and then very recently I only spent four hundred years going from Newton to us right now in terms of technology and look what we don't evenWhisperOne of them is, I made the claim, I think most civilizations, going from, I mean, simple bacteria like things to space colonizing civilizations, they spend only a very, very tiny fraction of their life being where we are. That I could be wrong about. The other one I could be wrong about is the quite different statement that I think that actually I'm guessing that we are the only civilization in our observable universe from which light has reached us so far that's actually gotten far enough to invent telescopes. So let's talk about maybe both of them in turn because they really are different. The first one, if you look at the N equals one, the date of one we have on this planet, right? So we spent four and a half billion years f**king around on this planet with life, right? We got, and most of it was pretty lame stuff from an intelligence perspective, you know, the dinosaur has spent, then the things were actually accelerated, right? Then the dinosaur has spent over a hundred million years stomping around here without even inventing smartphones. And then very recently, you know, it's only spent four hundred years going from Newton to us, right? In terms of technology, and we've looked at what we've done even.
The final audio file is from a board of directors meeting:
ModelTranscription OutputAssemblyAI (Universal-3 Pro)East Side Charter. I'm sorry. Go now. Okay. I'd like to call to order a special joint meeting of the Board of Directors of Eastside Charter School and Charter School of New Castle. It is 5:35. I'd like to call the roll. Attending for East Side Charter School, we have Ms. Stewart, Mr. Sawyer, Dr. Gordon, Mr. Hare, Ms. Sims, Mr. Veal, Ms. Fortunato, Ms. Dienno, and Mr. Humphrey. And attending for Charter School of New Castle, we have Dr. Bailey, Ms. Johnson, Mr. Taylor, Mr. McDowell, Mr. Preston, and Mr. Humphrey. Did I miss anybody? And I do not believe anybody is on the conference line. As there are no public items on our agenda, I would like a motion from a Charter School of New Castle board member to move into executive discussion to talk about personnel matters. I'll make that motion. Thank you. A second? Mr. Preston. All Charter School of New Castle board members in favor, please say aye. Aye. Any opposed? Motion unanimous. I would ask the same, put the same question to East Side Charter School. Thank you, Ms. Sims. Is there a second? Thank you, Mr. Veal. All those in favor, please say aye. Aye. Any opposed? Okay. So we move from public session to executive session at 5:35. We're now back in public session at 7:15. And there being no further business, I will entertain a motion from Charter School of New Castle to adjourn. Thank you. Is there a second? Thank you. All in favor, please say aye. Opposed? Charter School adjourned. East Side Charter School, for the same motion. Thank you. Thank you, Ms. Mitchell. All those in favor, please say aye. Opposed? Motion carries. Meeting adjourned. Thank you all very much.Google Speech-to-TextI'd like to call to order a special joint meeting of the board of directors of Eastside charter school is Charter School of New Castle it is 5:35 I'd like to call the roll and they're sending for eastside Charter School dr. Gordon sister here I miss them Mr Vilnius Fortunato misiano and Mr Humphrey attending for Charter School of New Castle we have dr. Bailey is Johnson mr. Taylor Miss McDowell mr. Preston and mr. Humphries is anybody and I do not believe anybody is on the conference line is there is no public items on our agenda I would like a motion from a charter school of New Castle board meeting to move into executive discussion to talk about personal matters call Turtle Newcastle board members in favor please say I charter school all those in favor please say I so we moved from public session to Executive session at 5:35 okay it is 750 + can you just leave it here at 7:15 and there being no further business I was in between the motion soundtrack to a New Castle to adjourn thank you is there s you all in favor please say I referred her to let her know I will be set at her school for the promotion of a second long does it take a PPI motion carry beating jiren thank you all very much.WhisperI'd like to call to order a special joint meeting of the board of directors of East Side Charter School in Charter School of Newcastle. It is 535. I'd like to call the role and attending for East Side Charter School. We have Mr. Stewart, Mr. Sawyer, Dr. Gordon, Mr. Hair, Ms. Thames, Mr. Veal, Ms. Portionato, Ms. Dienno, and Mr. Humphrey. And attending for Charter School of Newcastle, we have Dr. Bailey, Ms. Johnson, Mr. Taylor, Mr. McDowell, Mr. Preston, and Mr. Humphrey. I do not believe anybody is on the conference line. As there is no public items on our agenda, I would like a motion from a Charter School of Newcastle board meeting to move into executive discussion to talk about personnel matters. I'll make that motion. Thanks, Mr. Preston. All Charter School of Newcastle board members in favor, please say aye. Aye. Aye. Any opposed? Motion unanimous. I would ask the same question to East Side Charter School. Thank you, Mr. Thames. Is there a second? Thank you, Mr. Veal. All those in favor, please say aye. Aye. Any opposed? Okay. So we move from public session to executive session at 535. Okay, we're back. Okay. It is now 715. And we're back in public session. You just need to carry my phone. Okay. So we are now back in public session at 715. And they're being a further business. I will then be paying the motion from Charter School of Newcastle to adjourn. Thank you. Is there a second? Thank you. All in favor, please say aye. Aye. Any opposed? Charter School adjourned. I will ask East Side Charter School for the same motion as usual. Thank you. Mr. Thames, Mr. Mitchell, all those in favor, please say aye. Any opposed? Motion carries. Meeting adjourned. Thank you all very much.
Across all three examples, Whisper produces clean, well-punctuated output that closely matches AssemblyAI's Universal-3 Pro model—and both significantly outperform Google Speech-to-Text on fast and domain-specific speech.
Whisper inference time
Larger models produce more accurate transcriptions but require significantly more compute. Run medium and large on GPU—CPU inference at these sizes is impractically slow for most workloads.
We benchmarked the Micro Machines example across all model sizes.
Results for CPU (i5-11300H):
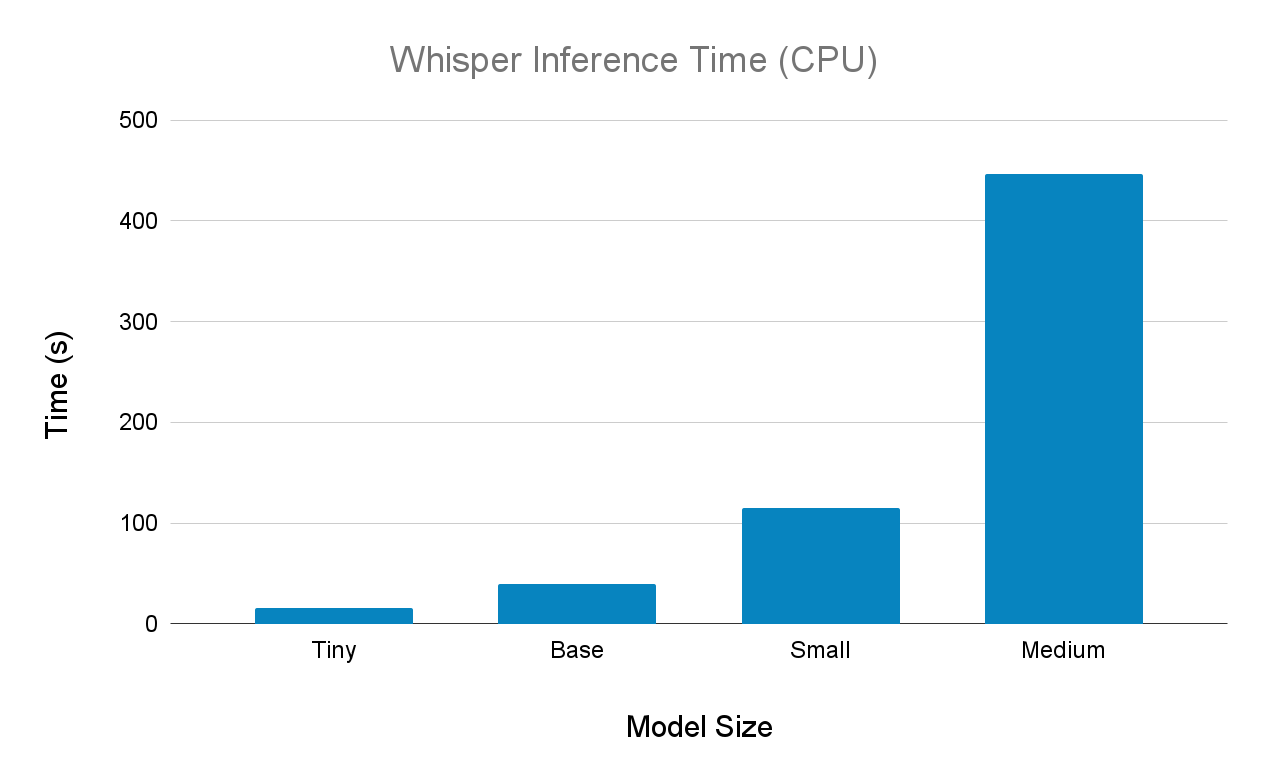
Next, we have the results on GPU (high RAM GPU Colab environment):
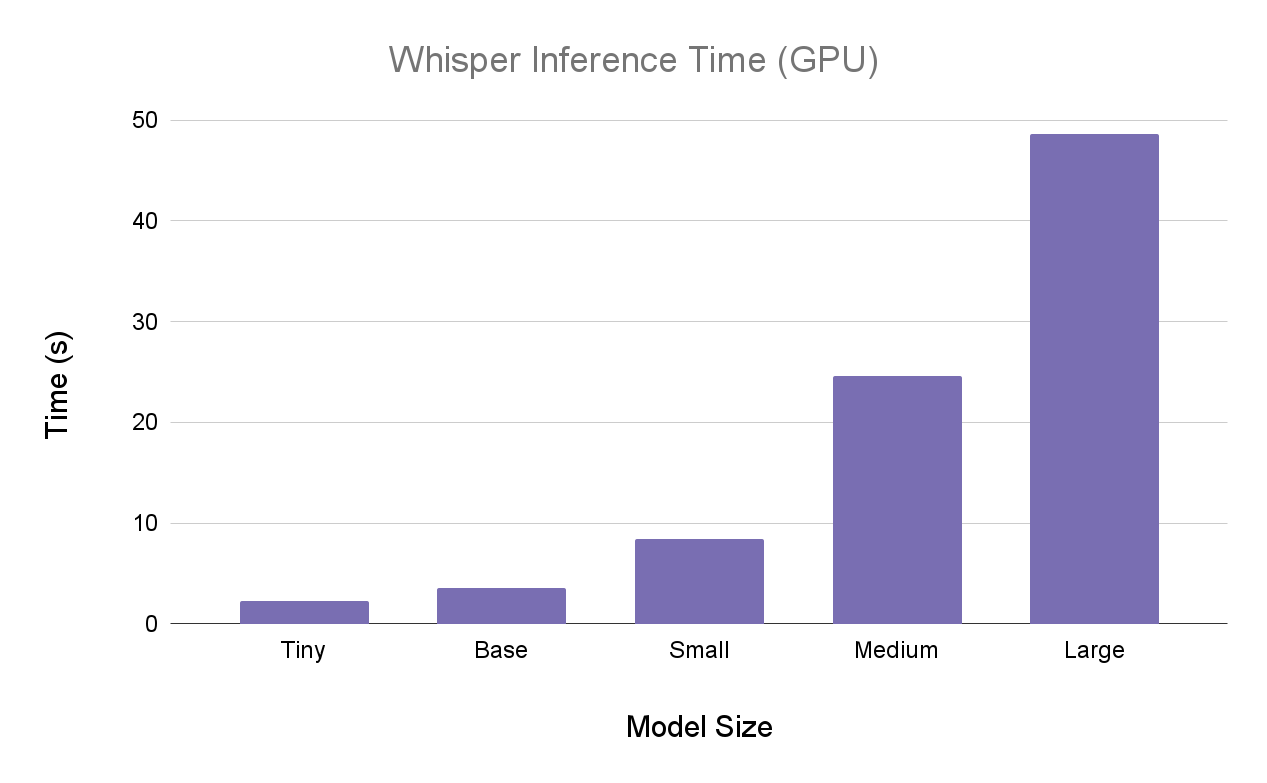
Here are the same results side-by-side:
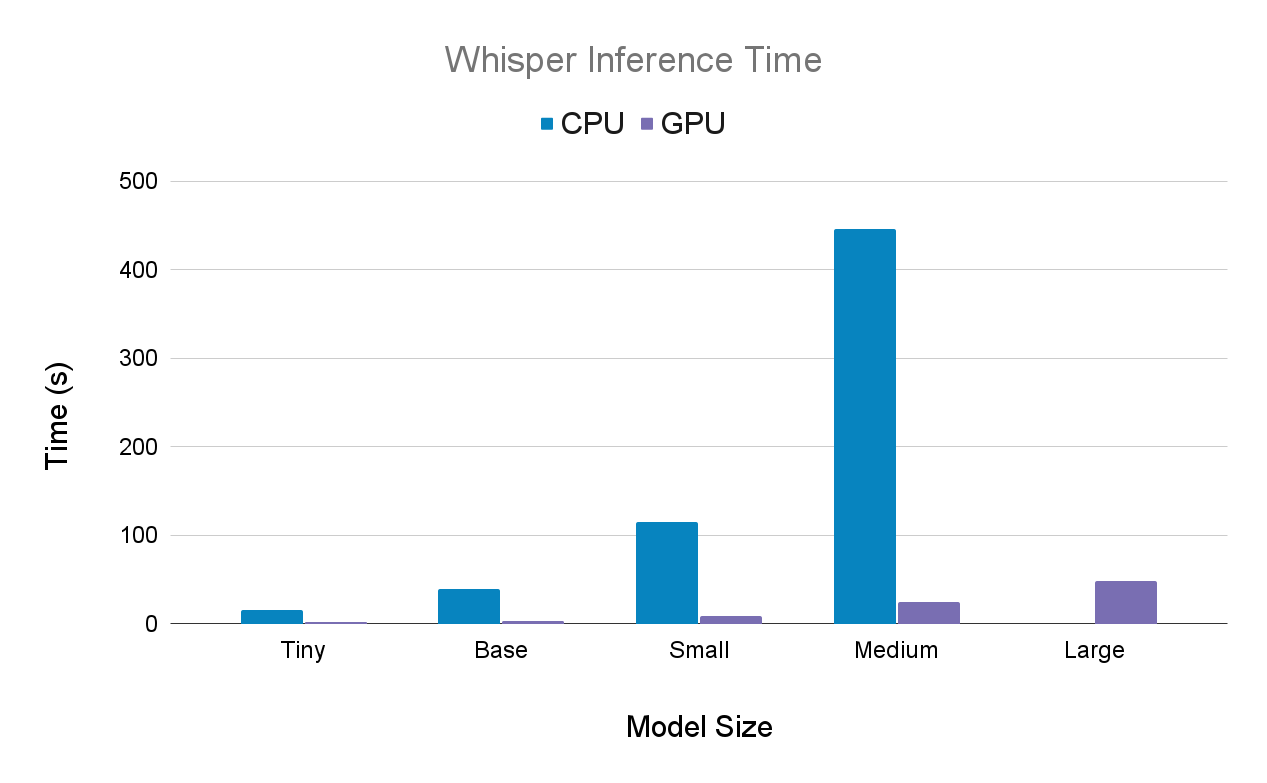
Cost to run Whisper
We provide the cost to transcribe 1,000 hours of audio using Whisper in GCP (1x A100 40 GB) for each model size using different batch sizes, the values of which can be found in the legend.
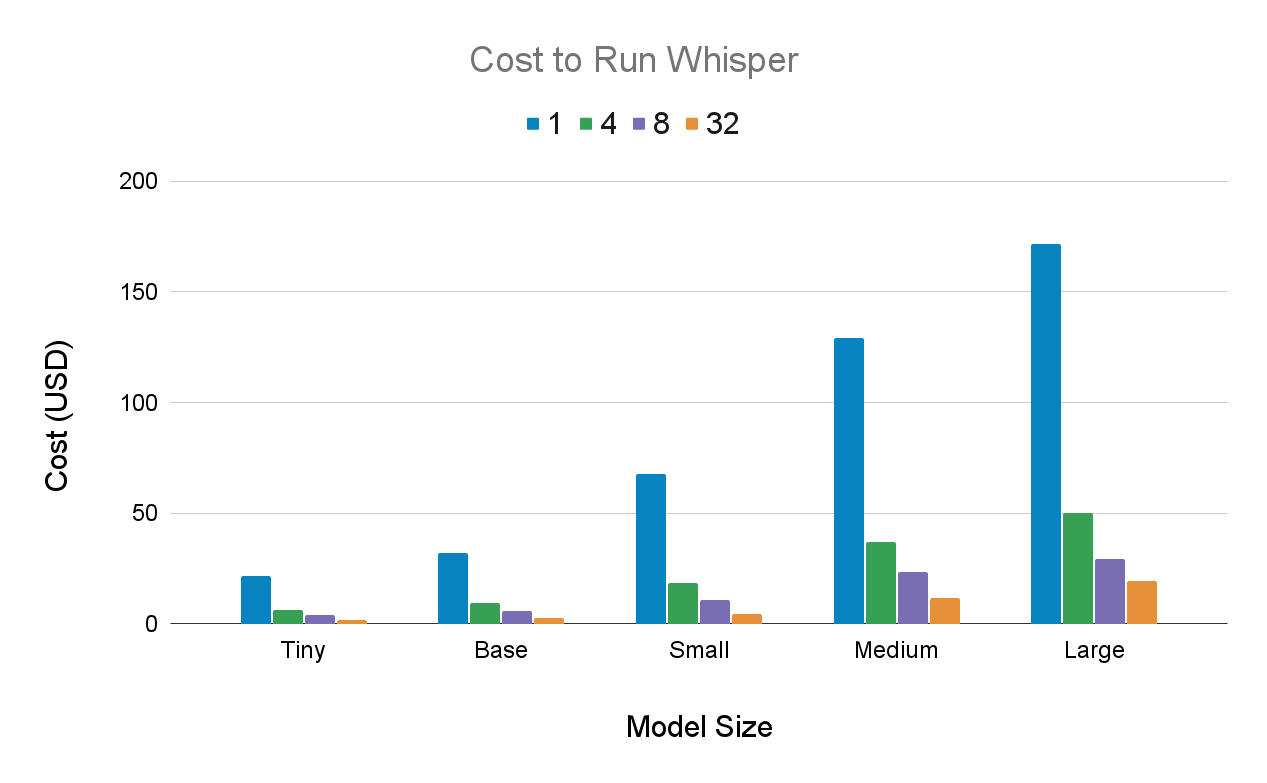
Costs are based on late 2022 GCP pricing and reflect compute only. As a detailed cost analysis highlights, current cloud pricing may differ, and these figures do not account for infrastructure and engineering costs, which often exceed API pricing at small to medium scales. The following are not included in these figures:
- Engineering time to build and maintain inference infrastructure
- Ongoing model updates to maintain accuracy over time
- Bug fixes and performance regression monitoring
- A dedicated research or ML engineering team for competitive improvements
Final words
Whisper delivers strong transcription accuracy across multiple languages and outperforms older open-source options on most benchmarks. For best results, run medium and large models on GPU—locally or in the cloud—since CPU inference at those sizes is too slow for practical use.
When to use Whisper vs. managed Voice AI APIs
When choosing a speech-to-text solution, you have three main options: self-hosting the open-source Whisper model, using a managed API that provides the Whisper model, or using a managed API with a proprietary model like AssemblyAI's Universal-3 Pro. Security is often a key consideration, and a market survey found that over 30% of builders cite data privacy as a significant challenge. Each has distinct trade-offs in terms of cost, maintenance, and features.
Getting started with production Voice AI
Whisper is a strong starting point for prototyping. But moving to production means managing GPU provisioning, concurrent request handling, fallback logic, and ongoing model updates—each adding engineering overhead that compounds at scale.
Companies like Veed, Descript, and CallSource use AssemblyAI's API to handle Voice AI infrastructure, so their teams can focus on product features instead. If you want to skip the infrastructure setup entirely, try our API for free.
Frequently asked questions about OpenAI Whisper implementation
How do I optimize Whisper performance for production workloads?
Use GPU inference, implement batching, and choose the smallest model that meets accuracy requirements. For real-time apps, consider audio chunking techniques, which can require significant engineering work to build buffering systems, handle audio splitting, and manage timing synchronization.
What should I do when Whisper fails to transcribe audio files?
Check audio format compatibility and system memory logs for errors. For persistent failures, consider fine-tuning or switching to a commercial API.
How do I handle different audio formats with Whisper?
FFmpeg handles format conversion automatically in command-line usage. For Python, use pydub or librosa to convert audio before passing to the model.
When should I choose Whisper over commercial speech-to-text APIs?
Choose Whisper for research, offline processing, or projects where data control and cost matter more than reliability and speed. Choose a managed API when you need consistent uptime, low-latency streaming, advanced features like speaker diarization, and dedicated support without managing infrastructure yourself.
How can I reduce Whisper's memory usage and inference time?
Use smaller model sizes (tiny or base) and enable half-precision with torch.float16. Process long files in chunks to reduce memory usage.
Does Whisper offer diarization?
No, the open-source Whisper model from OpenAI does not include native speaker diarization, requiring developers to use separate models and alignment to identify different speakers. However, API providers like AssemblyAI can add speaker diarization to Whisper's output. This allows you to get the benefit of the Whisper model combined with the speaker labeling capabilities of a managed API, which is a powerful combination for processing multi-speaker audio.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts