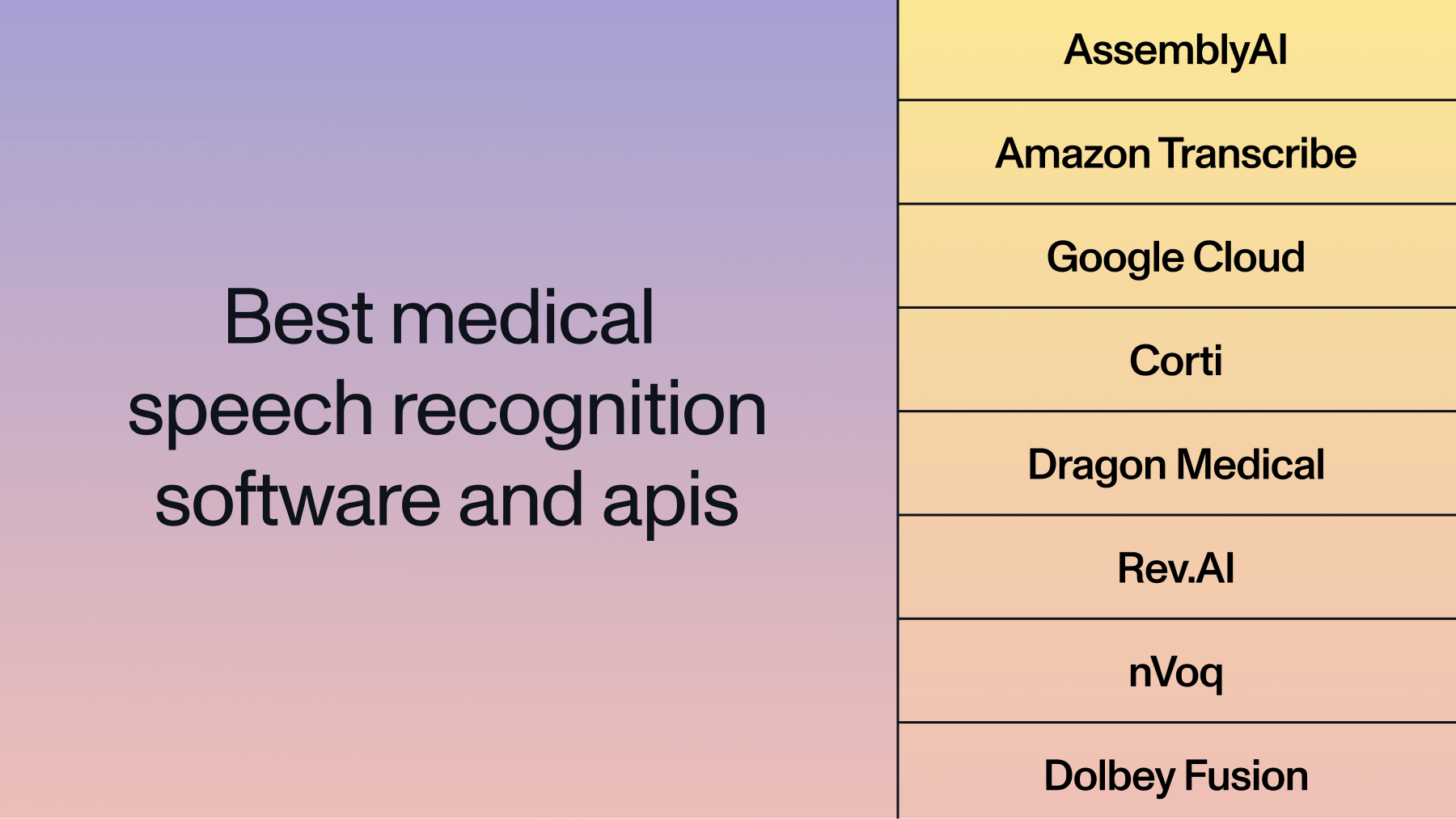
Comparing Zoom Transcription Accuracy Across Speech-to-Text APIs
In this benchmark report, we compare transcription accuracy between AssemblyAI, Google Cloud Speech-to-Text, and AWS Transcribe on Zoom Meeting Recordings.




3.3 trillion meeting minutes are hosted on Zoom each year, a 3,300% increase from the same quarter of last year. This is roughly everyone in the world using Zoom for 7 hours of meetings this year.
It's clear Zoom is changing how we learn and work, and many new software companies are further enabling this adoption by building their solutions on top of Zoom. The recent launch of Zoom Apps has made it even easier for us to get more out of our conversations using these new integrations, some examples include:
Fathom
Record, transcribe, and highlight the key moments from your Zoom calls so you can focus on the conversation instead of taking notes

Vidyard
Automatically send your Zoom meeting and webinar recordings to a video platform where you can host, edit, and securely share your videos

Gong
Write comments and collaborate in real-time with other Gong users from your company during meetings

Zoom, along with all of it's integration partners, are enriching the virtual conversations we're having; helping us remember what we discussed and highlighting insights we may not have even realized (like who spoke more, what topics were discussed, etc).
Automated Speech Recognition (ASR) is at the core of these platforms, and the transcription accuracy is a top priority for product managers and developers at these companies to ensure they're building the best possible features.
In this benchmark report, we found Zoom recordings across a wide range of use cases—everything from product demos and internal business meetings, to live online classes at schools and gyms. Then, we put together a side-by-side comparison of which ASR models had the highest transcription accuracy between AssemblyAI, Google Cloud Speech-to-Text, and AWS Transcribe.
We also share results for these same Zoom recordings using AssemblyAI's enrichment models for Topic Detection, Keyword Detection, PII Redaction, and Content Safety Detection.
Speech Recognition Accuracy
Our Dataset
To give a comprehensive range of accuracy results, we used Zoom recordings of sales demos, webinars, online classrooms, cooking tutorials, and fitness group classes. This provides a wide range of accents, audio quality, number of speakers, and industry-specific vocabularies.
Here is more about our dataset below:
How we calculate accuracy
- First, we transcribe the files in our dataset automatically through APIs (AssemblyAI, Google, and AWS).
- Second, we transcribe the files in our dataset by human transcriptionists—to approximately 100% accuracy.
- Finally, we compare the API's transcription with our human transcription to calculate Word Error Rate (WER) — more below.
Below, we outline the accuracy score that each transcription API achieved on each audio file. Each result is hyperlinked to a diff of the human transcript versus each API's automatically generated transcript. This helps to highlight the key differences between the human transcripts and the automated transcripts.
Accuracy Results
Accuracy Averages
Test Our Industry-Leading Speech Recognition
Try AssemblyAI's most accurate speech-to-text model with your own audio files in our no-code playground. See results instantly.
WER Methodology
The above accuracy scores were calculated using the Word Error Rate (WER). WER is the industry-standard metric for calculating the accuracy of an Automatic Speech Recognition system. The WER compares the API generated transcription to the human transcription for each file, counting the number of insertions, deletions, and substitutions made by the automated system in order to derive the WER.
Before calculating the WER for a particular file, both the truth (human transcriptions) and the automated transcriptions must be normalized into the same format. This is a common step that teams miss, which ends up resulting in misleading WER numbers. That's because according to the WER algorithm, "Hello" and "Hello!" are two distinct words, since one has an exclamation and the other does not. That's why, to perform the most accurate WER analysis, all punctuation and casing is removed from both the human and automated transcripts, and all numbers are converted to the spoken format, as outlined below.
For example:
truth: Hi my name is Bob I am 72 years old.
normalized truth: hi my name is bob i am seventy two years old
AssemblyAI Enrichment
Topic Detection
Our Topic Detection feature uses the IAB Taxonomy, and can classify transcription texts with up to 698 possible topics. For example, a Tesla release event streamed on Zoom would be classified with the "Automobiles>SelfDrivingCars" topic, among others.
You can find a list of all the topic categories that can be detected in the AssemblyAI Documentation.
Keyword Detection
AssemblyAI can also automatically extract keywords and phrases based on the transcription text. Below is an example of how the model works on a small sample of transcription text.
Original Transcription:
Hi I'm joy. Hi I'm Sharon. Do you have kids in school? I have grandchildren in school. Okay, well, my kids are in middle school in high school. Do you think there is anything wrong with the school system?
Detected Keywords:
"high school" "middle school" "kids"
Using the same dataset, we included the topics and keywords automatically detected in each file below:
PII Redaction
Zoom meetings can contain sensitive customer information like credit card numbers, addresses, and phone numbers. Other sensitive information like birth dates and medical info can also be stored in recordings and transcripts. AssemblyAI offers PII Detection and Redaction for both transcripts and audio files ran through our API.
You can learn more about how this works in the AssemblyAI Documentation. The full list of information our PII Detection and Redaction feature can detect can be found below:
With PII Detection and Redaction enabled, we ran the above Zoom recordings through our API to generate a redacted transcript for each recording. Below is an excerpt from one of the recordings, and below are links to the full transcriptions.
Good afternoon. My name is [PERSON_NAME] and I will be your [OCCUPATION] [OCCUPATION] today. Hey, everyone, welcome to the [ORGANIZATION] one on one webinar. Before I get started, let's quickly cover a few housekeeping items. If you have any questions, we will have a Q and A session at the end, so please submit questions that pops up during the webinar. I have several colleagues on the line to help you answer questions during the Webinar. We have [OCCUPATION], [OCCUPATION], [OCCUPATION] [OCCUPATION], [OCCUPATION] [OCCUPATION], and so on. Everyone on here is on mute except me, so please use the Q amp a feature. This session is up to an hour long, so if you need to drop off, this webinar is recorded and will be shared with you later on. So it's up to you if you'd like to follow along with my examples or sit back and enjoy the show. So my name is [PERSON_NAME] [PERSON_NAME] and I'm the [OCCUPATION] OCCUPATION] at [ORGANIZATION]. You're probably wondering what's our [OCCUPATION] [OCCUPATION] I work in our [ORGANIZATION] [ORGANIZATION] [ORGANIZATION] and I serve as an expert on the key use cases and features of the [ORGANIZATION] platform.
Content Safety Detection
This feature can flag portions of Zoom transcriptions that contain sensitive content such as hate speech, company financials, gambling, weapons, or violence. The full list of what the AssemblyAI API will flag can be found in the API documentation.
Legacy software that attempts to automate this process takes a "blacklist" approach - which looks for specific words (for eg, "gun") in order to flag sensitive content. This approach is extremely error prone and brittle. Take for example "That burrito is bomb".
Since AssemblyAI's Content Safety Detection model is built using State of the Art Deep Learning models, our model looks at the entire context of a word/sentence when deciding when to flag a piece of content or not - we don't rely on error-prone backlist approaches.
Below we review the results of AssemblyAI's Content Safety Detection feature on the above dataset:
Benchmark Your Data
Benchmarking accuracy amongst providers takes both time and money to run on your content. We offer complimentary benchmark reports for any team seeking a transcription solution. To get started with a complimentary benchmark report, you can go here.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts