


We’re introducing new models for Punctuation Restoration and Truecasing, which outperform our previous production models on a variety of data and metrics. In particular, we observe the following improvements relative to the previous models:
- Significant improvements in handling casing for particularly challenging linguistic types, such as mixed-case words (+39% F1 score), acronyms (+20% F1 score), and capital-case (+11% F1 score).
- Overall 17% relative improvement on average across our test datasets for predicting upper-case letter classification.
- Overall punctuation accuracy improves by 11% (F1 score).
- Our qualitative analysis (based on human preference) shows that the new model is preferred on average 61% over the previous production model by our evaluators.
These improvements reflect the combined result of both an architectural change for handling the truecasing objective as well as a 340% increase in the training data. Our experiments (see below) show that the new model is more robust across different linguistic domains, making it a viable solution for real-scenario usage.
The new neural truecasing architecture is loosely inspired by previous work published by Google Research [1] [2] and builds on other academic works around Punctuation Restoration and Truecasing [3] [4] [5]. The new models are already in production. Our current API users will start seeing improved performance from the upgraded models with no changes required on their ends.
You can try our new Punctuation Restoration and Truecasing model in our no-code Playground here.
Introduction
Punctuation Restoration and Truecasing are critical components in speech-processing applications, transforming the output from Automatic Speech Recognition (ASR) models into well-structured and intelligible text. These processes not only improve readability but are also vital for the functionality of subsequent Natural Language Understanding (NLU) systems, such as LeMUR or Audio Intelligence, by reinforcing necessary syntactic structure and grammatical context.
We are pleased to introduce our new models for Punctuation Restoration and Truecasing, which have been designed to enhance the precision of transcript formatting through improved punctuation restoration and character-level truecasing. Our new models represent a methodological advancement in our approach to handling textual data, setting a refined standard for accuracy in text-processing tasks.
In the following sections, we will detail the architectural innovations and the comparative results showing the model's performance enhancement over our previous system.
Research
We’ve designed a new two-stage neural pipeline for enhancing text transcripts generated by speech-to-text systems. The model operates sequentially: the first stage predicts punctuation and the second stage casing.

Each stage leverages a deep neural network that operates as a sequence labeling problem but at different granularities: the first network operates at the token level and the second at the character level. Below, we provide a simplified explanation of the process and key findings from our research.
Punctuation Restoration
A first token-level neural network predicts whether, for each word, a comma, period, or other punctuation should be added after the word. From our experiments, we’ve observed that the standard architecture of a transformer with a classification head is the best-performing choice for this task. We’ve used the DistilBertTokenizer, which inherits from the BERT WordPiece tokenization scheme.
Training Data: We trained this neural network on a total of 3.7 billion words from conversational speech datasets (our previous model was trained with 2.18 billion words).
Key Findings: Our experiments show evidence that the performance improvements we see in punctuation are proportional to the increase in training data. This aligns with the scaling laws observed in other areas of deep learning, such as Automatic Speech Recognition and Large Language Models research.
Truecasing
The punctuation component is followed by a second neural network that, instead of working at the token level, works at the character level. This network predicts whether each character needs to be uppercased or not.
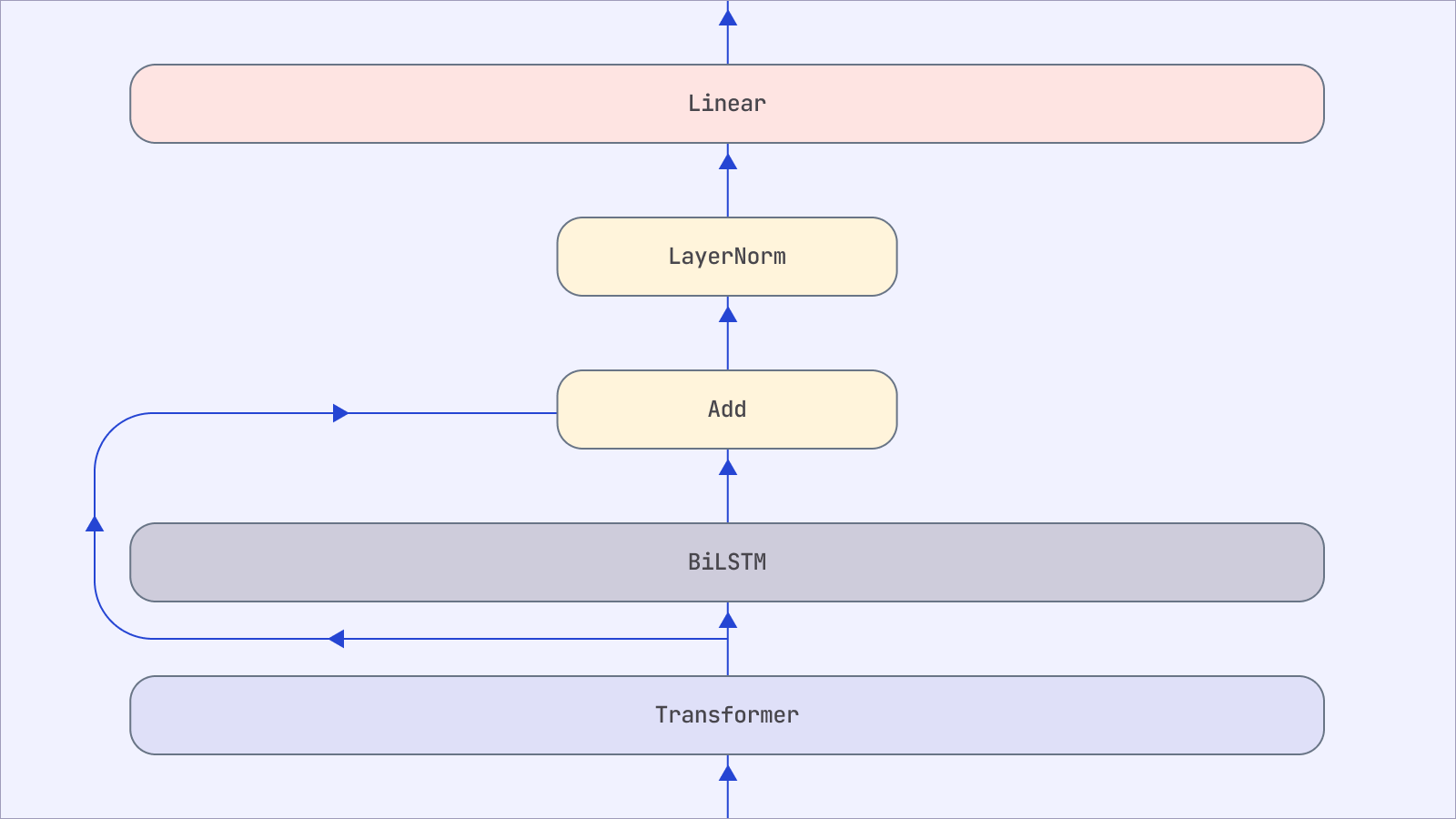
Architecture Overview:
- Transformer Layer: This layer is the model’s foundation, as it is responsible for understanding the input’s context. Transformers use self-attention mechanisms to weigh the importance of different parts of the input data. For casing, self-attention would look at character patterns and their context. Our Transformer weights are initialized with a Canine model pre-trained by Google Research.
- BiLSTM (Bidirectional Long Short-Term Memory): The encoded representation from the Transformer is passed to a BiLSTM, which is particularly good at capturing sequential information. The forward LSTM processes the sequence from start to end, and the backward LSTM processes it from end to start. This bi-directionality allows the network to have both past and future context for any given point in the sequence, which is crucial for casing tasks.
- Residual Connection: The model implements a residual connection from the input of the BiLSTM to its output. This connection helps in two ways:
- Combining the sequential nature captured by the BiLSTM with the deeper semantic understanding from the Transformer.
- Alleviating the vanishing gradient problem by allowing gradients to flow directly through the network, making training more efficient and stable.
- LayerNorm: Following the residual connection, Layer Normalization is applied to ensure that the weights remain normalized, speeding up training and helping to prevent overfitting.
- Linear Classification Layer: The final layer is a binary classifier that maps the output of the previous layers to the (binary) label space: uppercase (U) or lowercase (L).
Similar hybrid architectures pairing BiLSTM and transformer layers are commonly used for sequence-tagging tasks because of the Bi-LSTM efficiency in capturing context from neighboring words. To the best of our knowledge, our approach represents a novel application of this architecture for a casing classification objective.
Training Data: We trained this neural network on a total of 9.6 billion words.
Key Findings: We found that increasing focus on preprocessing the training data correlates heavily with gains in model prediction quality. To this end, we’ve developed a new data-filtering pipeline that computes the difference between the training distribution and a pre-computed “gold” target distribution based on punctuation and casing statistical priors. In particular, adopting this data-cleaning pre-processing step resulted in a reduction in model hallucinations.
Comparing Old vs. New Models
The development of our latest models for Punctuation Restoration and Truecasing marks a significant evolution from the previous system. Here we provide a comparative overview highlighting the structural and operational differences between the two.
Overview of the previous system:
- Architecture: A two-stage hybrid model combining a DistilBERT-like transformer with rule-based post-processing.
- Task Handling: The neural component simultaneously predicts punctuation and capitalization with a single output tag per token.
- Main Limitations: Inability of the neural network to handle mixed-case words (e.g., "AssemblyAI") and acronyms (e.g., “NLP”), and reliance on rule-based refinement via a lookup table for casing, which hampers efficiency, scalability, and generalization.
The main advantages of the new pipeline over the previous approach may be summarized as follows:
- Decoupling the Tasks: By separating punctuation and casing into two distinct models, the complexity of the problem is reduced, making it easier to manage and potentially increasing the system's performance as each model can specialize in its task.
- Divide and Conquer: Splitting the label space reduces the complexity of each individual model. Each task is simplified into a binary-like sequence tagging problem, with a clear focus on either punctuation or casing.
The new system supersedes its predecessor by providing a more streamlined and specialized approach to the challenges of punctuation and casing, addressing previous limitations. Allowing for separate training of the two stages benefits the system’s stability and enhances task specialization. The new approach also allows for a faster model update by fine-tuning each stage separately on specific data in case one task requires more attention or if new types of punctuation or new casing rules must be incorporated into the system.
Experiments
In this section, we report on our experiments that show how our new Punctuation Restoration and Truecasing models outperform the previous production models on various experimental setups.
The Punctuation Restoration chart below displays the absolute improvement in accuracy of our new model over the production model in terms of the correct placement of periods, commas, and question marks. These improvements are quantified using F1 scores, which combine precision and recall into a single metric.

For Truecasing, we focus on four linguistic categories that indicate how well the model predicts the correct case of letters in different casing scenarios. These are:
- Acronyms: Words where all letters are capitalized, such as “NASA.”
- Capital-case: Typically the initial letter of proper nouns or the beginning of sentences that need capitalization, such as “San Francisco” or “Once upon a time.”
- Lowercase: Words that should remain lowercase because they don’t fall into the special categories requiring capitalization. The proficiency of Truecasing in this category is generally high, with little room for improvement, as most words in any given text do not require capitalization.
- Mixed-case: Words that combine uppercase and lowercase letters within the same word, such as “AssemblyAI.”

Try our Speech AI Models
Our new Punctuation Restoration and Truecasing models are now live and operational through our API. If you're already using our API, you'll automatically benefit from these upgrades.
You can try out our API directly for free. Simply sign up for a free API token, and head over to our Docs or welcome Colab to be up and running in just a few minutes.
References
- Zhang et al., 2021 (Google Research) propose an approach to Truecasing that hierarchically exploits word and character-level encoding. A first RNN stack processes the input text at the token level; each token is then further expanded and encoded through another RNN stack working at the character level.
- Clark et al., 2022 (Google Research) propose Canine, a tokenization-free Transformer architecture operating directly on character sequences. The Canine pre-training strategy reduces input sequence length through downsampling, while efficiently encoding context with a deeper transformer stack.
- Susanto et al., 2016 (ACL2016) model the Truecasing task through a Sequence Tagging approach performed at the character level. This accounts for mixed-case words. Character sequences are encoded through an LSTM/GRU layer, and predictions are made for each character.
- Mayhew et al., 2020 (AAAI2020) perform Truecasing as an auxiliary task supporting the main NER one. They show that jointly learning Truecasing and NER together is beneficial to both tasks. The encoder is a BiLSTM, and Truecasing predictions are performed at the character level.
- Păiș et al., 2021 shared a pretty comprehensive survey on punctuation and casing restoration. It is interesting to see how the model proposed by Susanto et al., 2016 is still at the forefront of the SOTA models.




