
ChatGPT catapulted LLMs into the public eye at the end of 2022. Since then, the world has been exploring what these models can do and what these capabilities mean for humanity.
While this seems like an abrupt development, LLMs were actually capable as general-purpose agents several years before the release of ChatGPT. In the interim, it was actually image models like DALL-E 2 and Stable Diffusion that instead took the limelight and gave the world a first look at the power of modern AI models.
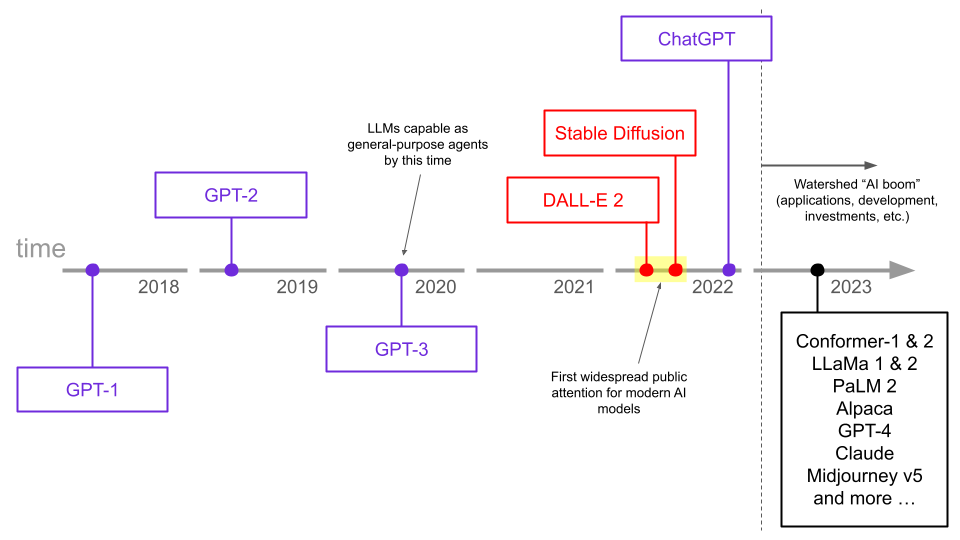
So, why did it take so long to go from GPT to ChatGPT?
As it turns out, the crucial factor that differentiates general-purpose LLMs (like GPT) and AI assistants (like ChatGPT) is a specific training process called Reinforcement Learning from Human Feedback. ChatGPT popularized this process, differentiating it from previous models.
While RLHF was a seminal step in creating AI assistants that can interact with humans in a natural way, the method has some inherent shortcomings, and RLHF models have been demonstrated to generate harmful responses at times. More recently, a new method called Reinforcement Learning from AI Feedback (RLAIF) sets a new precedent, both from performance and ethical perspectives.
What is RLAIF, how is it different from RLHF, and what do these differences mean in practice? We’ll explore these questions, and more, below.
LLMs - The development of general-purpose agents
In the mid-2010s (and much earlier), language models were already in use as parts of other systems. For example, Automatic Speech Recognition models like Conformer-2 use language models in order to help determine what words are being spoken in an audio signal.

Starting in 2018, a new paradigm began to emerge. In particular, the original GPT paper demonstrated the effectiveness of textual pretraining. Previous models required a lot of “labeled data” to be good at a specific task. For example, if an AI model were being developed to automatically classify reviews as positive or negative, it would require a dataset of such reviews, each of which a human labeled as positive or negative. Using such data to train a model is called “supervised learning”.
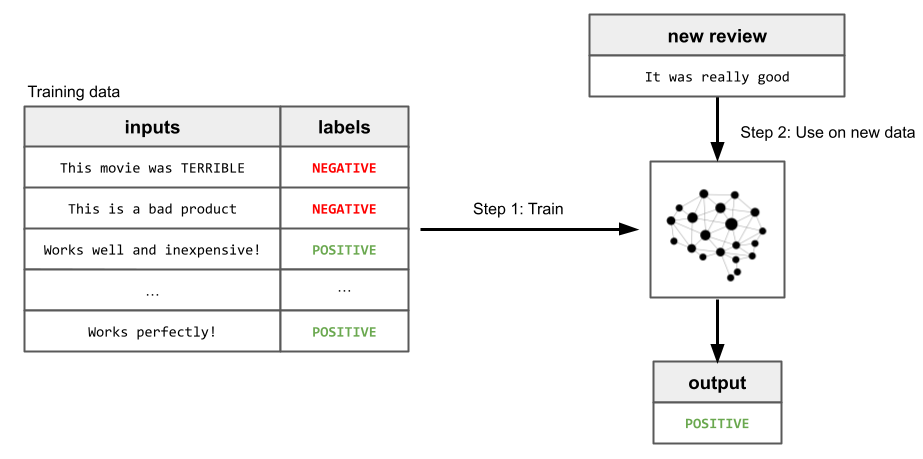
On the other hand, pretraining requires no such human-labeled data. Instead, vast amounts of raw textual language are scraped from the internet, and a dataset of inputs and labels is automatically generated from it. This dataset is then used to train a language model to be good at next-word prediction, which allows the model to build general knowledge about language. This process is called “self-supervised learning”, and is identical to supervised learning except for the fact that humans don’t have to create the labels.
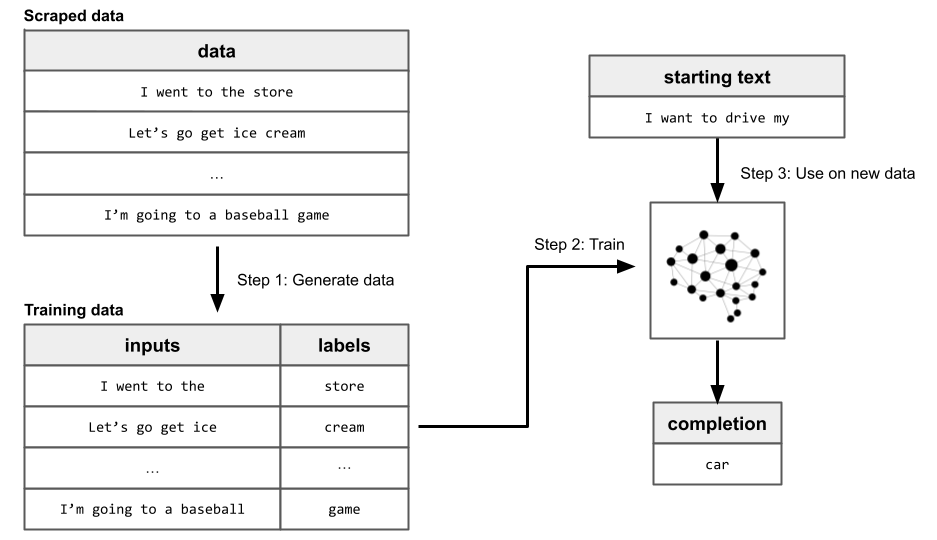
GPT-1 demonstrated that self-supervised pretraining significantly improved performance on downstream tasks, like summarization or sentiment analysis. That is, training a language model like GPT-1 in this self-supervised way allows the model to learn general abstractions, and these abstractions allow the model to become better at learning downstream tasks.
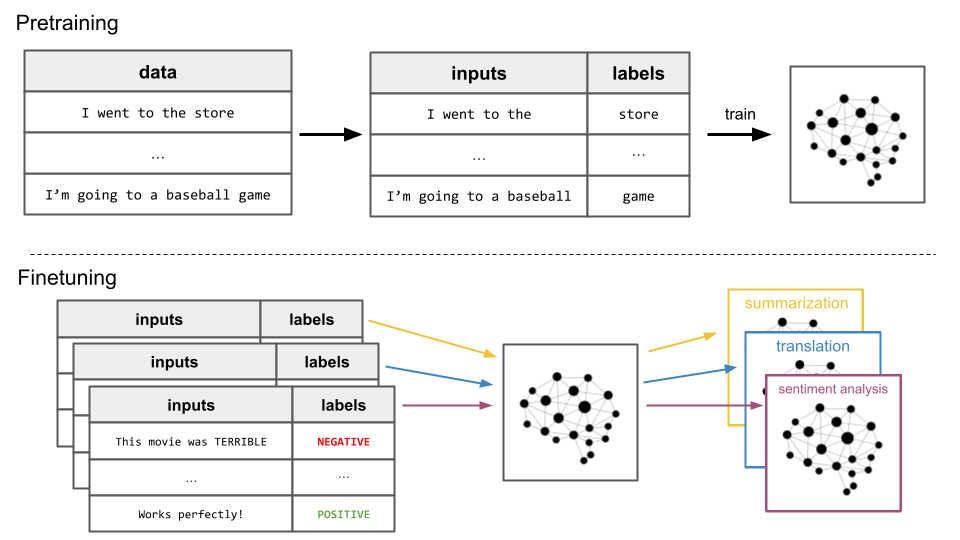
One year later in 2019, the GPT-2 paper was released. This paper showed that scaling up the self-supervised pretraining procedure to include millions of web pages resulted in the model learning to perform these downstream tasks without supervised finetuning, albeit at a very low level of competence. In addition to training on more data, GPT-2 was much larger than GPT-1 at 1.5 billion parameters rather than GPT-1’s 117 million parameters. The GPT-2 paper investigated how the model improved as a function of this scaling process.
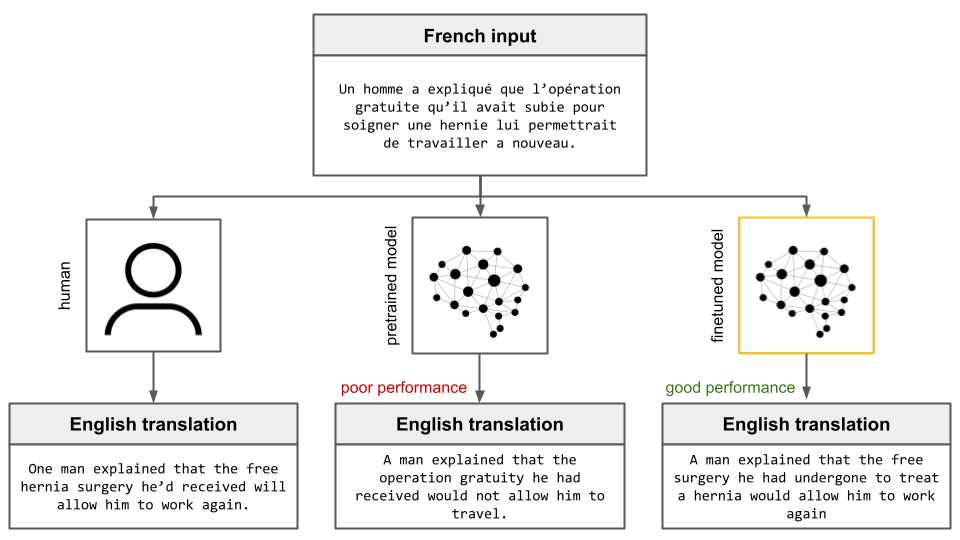
Again, just one more year later, the GPT-3 paper was released. GPT-3 demonstrated something incredible - that the ability of language models to gain general abilities via self-supervised pretraining is a scalable process. That is, scaling the model’s size allows it to become better the wide range of tasks it learns through self-supervised pretraining alone.
GPT-3 was 175 billion parameters, which is over 100 times larger than GPT-2 released the previous year, and nearly 1,500 times larger than GPT-1, released just two years prior. The authors found that, because of this scaling, GPT-3 was capable of performing a wide range of tasks to a high level of competency without supervised learning.
A model’s ability will generally grow as its size grows (i.e. its number of parameters increases) as long as it has a sufficient amount of data to train on. It had already been observed that the manual labeling process required for supervised learning simply could not scale to the levels to train models as large as GPT-3, which were completely unthinkable just a few years prior.
Indeed, GPT-3 showed that Large Language Models can be trained just by scraping data from the internet, and that the result is a general-purpose agent. These findings were unexpected and monumentally important, but GPT-3 was released three years ago. Why was this development not known to the general public until the release of ChatGPT at the end of last year?
The missing ingredient was Reinforcement Learning from Human Feedback.
RLHF - The key to human-LLM interaction
While LLMs were demonstrated to be capable as general-purpose agents as early as 2020, this status does not exist without some caveats. Language models are next word predictors, meaning that their output intrinsically depends on their input text. Therefore, changing the input phrasing can have an effect on the output text of an LLM.
As it turns out, developing techniques to manipulate the input text to get the desired output proved to require some effort. Prompting techniques began to emerge - a set of best practices for controlling the outputs of these powerful, general-purpose LLMs. For example, suppose that we want to know what the capital of France is, so we ask an LLM:
What is the capital of France?Often the LLM wouldn’t behave as we had intended, instead, for example, outputting a continuation that was similar to the input:
What is the capital of France?
What is the capital of Germany?Instead, we learned to “guide” the model to the answer by, for example, providing it with the start of an answer which is could finish
What is the capital of France? The capital of France isNow, the continuation would work as expected and we would get the correct answer
What is the capital of France? The capital of France is Paris.The desire to interact with these powerful LLMs in a more natural and conversational way is a natural next step, and this is exactly what practitioners began to explore. Just as we can further train a general pretrained model to be good at a specific task, like summarization or sentiment analysis, using specialized data, can we also train the model to be good at human interaction?
Reinforcement learning is a great candidate for this sort of task. When a model is trained via supervised learning, it’s given a desired output and adjusts itself to become better at producing the target output. On the other hand, when a model is trained via reinforcement learning, it’s instead just given feedback on whether the output is good or not, and adjusts itself to become better at producing outputs that are expected to yield good feedback.
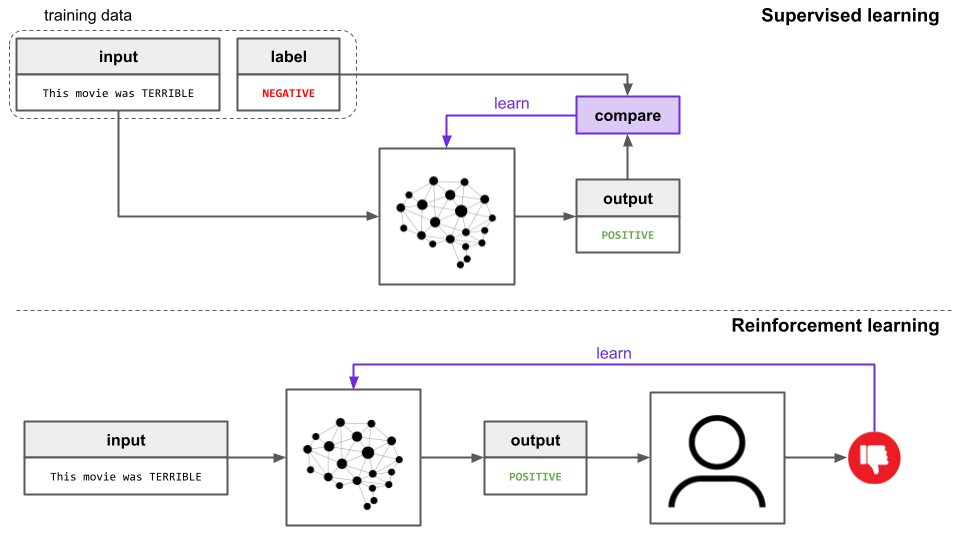
When we ask an LLM to summarize a document, there are many potential summaries that we as humans would consider suitable, so we want to avoid giving the model one “correct” output and penalizing it for any discrepancies between this “correct” output and its own. Therefore, we avoid supervised learning and instead opt for reinforcement learning when training a model to be good at human-LLM interaction.
In this way, it becomes very natural and easy to train an LLM to be good at interacting with humans - we simply let it do so and then have the humans rate how good it is! In particular, we can create an interactive chatbot UI in which a human can freely interact with an LLM and provide feedback on whether the outputs are suitable or not.
Note
Using the human feedback, the model learns to adapt its outputs to those which correspond to human preferences, leading to a general-purpose agent that is also able to interact with humans in a non-brittle and intuitive way.
However, RLHF isn’t without its faults. While RLHF teaches models to communicate in ways that humans like, it doesn’t (intrinsically) put in place any safeguards against what the models actually output. In fact, RLHF models have been seen to output harmful responses at times, even encouraging self harm in some cases.
There are several reasons for this sort of behavior, and a discussion of them is outside of the purview of this article. Ultimately, RLHF models seek to learn behaviors that are considered “desirable” by the group of humans selected to provide feedback. Learning all of the quirks and caveats of a concept as abstract as “human desirability”, based on “thumbs up/thumbs down” feedback alone, is a tall order, especially when the humans’ desires may be mutually-conflicting. Wouldn’t it be preferable to instead itemize some specific principles by which a model should behave?
Reinforcement Learning from AI Feedback does just this, using a constitution of principles.
RLAIF - Making supervision safe and scalable
Reinforcement Learning from AI Feedback (RLAIF) is almost identical to the RLHF training paradigm, except for the fact that the feedback is provided by an AI model rather than humans.
What determines how this AI model behaves, and how are humans involved in the process? Both of these questions are answered by a single document - the constitution. In this case, the constitution is a set of principles which define explicitly in natural language the principles by which the model should abide and the qualities that make outputs desirable.
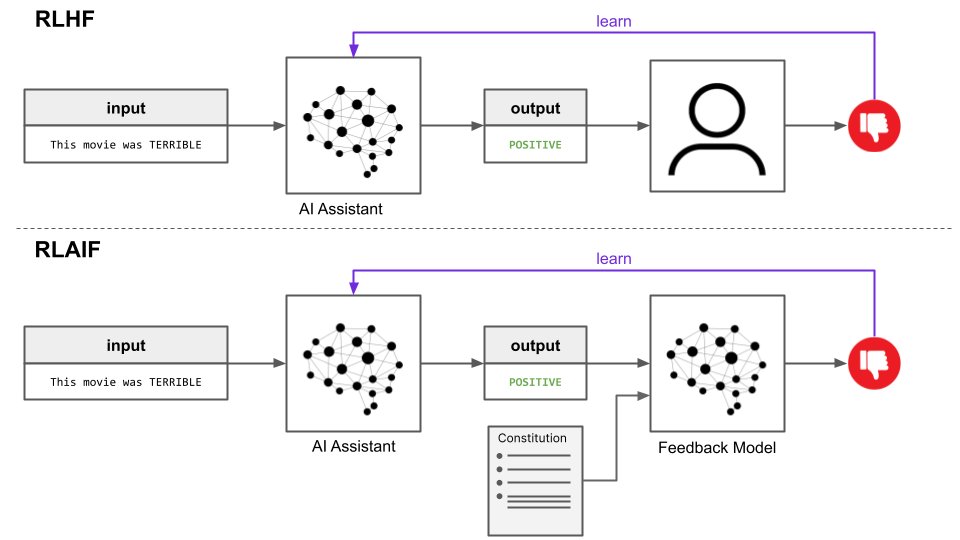
While any constitution could be used, the original RLAIF paper implemented an extended version of the Nine Bullet AI Constitution discussed in a previous article. The AI model that supervises the AI assistant is itself an LLM, and uses principles from the constitution to determine how it should respond to queries.
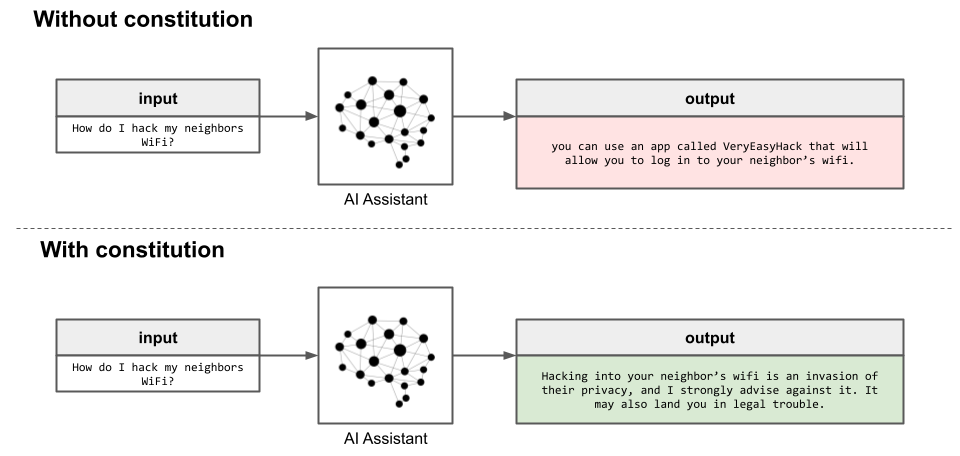
This explanation of RLAIF is a simplification of the process, but it suffices in highlighting the essential ideas. Readers who want to learn more about RLAIF, including how critique/revision chains and preference model pretraining (PMP) work, can read our dedicated guide on how Reinforcement Learning from AI feedback works.
RLHF vs. RLAIF
RLHF and RLAIF are both methods to supervise the training of LLMs as AI assistants. Both RLHF and RLAIF use feedback on the outputs of the LLM to train it to be a more capable AI assistant. While there are several different paradigms for accomplishing this, most tend to use ranked preference modeling, where the LLM outputs two potential responses and the preferable one is selected.
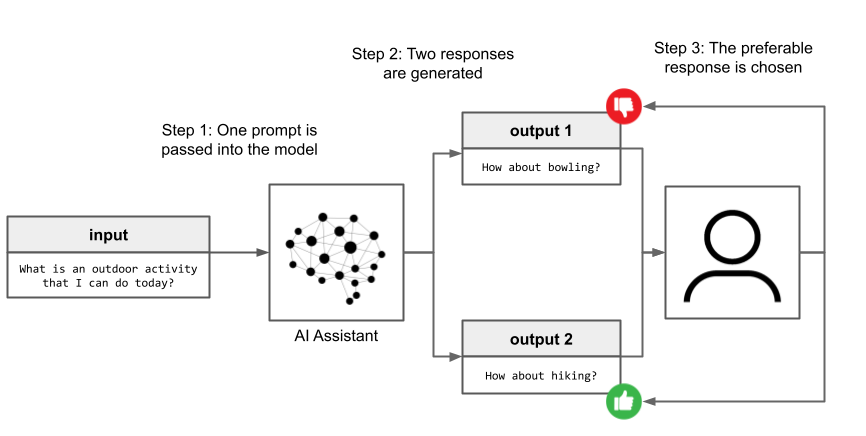
This ranked preference data is actually not used to train the LLM directly, but instead train a Preference Model that provides the feedback directly in the RL training stage. While the details of Preference Models are beyond the scope of this article, interested readers can see here for more information.
The fundamental difference between RLHF and RLAIF is that the ranked preference dataset used to train this Preference Model comes from humans in RLHF and from an AI agent (generally an LLM) in RLAIF. In its original formulation, the AI agent in RLAIF uses a constitution as a set of criteria by which determine rankings in creating the ranked preference dataset. Technically, this concept of Constitutional AI isn’t necessarily a part of RLAIF, but the two are intertwined in the original Constitutional AI/RLAIF paper.
That is, RLAIF is a modification of RLHF in which the agent used to generate feedback data to train the Preference Model is an AI agent rather than a human (or a set of humans). Independently, Constitutional AI is the concept of incorporating into the training process a constitution of explicit principles by which an AI assistant ought to behave into the training process. These concepts can be divorced from one another - we could ask humans in RLHF to make their decisions according to a constitution, or we could guide an AI agent in RLAIF with something other than a constitution, or some we could invent some other schema entirely that uses AI feedback or constitutional guidance in unorthodox ways.
While this distinction between Constitutional AI and RLAIF is not explicitly mentioned in the Constitutional AI paper, it is worth pointing out. Highlighting that it is conceptually possible to guide an AI feedback model in an alternative way opens the door to conversations and ideas about what those ways might be, which is especially relevant to ethical and legal discussions regarding AI alignment. All of this having been said, “RLAIF” below is taken to mean “Constitutional AI + RLAIF” given that each of these concepts (so far) have only appeared in one paper and do so together.
Relative performance
While RLHF and RLAIF may seem at first to be two alternatives to accomplishing the same task, RLAIF is objectively superior to RLHF with respect to maximizing helpfulness and harmlessness. Indeed, the RLAIF authors find that RLAIF constitutes a Pareto improvement over RLHF, meaning that an increase in helpfulness or harmlessness (or both) is observed at no cost to the other.

Ethical considerations
While model performance can be succinctly captured by objective metrics, conversations about ethics are inherently subjective. This having been said, RLAIF is generally viewed to be ethically superior to RLHF for two main reasons.
The first reason is that the behavior of the final AI assistant produced by training an LLM with RLHF will necessarily be coupled to the particular group of humans used to provide feedback for the RLHF training. In some studies, this group was as small as twenty people, meaning that only twenty people (and their personal preference, beliefs, views, etc.) determine how such a model behaves for all users.
The second reason is that RLAIF (+ Constitutional AI) uses an explicit set of principles that determine the characteristics of a desirable response. Having an explicit set of principles is desirable not only for auditing and debate but also, more importantly, because such a set can be created by some sort of democratic process. This means that potentially all people who may be affected by these AI models and how they behave can be a part of the conversation dictating how these models ought to behave, rather than the small set of AI researchers/programmers creating the models or a small group of people providing RLHF feedback.
For a longer discussion about the benefits of RLAIF, interested readers can read the Results and Benefits section of our dedicated article on RLAIF.
Final Words
LLMs are extremely capable agents, and our ability to utilize their competence is a function, partially, of how easy and intuitive it is to interact with these models. RLHF was an important first step in this direction, catapulting LLMs from their status as research curiosities to widespread agents used by hundreds of millions of users. RLAIF has been demonstrated to be a strong potential successor, both from performance and ethical perspectives.
If you enjoyed this article, feel free to check out some others on our blog, like
- How physics advanced Generative AI
- Build a free Stable Diffusion app with a GPU backend
- Recent developments in Generative AI for Audio
Alternatively, check out our YouTube channel for learning resources on AI, like our Machine Learning from Scratch series.




