
Yesterday, OpenAI released its Whisper speech recognition model. Whisper joins other open-source speech-to-text models available today - like Kaldi, Vosk, wav2vec 2.0, and others - and matches state-of-the-art results for speech recognition.
In this article, we’ll learn how to install and run Whisper, and we’ll also perform a deep-dive analysis into Whisper's accuracy, inference time, and cost-to-run.
How to Run OpenAI's Whisper
In this section, we'll learn how to install and use Whisper. You can jump down to the Whisper analysis or to a more complicated Whisper advanced usage if you're already up-and-running with Whisper.
Step 1: Install Dependencies
Whisper requires Python3.7+ and a recent version of PyTorch (we used PyTorch 1.12.1 without issue). Install Python and PyTorch now if you don't have them already.
Whisper also requires FFmpeg, an audio-processing library. If FFmpeg is not already installed on your machine, use one of the below commands to install it.
# Linux
sudo apt update && sudo apt install ffmpeg
# MacOS
brew install ffmpeg
# Windows
chco install ffmpegAdditional Details
The MacOS installation command requires Homebrew, and the Windows installation command requires Chocolatey, so make sure to install either tool as needed.
Finally, if using Windows, ensure that Developer Mode is enabled. In your system settings, navigate to Privacy & security > For developers and turn the top toggle switch on to turn Developer Mode on if it is not already.

Step 2: Install Whisper
Now we are ready to install Whisper. Open up a command line and execute the below command to install Whisper:
pip install git+https://github.com/openai/whisper.git Step 3: Run Whisper
Command Line
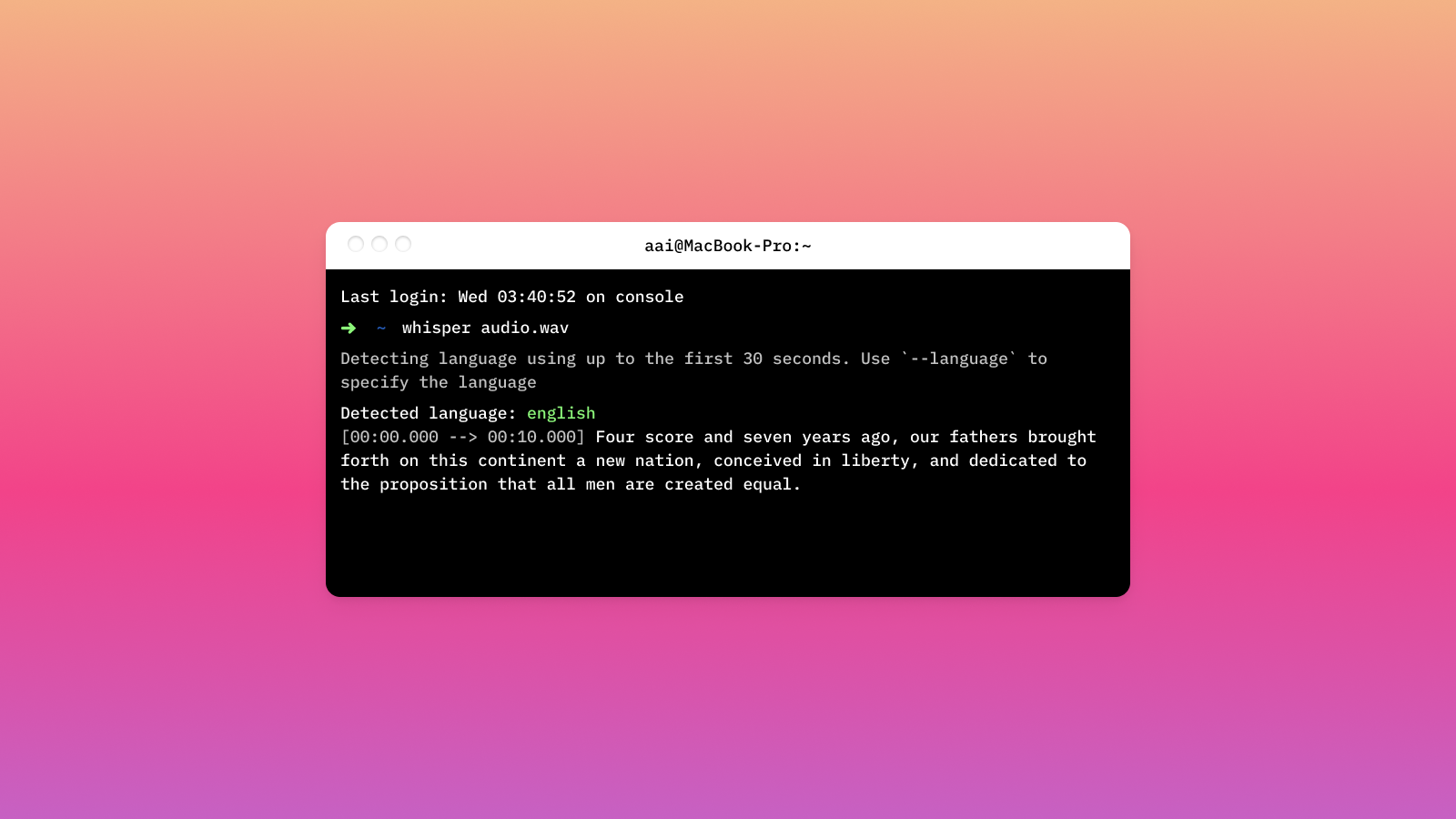
First, we'll use Whisper from the command line. Simply open up a terminal and navigate into the directory in which your audio file lies. We will be using a file called audio.wav, which is the first line of the Gettysburg Address. To transcribe this file, we simply run the following command in the terminal:
whisper audio.wavThe output will be displayed in the terminal:
(venv) C:\Users> whisper audio.wav
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: english
[00:00.000 --> 00:10.000] Four score and seven years ago, our fathers brought forth on this continent a new nation, conceived in liberty, and dedicated to the proposition that all men are created equal.The transcription is also saved to audio.wav.txt, along with a file audio.wav.vtt to be used for closed captioning.
Python
Using Whisper for transcription in Python is very easy. Simply import whisper, specify a model, and transcribe the audio.
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.wav")The transcription text can be access with result["text"]. The result object itself contains other useful information:
{
"text": " Four score and seven years ago, our fathers brought forth on this continent a new nation, conceived in liberty, and dedicated to the proposition that all men are created equal.",
"segments": [
{
"id": 0,
"seek": 0,
"start": 0.0,
"end": 10.0,
"text": " Four score and seven years ago, our fathers brought forth on this continent a new nation, conceived in liberty, and dedicated to the proposition that all men are created equal.",
"tokens": [
50364,
7451,
6175,
...,
2681,
13,
50864
],
"temperature": 0.0,
"avg_logprob": -0.1833780391796215,
"compression_ratio": 1.3858267716535433,
"no_caption_prob": 0.05988641083240509
}
],
"language": "en"
}OpenAI Whisper Analysis
The below figure from the Whisper paper compares Whisper's accuracy, using Word-Error-Rate (WER), to current state-of-the-art speech recognition models. As you can see, Whisper reports achieving state-of-the-art results, which is an exciting development for the field of speech recognition, especially given that Whisper is an open-source model.
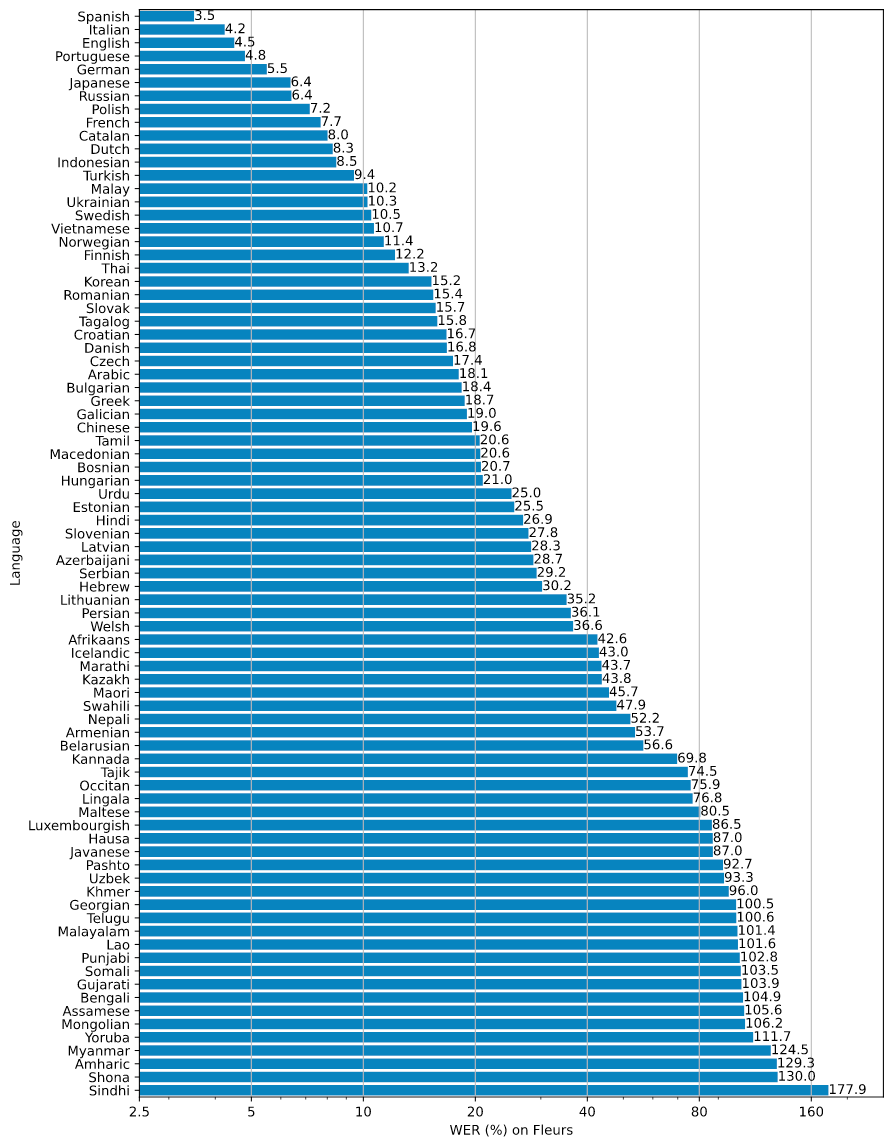
While these results are exciting, speech recognition remains an open problem - especially for non-English languages. The below figure reports Whisper's Word-Error-Rates for each supported language. While Whisper achieves state-of-the-art results on several Romance languages, German, Japanese, and more, performance is comparatively lacking for other languages.
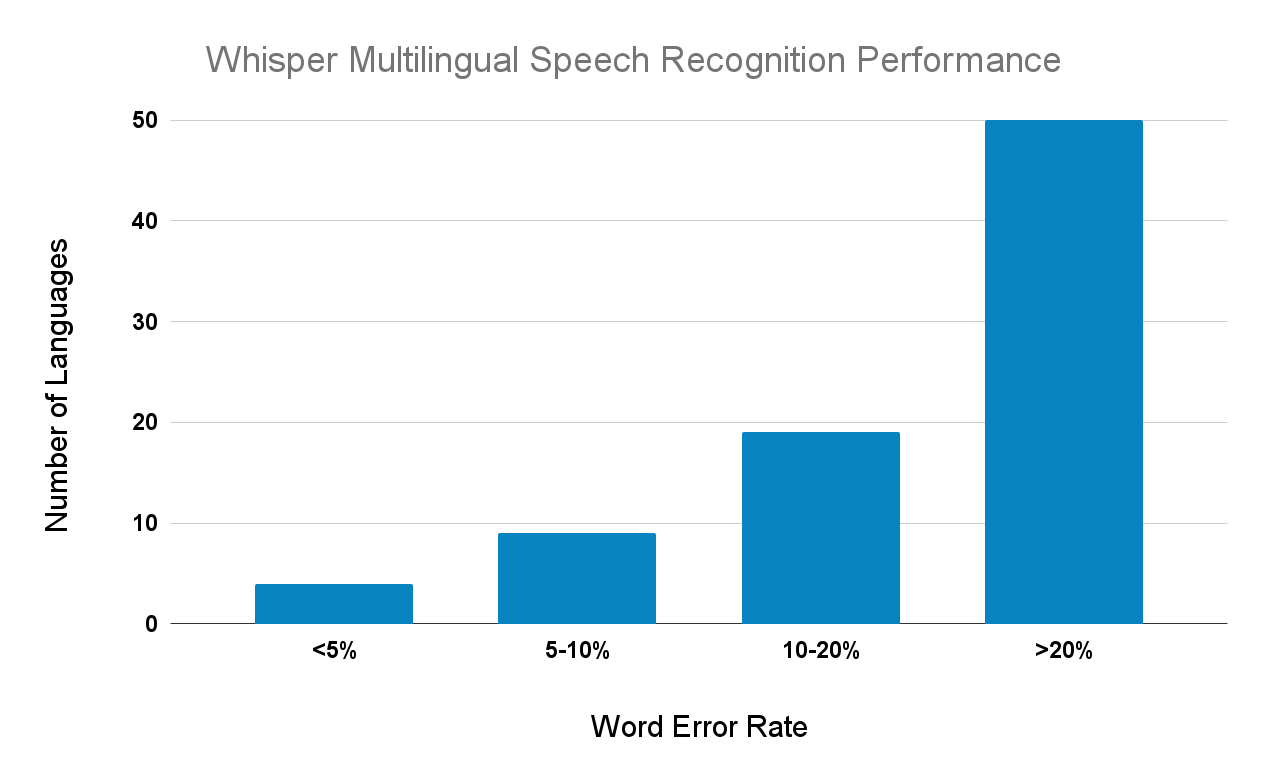
Below we see the distribution of languages as a function of word error rate. Of the 82 languages in the plot above, 50 of them have Word-Error-Rates greater than 20%,
Anecdotal Comparisons
At Assembly, our API is powered by a state-of-the-art Conformer-CTC model trained on ~100,000 hours of labeled data. To explore Whisper's accuracy, we decided to compare Whisper with our model in a few side-by-side comparisons.
First, we show a comparison of the Micro Machines example from the Whisper announcement post:
AssemblyAI
This is a Micro Machine man presenting the most midget miniature motorcade of Micro Machine. This one has dramatic details, perfect turn, precision paint jobs, plus incredible Micro Machine pocket place that says a police station, fire station, restaurant service station, and more. Perfect pocket portable to take any place. And there are many miniature places to play with. Each one comes with its own special edition Micro Machine vehicle and fun, fantastic features that miraculously moved OOH. Raise the boltless at the airport marina, man the gun turret at the army base. Clean your car at the car wash. Raise the tulbridge. And these places fit together to form a Micro Machine world. Micro Machine pocket places that's tremendously tiny, so perfectly precise, so dazzlingly detailed, you'll want to pocket them all. Micro Machines are microschin pocket place that sold separately from glue. The smaller they are, the better they are.
Google Speech-to-Text
this is Michael presenting the most midget miniature motorcade of micro machine which one has dramatic details terrific current position paying jobs plus incredible Michael Schumacher place that's there's a police station Fire Station restaurant service station and more perfect bucket portable to take any place and there are many many other places to play with of each one comes with its own special edition Mike eruzione vehicle and fun fantastic features that miraculously move raise the boat looks at the airport Marina men the gun turret at the Army Base clean your car at the car wash raised the toll bridge and these play sets fit together to form a micro machine world like regime Parker Place that's so tremendously tiny so perfectly precise so dazzlingly detail Joanna pocket them all my questions are microscopic play set sold separately from glue the smaller they are the better they are
Whisper
This is the Micro Machine Man presenting the most midget miniature motorcade of Micro Machines. Each one has dramatic details, terrific trim, precision paint jobs, plus incredible Micro Machine Pocket Play Sets. There's a police station, fire station, restaurant, service station, and more. Perfect pocket portables to take any place. And there are many miniature play sets to play with, and each one comes with its own special edition Micro Machine vehicle and fun, fantastic features that miraculously move. Raise the boatlift at the airport marina. Man the gun turret at the army base. Clean your car at the car wash. Raise the toll bridge. And these play sets fit together to form a Micro Machine world. Micro Machine Pocket Play Sets, so tremendously tiny, so perfectly precise, so dazzlingly detailed, you'll want to pocket them all. Micro Machines are Micro Machine Pocket Play Sets sold separately from Galoob. The smaller they are, the better they are.
The second example is a clip from a podcast
AssemblyAI
One of them is I made the claim I think most civilizations going from simple bacteria like things to space, colonizing civilizations, they spend only a very tiny fraction of their life being where we are, that I could be wrong about. The other one I could be wrong about is quite different statements that I think that actually I'm guessing that we are the only civilization in our observable universe from which light has reached us so far that's actually gotten far enough to invent telescopes. So let's talk about maybe both of them in turn, because they really are different. The first one, if you look at N, equals one the data for we have on this planet. So we spent four and a half billion years fussing around on this planet with life. And most of it was pretty lame stuff from an intelligence perspective. Bacteria and then the dinosaurs spent then the things greatly accelerated, and the dinosaurs spent over 100 million years stomping around here without even inventing smartphones. And then very recently, we've only spent 400 years going from Newton to us, right? Yeah. In terms of technology. And look what we've done even.
Google Speech-to-Text
one of them is I made the claim I think most civilizations going from simple bacteria are like things to space space colonizing civilization they spend only a very very tiny fraction of their other other life being where we are. I could be wrong about the other one I could be wrong about this quite different statements and I think that actually I'm guessing that we are the only civilization in the observable universe from which life has weeks or so far that's actually gotten far enough to men's telescopes but if you look at the antique was one of the date of when we have on this planet right so we spent four and a half billion years fucking around on this planet with life we got most of it was it was pretty lame stuff from an intelligence perspective he does bacteria and then the dinosaurs spent then the things right The Accelerated by then the dinosaurs spent over a hundred million a year is stomping around here without even inventing smartphone and and then very recently I only spent four hundred years going from Newton to us right now in terms of technology and look what we don't even
Whisper
One of them is, I made the claim, I think most civilizations, going from, I mean, simple bacteria like things to space colonizing civilizations, they spend only a very, very tiny fraction of their life being where we are. That I could be wrong about. The other one I could be wrong about is the quite different statement that I think that actually I'm guessing that we are the only civilization in our observable universe from which light has reached us so far that's actually gotten far enough to invent telescopes. So let's talk about maybe both of them in turn because they really are different. The first one, if you look at the N equals one, the date of one we have on this planet, right? So we spent four and a half billion years f**king around on this planet with life, right? We got, and most of it was pretty lame stuff from an intelligence perspective, you know, the dinosaur has spent, then the things were actually accelerated, right? Then the dinosaur has spent over a hundred million years stomping around here without even inventing smartphones. And then very recently, you know, it's only spent four hundred years going from Newton to us, right? In terms of technology, and we've looked at what we've done even.
The final audio file is a board of directors meeting
AssemblyAI
East Side charter. I'm sorry. Go now. Okay. I'd like to call to order a special joint meeting of the board of directors of Eastside Charter School and Charter School of Newcastle. It is 535. I'd like to call the role. And attending for East Side Charter School we have Ms. Stewart, Mr. Sawyer, Dr. Gordon, Mr. Hare, Ms. Sims, Mr. Veal, Ms. Fortunato, Ms. Tieno and Mr. Humphrey. And attending for Charter School in Newcastle. We have Dr. Bailey, Ms. Johnson, mr. Taylor, mr. McDowell, mr. Preston and Mr. Humphrey. I miss anybody, and I do not believe anybody is on the conference line. As there is no public items on our agenda. I would like a motion from a Charter School of Newcastle board meeting to move into executive discussion to talk about personnel matters. I'll make that motion. Thank you, Mr. Second, Mr. Preston. All Charter School and Newcastle board members in favor, please say aye. Aye. Any opposed? Motion unanimous. I would ask the same. Put the same question to East Side Charter School. Thank you, MSN. Is there a second? Thank you, Mr. Veal. All those in favor, please say aye. Any opposed? Okay, so we move from public session to executive session at 535. We're back in public session. You just read your message. Okay, we're now back in public session at 715. And there being no further business, I will entertain a motion from Charter School Newcastle to adjourn. Thank you. Is there a second? Thank you. All in favor please say aye. Opposed? Charter School. Adjourn EastWater Charter School for the same motion. Thank you. Thank you, Ms. Mitchell. All those in favor, please say aye. Opposed? Motion carries. Meeting adjourned. Thank you all very much.
Google Speech-to-Text
I'd like to call to order a special joint meeting of the board of directors of Eastside charter school is Charter School of New Castle it is 5:35 I'd like to call the roll and they're sending for eastside Charter School dr. Gordon sister here I miss them Mr Vilnius Fortunato misiano and Mr Humphrey attending for Charter School of New Castle we have dr. Bailey is Johnson mr. Taylor Miss McDowell mr. Preston and mr. Humphries is anybody and I do not believe anybody is on the conference line is there is no public items on our agenda I would like a motion from a charter school of New Castle board meeting to move into executive discussion to talk about personal matters call Turtle Newcastle board members in favor please say I charter school all those in favor please say I so we moved from public session to Executive session at 5:35 okay it is 750 + can you just leave it here at 7:15 and there being no further business I was in between the motion soundtrack to a New Castle to adjourn thank you is there s you all in favor please say I referred her to let her know I will be set at her school for the promotion of a second long does it take a PPI motion carry beating jiren thank you all very much./p>
Whisper
I'd like to call to order a special joint meeting of the board of directors of East Side Charter School in Charter School of Newcastle. It is 535. I'd like to call the role and attending for East Side Charter School. We have Mr. Stewart, Mr. Sawyer, Dr. Gordon, Mr. Hair, Ms. Thames, Mr. Veal, Ms. Portionato, Ms. Dienno, and Mr. Humphrey. And attending for Charter School of Newcastle, we have Dr. Bailey, Ms. Johnson, Mr. Taylor, Mr. McDowell, Mr. Preston, and Mr. Humphrey. I do not believe anybody is on the conference line. As there is no public items on our agenda, I would like a motion from a Charter School of Newcastle board meeting to move into executive discussion to talk about personnel matters. I'll make that motion. Thanks, Mr. Preston. All Charter School of Newcastle board members in favor, please say aye. Aye. Aye. Any opposed? Motion unanimous. I would ask the same question to East Side Charter School. Thank you, Mr. Thames. Is there a second? Thank you, Mr. Veal. All those in favor, please say aye. Aye. Any opposed? Okay. So we move from public session to executive session at 535. Okay, we're back. Okay. It is now 715. And we're back in public session. You just need to carry my phone. Okay. So we are now back in public session at 715. And they're being a further business. I will then be paying the motion from Charter School of Newcastle to adjourn. Thank you. Is there a second? Thank you. All in favor, please say aye. Aye. Any opposed? Charter School adjourned. I will ask East Side Charter School for the same motion as usual. Thank you. Mr. Thames, Mr. Mitchell, all those in favor, please say aye. Any opposed? Motion carries. Meeting adjourned. Thank you all very much.
As we can see, Whisper performs very well and is a fantastic addition to the available state-of-the-art options for speech recognition today.
Whisper Inference Time
Whisper is available in five sizes - tiny, base (default), small, medium, and large - getting more accurate with size. The large model, therefore, has the best accuracy and is the model used in benchmarks reported in the paper and in the graphs above. Whisper can be used on both CPU and GPU; however, inference time is prohibitively slow on CPU when using the larger models, so it is advisable to run them only on GPU.
The Micro Machines example was transcribed with Whisper on both CPU and GPU at each model size, and the inference times are reported below. First, we see the results for CPU (i5-11300H)
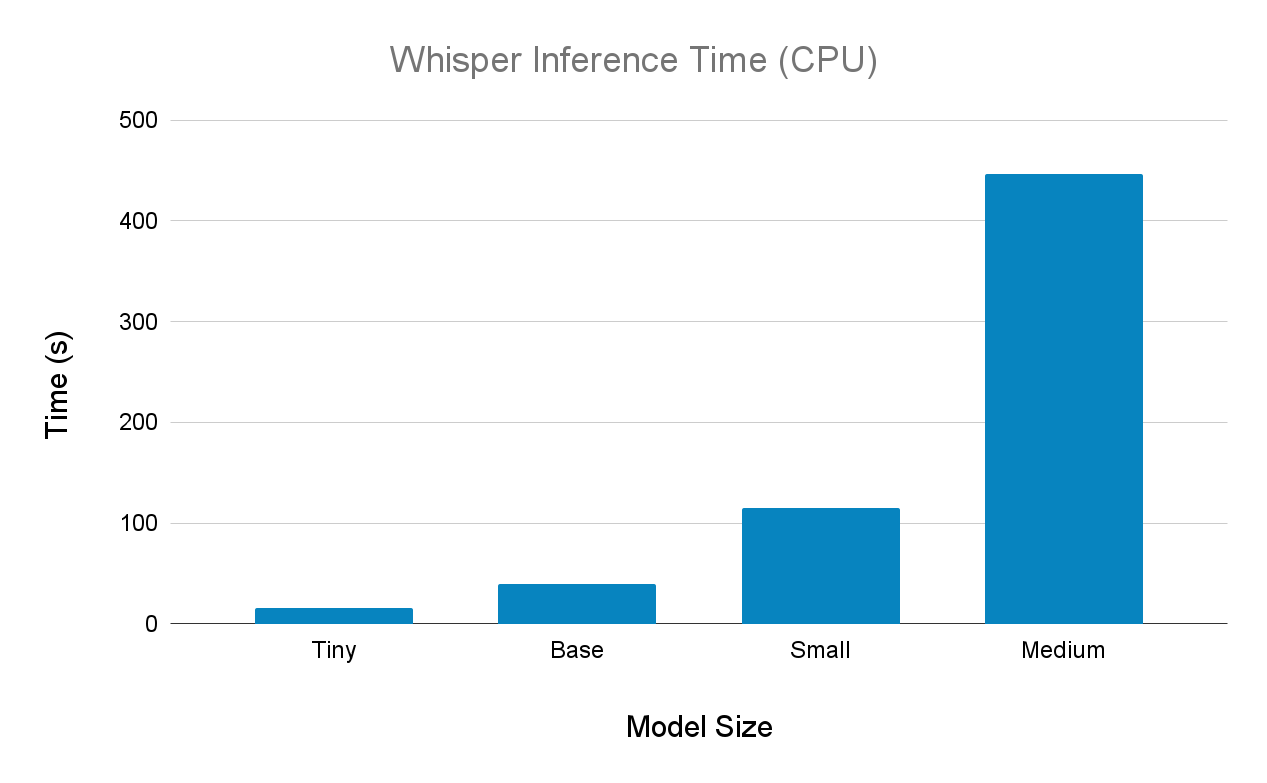
Next, we have the results on GPU (high RAM GPU Colab environment)
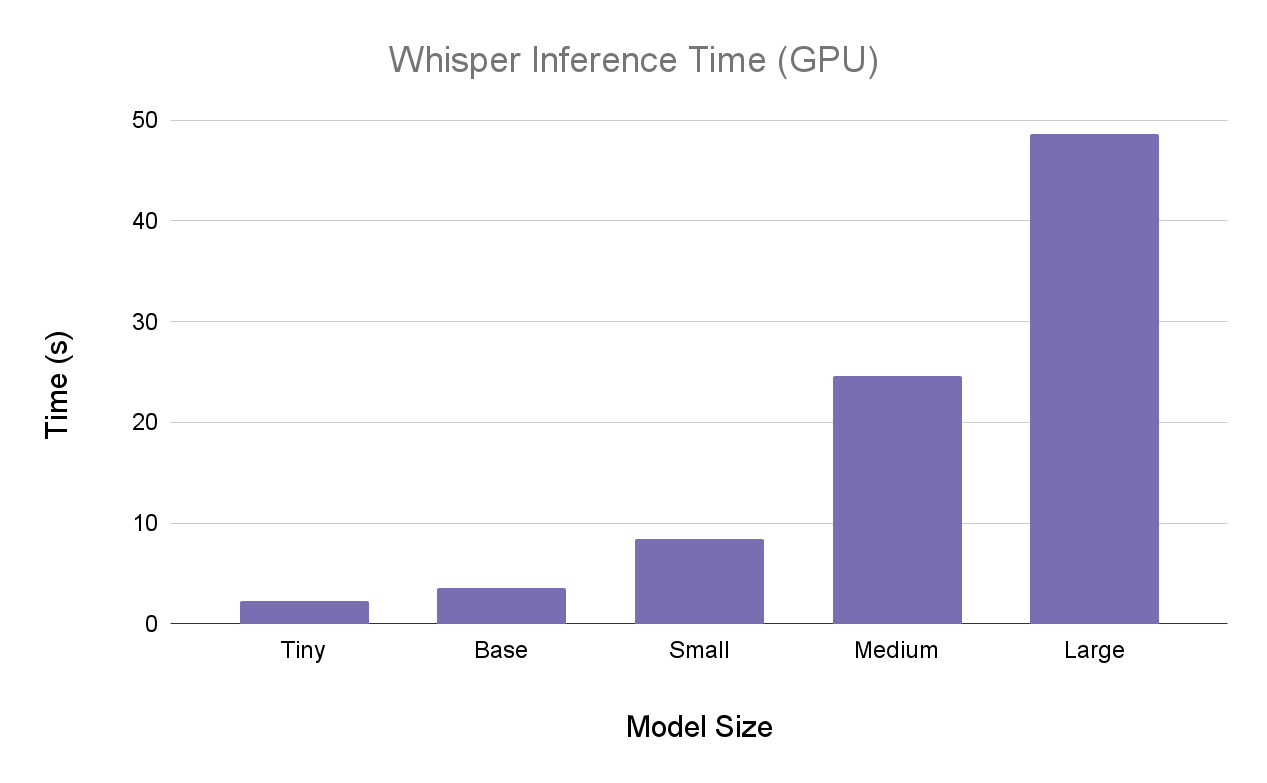
Here are the same results side-by-side
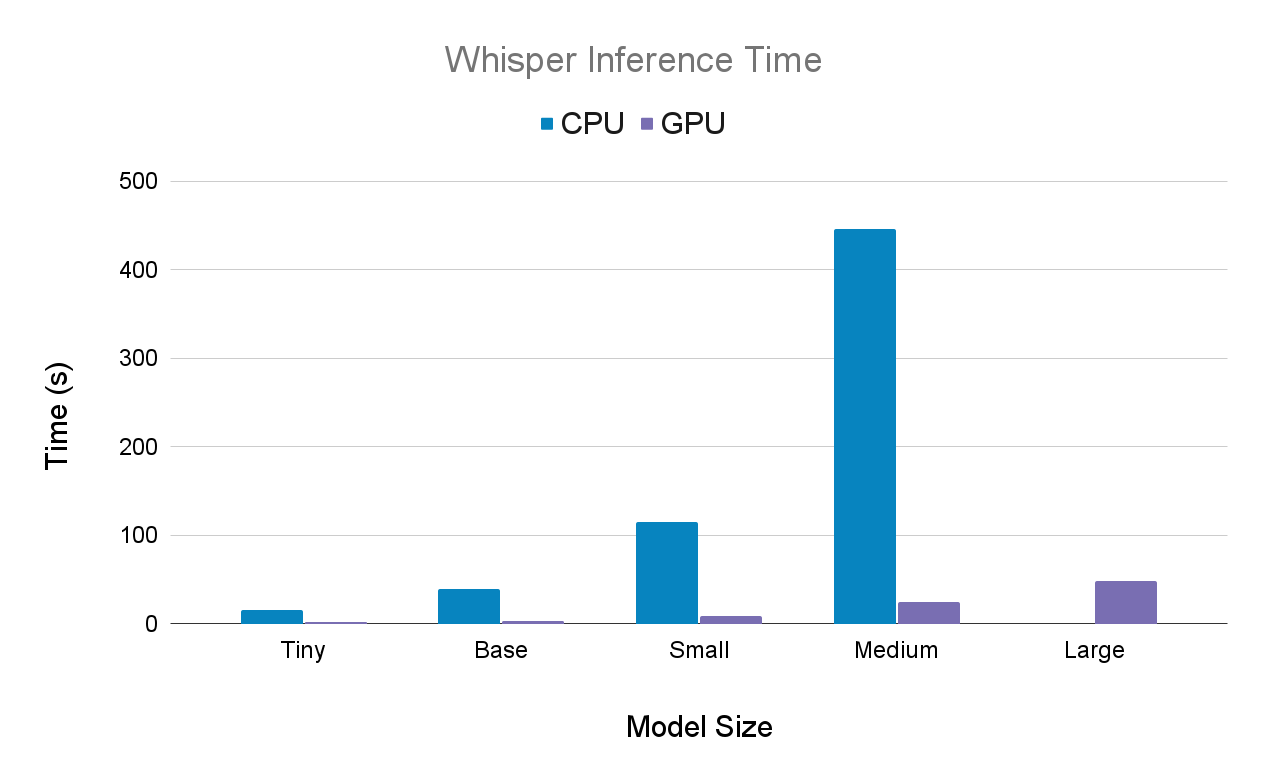
Implementation Detail
If you run into the RuntimeError "slow_conv2d_cpu" not implemented for 'Half' when using Whisper on CPU, you will have to use Whisper's low-level API in Python and replace options = whisper.DecodingOptions() with options = whisper.DecodingOptions(fp16=False).
Cost to Run Whisper
We provide the cost to transcribe 1,000 hours of audio using Whisper in GCP (1x A100 40 GB) for each model size using different batch sizes, the values of which can be found in the legend.
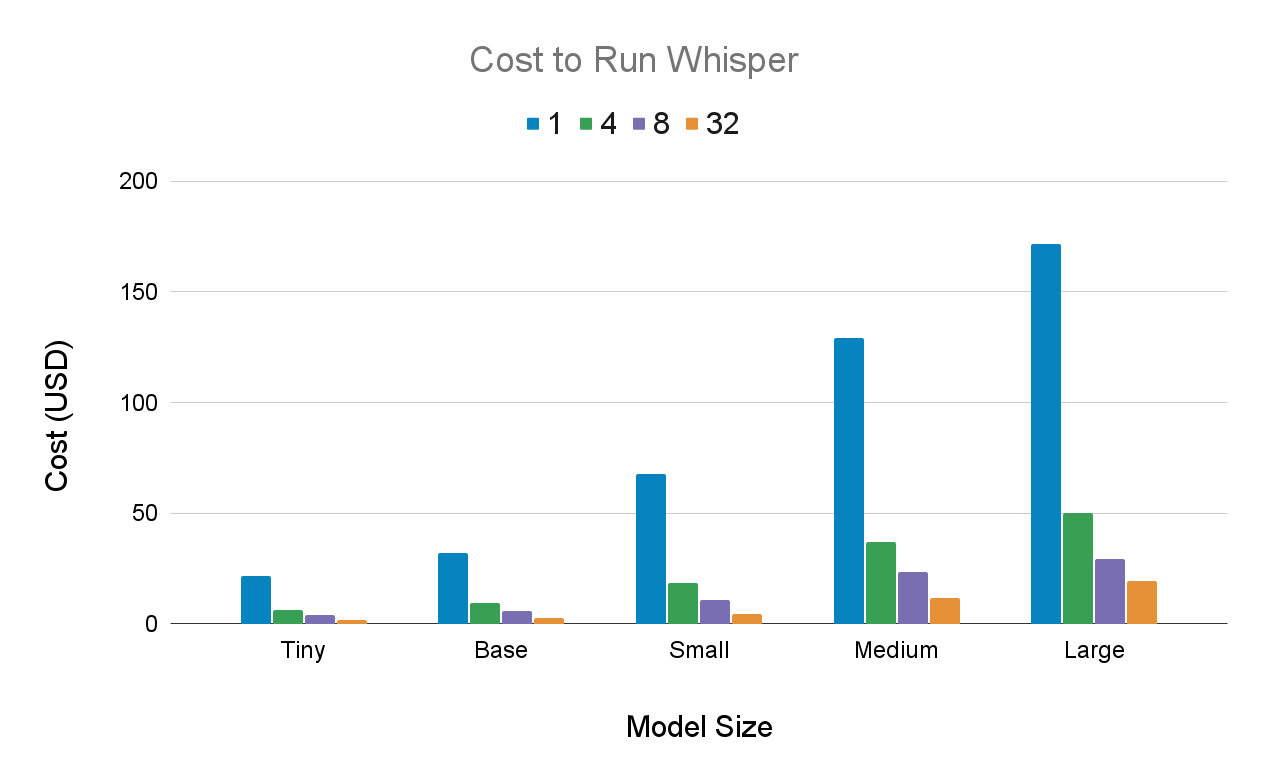
The costs in this graph depict the raw compute cost to run Whisper after it has been deployed. The costs do not include headcount for building out relevant infrastructure, fixing model bugs, or improving and updating the model. To continuously keep performance competitive, a dedicated research or research engineering team would be required.
Final Words
Our above analysis showed that Whisper achieves state-of-the-art results for speech recognition in several languages. Whisper will serve as a valuable tool to researchers and hackers alike, both for its accuracy and ease-of-use compared to other open-source options. Whisper's performance stems in part from its compute intensity, so applications requiring the larger, more powerful versions of Whisper should make sure to run Whisper on GPU, whether locally or in the cloud.
Whisper Advanced Usage
We got acquainted with Whisper in the How to Run OpenAI's Whisper section above. For a more complicated example, we'll review a modified version of the multilingual ASR notebook. Execute the following commands to download the example code and install the necessary requirements:
git clone https://github.com/AssemblyAI-Examples/whisper-multilingual.git
cd whisper-multilingual
pip install -r requirements.txt
Next, simply run python main.py to transcribe and translate several Korean audio files into English. Each datum will take about 3 minutes to process on CPU. We use a total of 10 data points, so let the process run in the background while we examine the main.py code.
First, we perform all necessary imports, and then define a class that will be used to download and store the audio data. The details of this class are not relevant, so they have been omitted for the sake of brevity.
import io
import os
import torch
import pandas as pd
import urllib
import tarfile
import whisper
from scipy.io import wavfile
from tqdm import tqdm
class Fleurs(torch.utils.data.Dataset):
passNext, we set some parameters for displaying the result with pandas, set the device to use for inference, and then set the variables which specify the language of the audio. The first the Korean language code used to download the data, and the latter is the Korean language code used with the Whisper model.
# Display options for pandas dataset
pd.options.display.max_rows = 100
pd.options.display.max_colwidth = 1000
# Set inference device
device = "cuda" if torch.cuda.is_available() else "cpu"
# Set language (korean)
language_google = "ko_kr"
language_whisper = "korean"Now we create the dataset using the class we defined above, selecting a subsample of 10 audio files to make the processing quicker.
# Create dataset object, selecting only 10 examples for brevity
dataset = Fleurs(language_google, subsample_rate=1, device=device)
dataset = torch.utils.data.random_split(dataset, [10, len(dataset)-10])[0]Next, we load the Whisper model that we will be using, opting for the "tiny" model version to make inference quicker. We then set transcription and translation options.
# Load tiny Whisper model
model = whisper.load_model("tiny")
# Set options
options = dict(language=language_whisper, beam_size=5, best_of=5)
transcribe_options = dict(task="transcribe", **options)
translate_options = dict(task="translate", **options)Finally, we iterate through the dataset, transcribing each audio file to Korean, and translating each audio file to English. Note that the translation happens directly on the audio data and does not translate the generated transcription to English. We save the transcriptions and translations to lists, in addition to the ground truth reference for comparison.
# Run inference
references = []
transcriptions = []
translations = []
for audio, text in tqdm(dataset):
transcription = model.transcribe(audio, **transcribe_options)["text"]
translation = model.transcribe(audio, **translate_options)["text"]
transcriptions.append(transcription)
translations.append(translation)
references.append(text)Finally, we create the pandas DataFrame which stores the results, and then print the results and save them to CSV.
# Create dataframe from results and save the data
data = pd.DataFrame(dict(reference=references, transcription=transcriptions, translation=translations))
print(data)
data.to_csv("results.csv")The results can be seen below




