

In this tutorial, we will build a web app that receives the audio recording of a meeting and automatically generates meeting notes. For this app we will need:
- Streamlit
- Python
- AssemblyAI's Speech-to-Text API
To follow along, go grab the code from our GitHub repository.
The Streamlit Application
As the first step, let's set up the structure of the Streamlit application. This will be the user-facing interface of the application.
import streamlit as st
uploaded_file = st.file_uploader('Please upload a file')
if uploaded_file is not None:
st.audio(uploaded_file, start_time=0)Once the file uploading and audio playback widgets are ready, your app should look like the following image.
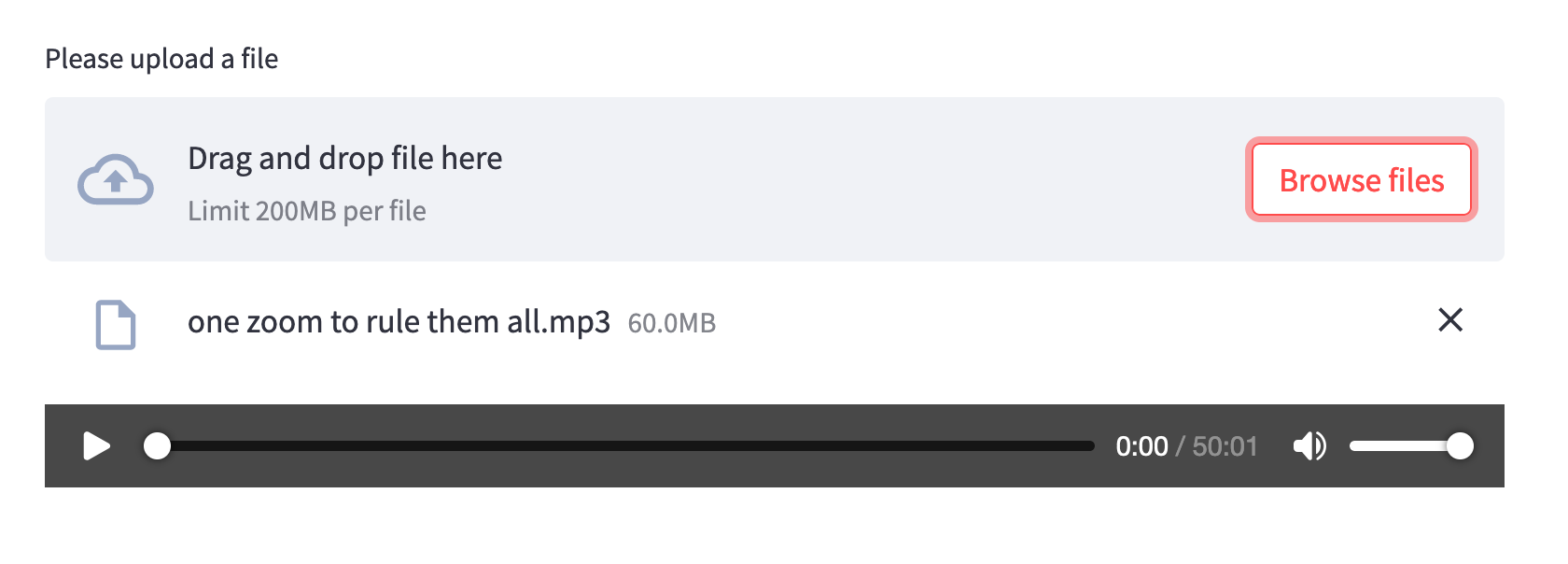
From this point on, we first need to have the audio file transcribed and analyzed before we can add new Streamlit sections.
Getting the themes and chapter summaries
The next step is to send the uploaded audio file to AssemblyAI in order for it to be transcribed and analyzed. We are going to use two different NLP capabilities of AssemblyAI in this app:
AssemblyAI will detect the main themes that are spoken in this meeting and report back the most relevant categories they belong to. On top of that, AssemblyAI will also divide this audio recording into chapters. For each chapter, AssembllyAI will return a short and longer summary of what is being talked about together with the timestamps of when the chapter begins and ends.
To connect to AssemblyAI, we need to set up the headers.
headers = {
"authorization": auth_token,
"content-type": "application/json"
} The auth_token is the API key you get from AssemblyAI to be able to use the API.
And we will collect the code we need to upload and start transcribing the audio in one function.
import requests
def upload_to_AssemblyAI(audio_file):
transcript_endpoint = "https://api.assemblyai.com/v2/transcript"
upload_endpoint = 'https://api.assemblyai.com/v2/upload'
upload_response = requests.post(
upload_endpoint,
headers=headers,
data=audio_file
)
audio_url = upload_response.json()['upload_url']
json = {
"audio_url": audio_url,
"iab_categories": True,
"auto_chapters": True
}
response = requests.post(
transcript_endpoint,
json=json,
headers=headers)
polling_endpoint = transcript_endpoint + "/" + response.json()['id']
return polling_endpointGoing line by line, in this function, we first define the endpoints we would like to connect to at AssemblyAI. Later we make a POST request to the upload endpoint by attaching the authentication header and the file we received from the user. In the response we get from AssemblyAI to this upload request, there is an upload_url that points to the file we just uploaded.
Using this URL, we will make a transcription request. We make the POST request to the transcription endpoint with again the authentication header in tow. This time, though, we also need to attach a JSON variable specifying the location of the audio file and the extra results we expect from AssemblyAI.
In this project, we are asking for the categories ("iab_categories": True) and the chapter summaries ("auto_chapters": True). Using the response we get for the transcription request, we can make a polling endpoint. The polling endpoint is where we will send requests to get the results of the transcription.
Receiving the results from AssemblyAI
Using the function defined above, we now have access to the polling endpoint of our transcription. And using this endpoint, we can inquire about the status of the job we submitted.
polling_endpoint = upload_to_AssemblyAI(uploaded_file)
polling_response = requests.get(polling_endpoint, headers=headers)
status = polling_response.json()['status']We need to wait a while before the transcription is done. That's why setting up a while loop to ask about the status of the job is a good idea. Optionally, you can add a sleep interval to wait between requests.
import time
while status != 'completed':
polling_response = requests.get(polling_endpoint, headers=headers)
status = polling_response.json()['status']
if status == 'completed':
# display results
...
time.sleep(2)Displaying the audio intelligence results
Topic detection
Displaying the results brings us back to Streamlit code. The first section will have the main themes of this meeting. Here is what the AssemblyAI response for Topic Detection looks like.
{
...
"id": "oris9w0oou-f581-4c2e-9e4e-383f91f7f14d",
"status": "completed",
"text": "Ted Talks are recorded live at Ted Conference..."
"iab_categories_result": {
"status": "success",
"results": [
{
"text": "Ted Talks are recorded live at Ted Conference...",
"labels": [
{
"relevance": 0.00561910355463624,
"label": "Education>OnlineEducation"
},
{
"relevance": 0.00465833256021142,
"label": "MusicAndAudio>TalkRadio"
},
{
"relevance": 0.00039072768413461745,
"label": "Television>RealityTV"
},
{
"relevance": 0.00036419558455236256,
"label": "MusicAndAudio>TalkRadio>EducationalRadio"
}
],
"timestamp": {
"start": 8630,
"end": 32990
}
},
...
],
"summary": {
"MedicalHealth>DiseasesAndConditions>BrainAndNervousSystemDisorders": 1.0,
"FamilyAndRelationships>Dating": 0.7614801526069641,
"Shopping>LotteriesAndScratchcards": 0.6330153346061707,
"Hobbies&Interests>ArtsAndCrafts>Photography": 0.6305723786354065,
"Style&Fashion>Beauty": 0.5269057750701904,
"Education>EducationalAssessment": 0.49798518419265747,
"Style&Fashion>BodyArt": 0.19066567718982697,
"NewsAndPolitics>Politics>PoliticalIssues": 0.18915779888629913,
"FamilyAndRelationships>SingleLife": 0.15354971587657928
}
},
} For this project, we are only interested in the summary section. Since it is already in a list, it is easy to extract this information from the response.
st.subheader('Main themes')
with st.expander('Themes'):
categories = polling_response.json()['iab_categories_result']['summary']
for cat in categories:
st.markdown("* " + cat)We save the results to a Python list and display each as a list item inside a Streamlit expander widget.
Chapter summaries
AssemblyAI divided our audio into chapters and provided us with the headline, gist and summary of each chapter. Here is what that response looks like.
{
"audio_duration": 1282,
"confidence": 0.930082104986874,
"id": "ogskorn5o4-8b98-44d6-98ff-7c42a97e033b",
"status": "completed",
"text": "Ted Talks are recorded live at Ted Conference...",
"chapters": [
{
"summary": "In 2 million years, the human brain has nearly tripled in mass. Going from the one and a quarter pound brain of our ancestors here habilis. To the almost three pound meat loaf. One of the main reasons that our brain got so big is because it got a new part called the frontal lobe. And particularly a part called the prefrontal cortex.",
"headline": "One of the main reasons that our brain got so big is because it got a new part called the frontal lobe, and particularly a part called the prefrontal cortex.",
"gist": "The big brain."
"start": 8630,
"end": 146162,
}
...
],
...
} All the information from AssemblyAI's response is useful for this project. So for ease of manipulation, we can first export them to a pandas dataframe.
import pandas as pd
st.subheader('Summary notes of this meeting')
chapters = polling_response.json()['chapters']We want to display the beginning times of each chapter in our user interface. That's why the millisecond values need to be parsed into minutes and seconds. To achieve that, we use the following function.
def convertMillis(start_ms):
seconds = int((start_ms / 1000) % 60)
minutes = int((start_ms / (1000 * 60)) % 60)
hours = int((start_ms / (1000 * 60 * 60)) % 24)
btn_txt = ''
if hours > 0:
btn_txt += f'{hours:02d}:{minutes:02d}:{seconds:02d}'
else:
btn_txt += f'{minutes:02d}:{seconds:02d}'
return btn_txt
chapters_df['start_str'] = chapters_df['start'].apply(convertMillis)
chapters_df['end_str'] = chapters_df['end'].apply(convertMillis)Now the dataframe has two new columns that specify the beginning and ending times of each chapter.
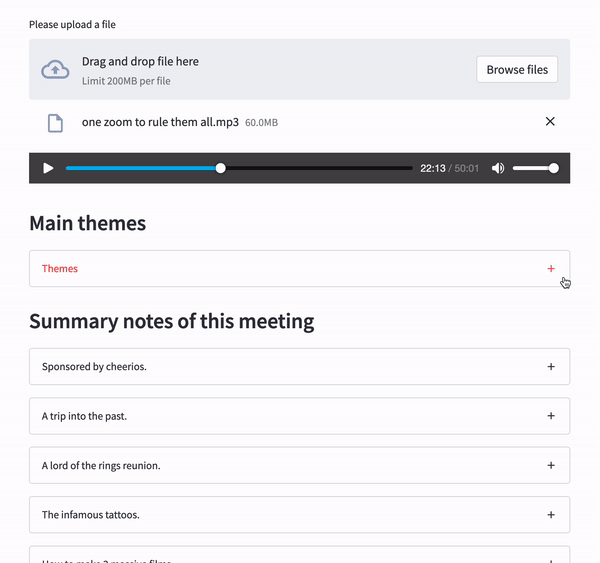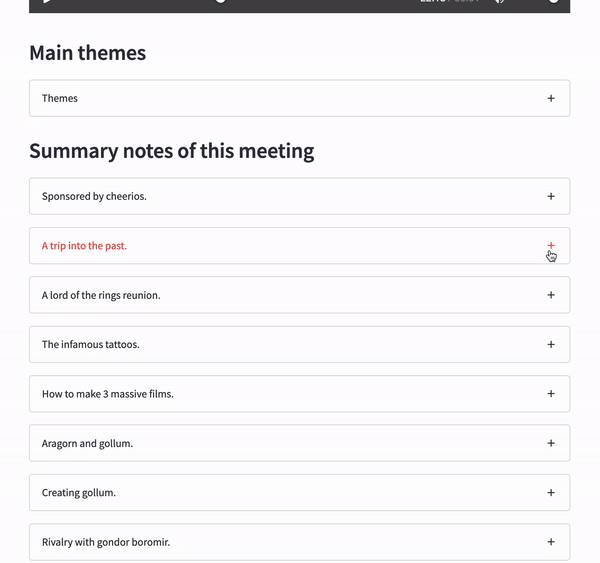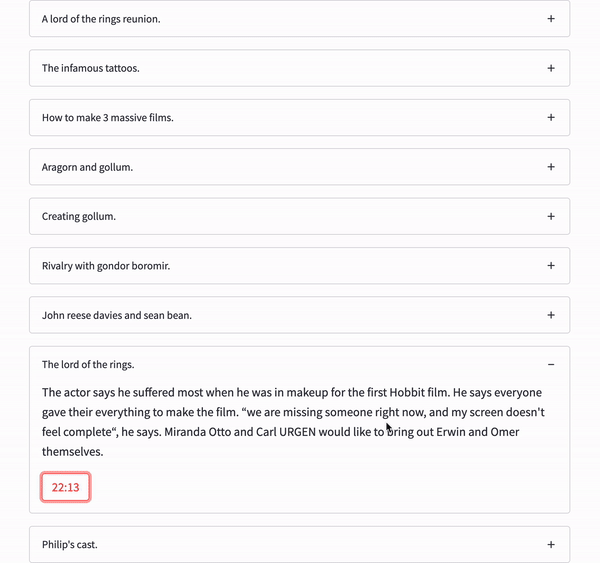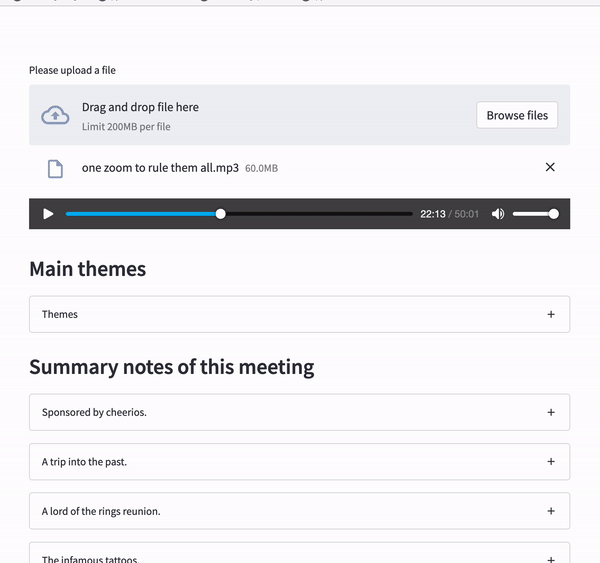
We will display each chapter in its own expander to have a tidy-looking interface. This can be easily done by iterating over the dataframe and creating a new expander widget for each chapter.
for index, row in chapters_df.iterrows():
with st.expander(row['gist']):
st.write(row['summary'])
st.button(row['start_str'])Each chapter will have its gist stated in the expander title. Once expanded, the user will be able to read the longer summary of the chapter and see a button that states the start time of this chapter in the audio.
This is what the app should look like at this point:
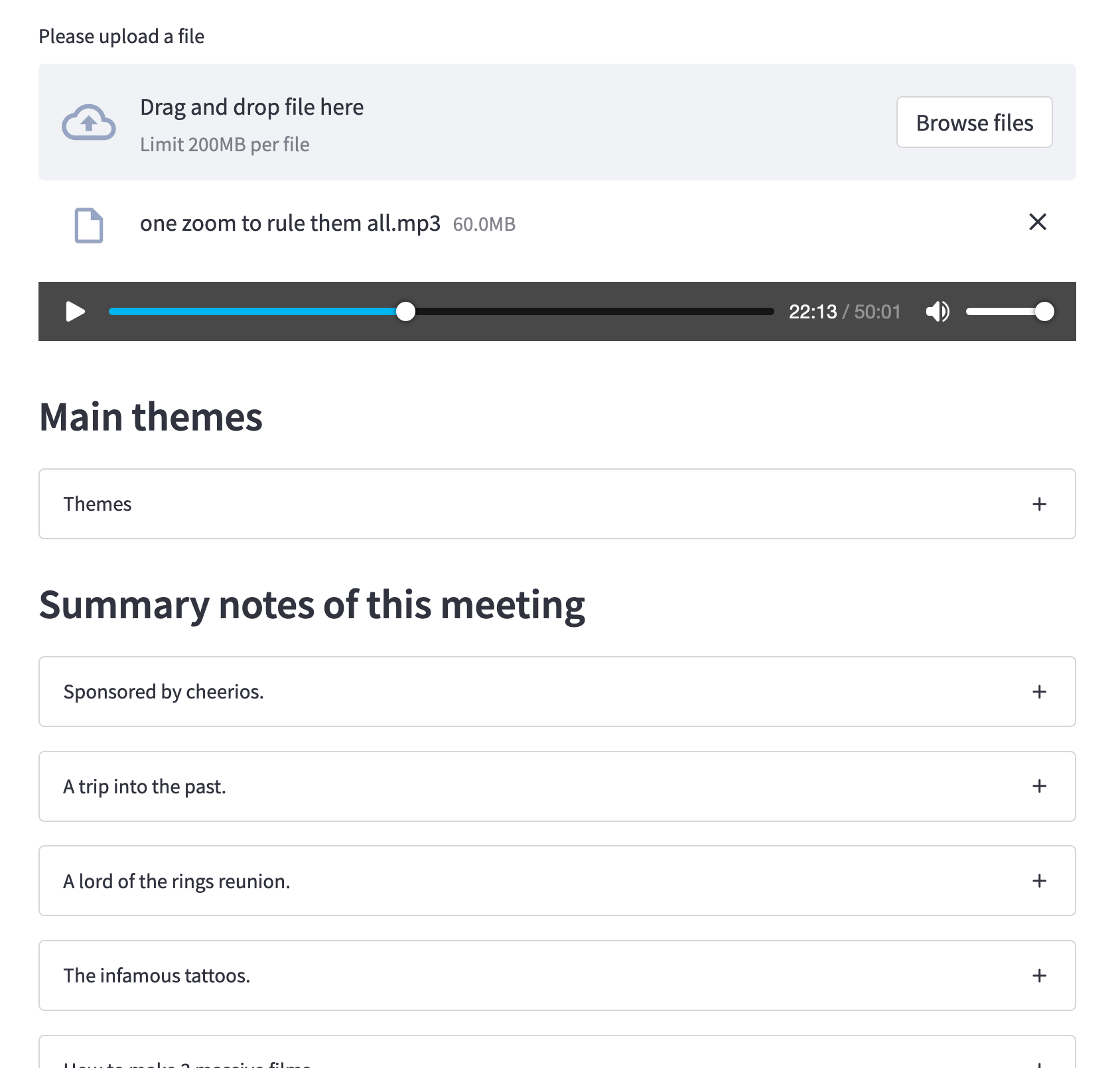
Jump audio start to each chapter
The last touch we need to make is to make the buttons in chapter expanders active. For this, we're going to use Streamlit session states and callback functions.
Let's define a session state variable called start_point, this will determine where the starting point for the audio player should be. This value will be updated with a function called update_start.
if 'start_point' not in st.session_state:
st.session_state['start_point'] = 0
def update_start(start_t):
st.session_state['start_point'] = int(start_t/1000)Update_start takes as parameter a millisecond value, turns it into seconds and updates the session state variable with it. To make this change effective, we will update the audio widget from a previous stage.
st.audio(uploaded_file, start_time=st.session_state['start_point'])And now the last thing to do is to call the update function from the chapter buttons by updating the button creation line.
st.button(row['start_str'], on_click=update_start, args=(row['start'],))Once it is done, the buttons will be able to change the beginning point of the audio player.
If you'd prefer to watch this tutorial you can find the YouTube video here.





