

AI innovation is advancing faster than ever before, spurred by new research and models available such as DALLE-2, Stable Diffusion, and ChatGPT. Top companies are looking to integrate this powerful AI technology to fuel a new generation of intelligent tools and features that empower their customer base and drive market growth.
Companies that process enormous amounts of customer data, for example, are turning to Speech AI technology such as Automatic Speech Recognition (ASR), Audio Intelligence, and Large Language Models to build tools that help their users better understand speech or spoken data.
Many of these users process audio and video data with multiple speakers, like a customer/agent conversation or a virtual meeting with multiple stakeholders, and need to break a transcription into its various speakers in order to accurately process and analyze the conversation.
In this article, we examine how to add these AI-powered speaker labels, also referred to as Speaker Diarization, to a transcription, as well as the benefits, challenges, and use cases of Speaker Diarization.
What is Speaker Diarization?
Speaker Diarization, or speaker labels, answers the question of who spoke when in an audio or video file.
In the field of Automatic Speech Recognition, Speaker Diarization is broken into two components:
- The number of speakers that can be detected in an audio or video file.
- The words or utterances that can be assigned to the appropriate speaker in the audio or video file.
Thanks to modern advances in AI, Speaker Diarization models can automatically assign the correct number of speakers in the file, as well as the utterances, words, and phrases associated with that speaker.
The speaker labels are typically assigned as “Speaker A,” “Speaker B,” etc., and remain consistent throughout the transcription text.
What are the benefits of Speaker Diarization?
Speaker Diarization has many benefits. First, it makes the text from a transcribed audio and video file much easier to digest, especially if there are multiple speakers.
For example, take a look at this basic transcription text without Speaker Diarization:
But how did you guys first meet and how do you guys know each other? I
actually met her not too long ago. I met her, I think last year in
December, during pre season, we were both practicing at Carson a lot.
And then we kind of met through other players. And then I saw her a few
her last few torments this year, and we would just practice together
sometimes, and she's really, really nice. I obviously already knew who
she was because she was so good. Right. So. And I looked up to and I met
her. I already knew who she was, but that was cool for me. And then I
watch her play her last few events, and then I'm actually doing an
exhibition for her charity next month. I think super cool. Yeah. I'm
excited to be a part of that. Yeah. Well, we'll definitely highly
promote that. Vania and I are both together on the Diversity and
Inclusion committee for the USDA, so I'm sure she'll tell me all about
that. And we're really excited to have you as a part of that tournament.
So thank you so much. And you have had an exciting year so far. My
goodness. Within your first WTI 1000 doubles tournament, the Italian
Open.Congrats to that. That's huge. Thank you.And then look at this transcription text with Speaker Diarization:
<Speaker A> But how did you guys first meet and how do you guys know each
other?
<Speaker B> I actually met her not too long ago. I met her, I think last
year in December, during pre season, we were both practicing at Carson a
lot. And then we kind of met through other players. And then I saw her a
few her last few torments this year, and we would just practice together
sometimes, and she's really, really nice. I obviously already knew who
she was because she was so good.
<Speaker A> Right. So.
<Speaker B> And I looked up to and I met her. I already knew who she
was, but that was cool for me. And then I watch her play her last few
events, and then I'm actually doing an exhibition for her charity next
month.
<Speaker A> I think super cool.
<Speaker B> Yeah. I'm excited to be a part of that.
<Speaker A> Yeah. Well, we'll definitely highly promote that. Vania and
I are both together on the Diversity and Inclusion committee for the
USDA. So I'm sure she'll tell me all about that. And we're really
excited to have you as a part of that tournament. So thank you so much.
And you have had an exciting year so far. My goodness. Within your first
WTI 1000 doubles tournament, the Italian Open. Congrats to that. That's
huge.
<Speaker B> Thank you.The second example is much easier to read at a glance.
Second, Speaker Diarization opens up significant analytical opportunities for companies. By identifying each speaker, product teams can build tools that analyze each speaker’s behaviors, identify patterns and trends, and more that can then inform business strategy.
What are the challenges and limitations of Speaker Diarization?
Despite recent advances, some challenges and limitations of Speaker Diarization models remain:
- The most advanced Speaker Diarization models are designed for asynchronous transcription while real-time Speaker Diarization requires a different type of model.
- Speakers need to talk for more than 30 seconds (in total) to be accurately detected by a Speaker Diarization model. If the talk time is less than 15 seconds, the model may assign the speaker as “Unknown” or merge the speaker’s words with a more dominant speaker in the file.
- Well-defined conversations with clear turn-taking will be more accurately labeled than a conversation with over-talking or interrupting.
- Background noise can affect the model’s ability to appropriately assign speaker labels.
- Overtalk, or when speakers talk over one another, may result in an additional imaginary speaker being assigned.
Speaker Diarization in enterprise settings
Now that we have a basic understanding of what Speaker Diarization is and some of its benefits and limitations, we will examine top Speaker Diarization use cases and best practices for adding Speaker Diarization to enterprise applications.
Use cases for Speaker Diarization
Top companies are already building with Speaker Diarization to create powerful transcription and analysis tools for their customers.
Here's a look at how businesses are currently leveraging Speech AI:
Virtual Meetings and Hiring Intelligence Platforms
With Speaker Diarization, virtual meeting and hiring intelligence platforms can create useful post-meeting/interview transcripts broken down by speaker to serve their users.
Then, the platforms can offer additional AI analysis on top of this transcription data, such as meeting summaries, analysis by speaker, or additional insights.
AI-powered meeting recorder Grain, for example, uses transcription and Speaker Diarization to help its customers realize significant time savings in note-talking, record-keeping, and meeting analysis.

Hiring intelligence platform Screenloop added AI-powered transcription and Speaker Diarization to cut the time spent on manual tasks by 90% for its customers. Additional analysis of each conversation also helps its customers perform more effective training, reduce time-to-hire, and reduce hiring bias.
Conversation Intelligence
Speaker Diarization also helps augment Conversational Intelligence platforms by providing users with a readable text of each conversation.
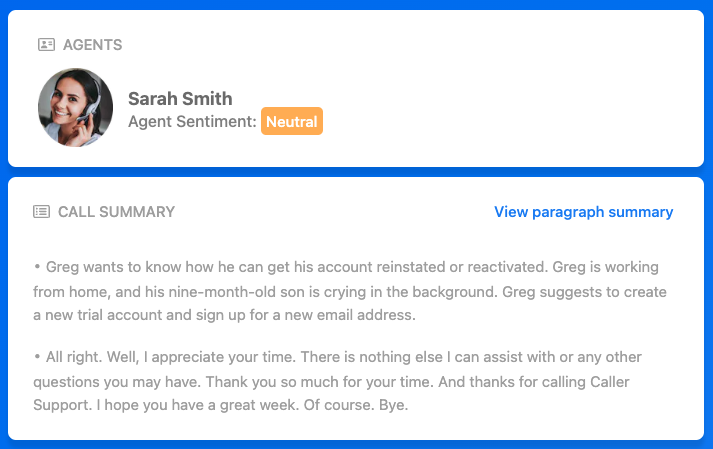
Then, these conversations can be more easily summarized using an AI summarization model, as shown above.
Sentiment Analysis models can also be used to automatically flag changes in sentiments during a conversation that suggest buying indicators or potential problems.

Jiminny, a leading Conversation Intelligence, sales coaching, and call recording platform, incorporated transcription and Speaker Diarization to serve as the foundation for additional AI analysis tools–helping its customers secure a 15% higher win rate.
CallRail, a lead intelligence software company, integrated AI models, including Speaker Diarization, to double the number of customers using its Conversational Intelligence product.
AI Subtitle Generators
AI subtitle generators automatically transcribe audio and video files and add textual subtitles directly onto the specified video. Speaker Diarization models can be used to break down these subtitles by speakers, helping users more easily meet compliance and accessibility requirements, as well as making the videos easier to consume for those who wish to view them without sound.

Call Centers
Call Center platforms are integrating Speech AI systems, including Speaker Diarization, to optimize workflows and realize impressive results for their customers, such as:
- Uncovering intelligent insights that increase agent occupancy.
- Discovering critical customer insights about satisfaction, complaints, brand strength, churn risk, competitor analysis, and more.
- Improving quality monitoring by helping managers review more agent/customer conversations in a shorter time frame.
Sales Intelligence
With a complete Speech AI system that includes Speaker Diarization, sales intelligence platforms are building tools and features that let users perform intensive analysis on all conversational data they process.
Similar to call coaching, sales intelligence platforms that add Speech AI can transcribe and analyze conversations to determine a prospect’s past behavior and preferences, as well as to predict future behaviors. This analysis can then be used to create personalized outreach or help users prioritize which leads are more likely to convert.
Speech AI can also be used to automatically recap a list of action items for the representative to take once the call is complete.
Best practices for adding Speaker Diarization to enterprise platforms
Keep in mind that Speaker Diarization models will work best when each speaker speaks for at least 30 uninterrupted seconds. If a speaker only utters short phrases, such as “Right,” or “Yes,” the model may struggle to associate these utterances with a separate speaker.
Also, there is typically a limitation of the number of speakers a Speaker Diarization model can detect. For example, the AssemblyAI Speaker Diarization model can detect up to 10 speakers in any audio or video file.
If the enterprise platform is going to be processing a lot of noisy audio/video files, or files with greater than 10 speakers, Speaker Diarization is going to be difficult to successfully integrate.
However, for most enterprise platforms–such as call centers, hiring platforms, or sales intelligence–Speaker Diarization can be an extremely useful addition to any AI-powered transcription or analysis tool.
How to add Speaker Diarization to transcription and Generative AI tools
Speaker Diarization is a critical component of any complete Speech AI system. For example, Speaker Diarization is included in AssemblyAI’s Core Transcription offering and users wishing to add speaker labels to a transcription simply need to have their developers include the speaker_labels parameter in their request body and set it to true. See a more detailed description of how to do this in the AssemblyAI docs.
The power of Speech AI
Speaker Diarization is a critical component of any Speech AI system, and one that can have impactful implications for audio/video transcription and analysis.
By building with this Speech AI technology, companies can create industry-leading tools and features that generate transformative results for their customers.






