Automatic summarization with LLMs in Python
Learn how to perform automatic summarization with Python using LLMs in this easy-to-follow tutorial.



Large Language Models (LLMs) are capable of performing a wide range of tasks involving text. In this tutorial, we will learn how to use LLMs to automatically summarize audio and video files with Python.
Getting started
Automatically summarizing an audio or video file is a two step process. First, we need to transcribe the file into text. Then, once we have the transcript, we need to process the transcript with an LLM. We’ll use AssemblyAI for both of these steps, using the Conformer-2 model to transcribe the files and LeMUR to summarize them.
We’ll use the AssemblyAI Python SDK in this tutorial. To get started, create a virtual environment.
python -m venv transcriber # you may have to use `python3`
Activate the virtual environment with the activation script on macOS or Linux:
source ./transcriber/bin/activate
On Windows, the virtual environment can be activated with the activate.bat script:
.\transcriber\Scripts\activate.bat
Now, install the AssemblyAI Python SDK.
pip install "assemblyai>=0.15"
To use the AssemblyAI API you will need an API key - you can get one for free here. You will need to upgrade your account in order to use LeMUR.
Add this API key as an environment variable as follows on Linux and macOS:
export ASSEMBLYAI_API_KEY=your-key-here # paste this value from assemblyai.com/dashboard
If you’re on Windows, you can set this environment variable as below:
set ASSEMBLYAI_API_KEY=your-key-here # paste this value from assemblyai.com/dashboard
Tip
Alternatively, you can set your API key in the Python script itself using aai.settings.api_key = "YOUR_API_KEY". Note that you should not hard code this value if you use this method. Instead, store your API key in a .env file and use a package like python-dotenv to import it into the script. Do not check the .env file into source control.
Automatic summarization of a video with Python
We’ll summarize this episode of the Lex Fridman podcast in which Lex speaks with Guido Van Rossum, the creator of Python. All of the below code can be found in this repository on GitHub.
Transcription
First, we’ll transcribe the podcast episode, which only takes three lines of code. Create a file called autosummarize.py and paste the below code into it:
import assemblyai as aai transcriber = aai.Transcriber() transcript = transcriber.transcribe("https://storage.googleapis.com/aai-web-samples/lex_guido.webm")
We import the assemblyai package, and then instantiate a Transcriber object, using its transcribe method to generate a Transcript object for the video.
Tip
Each transcript you create with AssemblyAI is assigned a unique ID, which you can access via the id attribute of a Transcript object - transcript.id in our case. You can fetch a transcript by its ID in order to avoid having to transcribe the same file again if you would like to further analyze it with LeMUR in the future.
Next, we’ll add error-catching code in case there is an issue with the transcription. Add the following lines to the bottom of autosummarize.py:
if transcript.error: raise Exception(f'Transcription error: {transcript.error}')
Automatic summarization
Now that we have our transcript, we can automatically summarize it using LeMUR’s Custom Summary endpoint. There are a few potential parameters you can include when using LeMUR - we’ll use context and answer_format.
context provides wider context to LeMUR to contextualize the contents of the transcript, while answer_format allows us to specify a particular format we would like the response to take. This format could be a natural language descriptor like "A short list of bullet points", or it could be markdown formatted. We will use the latter. Add the following lines of code to autosummarize.py:
context = "An episode of the Lex Fridman podcast, in which he speaks with Guido van Rossum, the creator of the Python programming language" answer_format = '''**<topic header>** <topic summary> '''
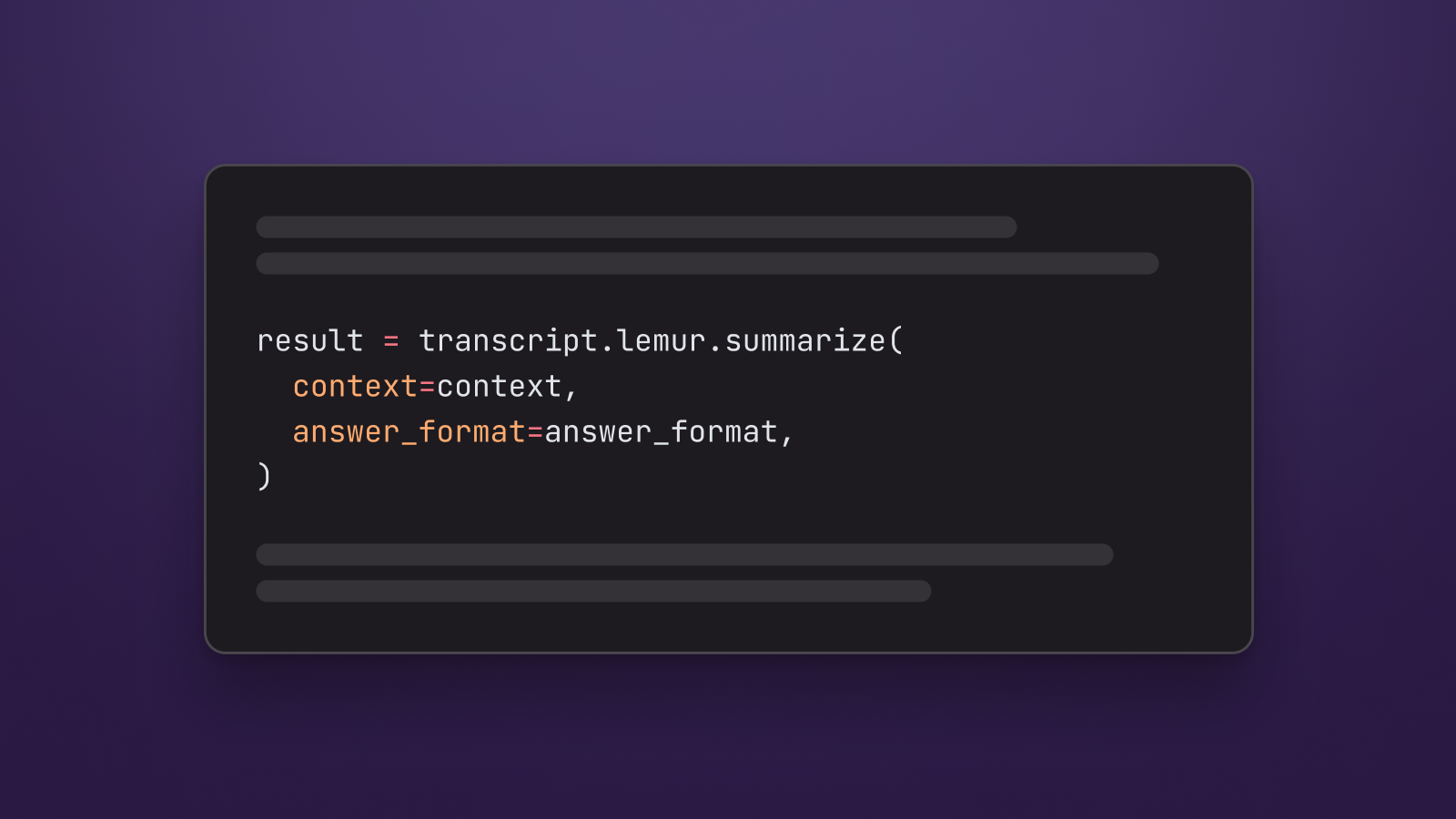
We are now ready to perform automatic summarization using LeMUR. All LeMUR endpoints can be accessed through the lemur attribute of a Transcript object. In our case, we’ll use the lemur.summarize method, passing in our context and answer format from above. Add the following lines to autosummarize.py:
result = transcript.lemur.summarize( context=context, answer_format=answer_format, ) print(result.response)Read LeMUR API Documentation
Running the script
To run the script, go to the terminal where you set the ASSEMBLYAI_API_KEY environment variable and activated the virtual environment, and enter the following command:
python autosummarize.py # you may have to use `python3`
After a minute or two, you will see the summary printed to the terminal:
**Python's design choices** Guido discusses the rationale behind Python's indentation style over curly braces, which reduces clutter and is simpler for beginners. However, most programmers are familiar with curly braces from other languages. The dollar sign used before variables in PHP originated in early Unix shells to distinguish variables from program names and file names. Choosing different programming languages involves difficult trade-offs. **Improving CPython's performance** Guido initially coded CPython simply and efficiently, but over time more optimized algorithms were developed to improve performance. The example of prime number checking illustrates the time-space tradeoff in algorithms. **The history of asynchronous I/O in Python** In the late 1990s and early 2000s, the Python standard library included modules for asynchronous I/O and networking. However, over time these modules became outdated. Around 2012 to 2014, developers proposed updating these modules, but were told to use third party libraries instead. Guido proposed updating asynchronous I/O in the standard library. He worked with developers of third party libraries on the design. The new asynchronous I/O module was added to the standard library and has been successful, particularly for Python web clients. **Python for machine learning and data science** In the early 1990s, scientists used Fortran and C++ libraries to solve mathematical problems. Paul Dubois saw that a higher level language was needed to tie algorithms together. In the mid 1990s, Python libraries emerged to support large arrays efficiently. Scientists at different institutions discovered Python had the infrastructure they needed. Exchanging code in the same language is preferable to starting from scratch in another language. This is how Python became dominant for machine learning and data science. **The global interpreter lock (GIL)** The GIL allowed for multi-threading even on single core CPUs. As multi-core CPUs became common, the GIL became an issue. Removing the GIL could be an option for Python 4.0, though it would require recompiling extension modules and supporting third party packages. **Guido's experience as BDFL** While providing clarity and direction for the community, the BDFL role also caused Guido personal stress. He feels he relinquished the role too late, but the new steering council structure has led the community steadily. **The future of Python and programming** Python will become a legacy language built upon without needing details. Abstractions are built upon each other at different levels.
Automatic summarization of audio files with Python
The AssemblyAI Python SDK can also take in audio files - find a list of all supported formats here. So, to automatically summarize an audio file, we can use the same code as above but simply pass in an audio file:
import assemblyai as aai transcriber = aai.Transcriber() transcript = transcriber.transcribe("https://storage.googleapis.com/aai-web-samples/meeting.mp3") if transcript.error: raise Exception(f'Transcription error: {transcript.error}') context = "A GitLab meeting to discuss logistics" answer_format = '''**<topic header>** <topic summary> ''' result = transcript.lemur.summarize( context=context, answer_format=answer_format, ) print(result.response)
Output
Engineering Key Review
The meeting begins with a proposal to break up the engineering key review meeting into four departmental key reviews to allow for more in-depth discussion. A two-month rotation is suggested so as not to add too many new meetings. The proposal is supported.
R&D Merge Request Rates
There is discussion around the R&D overall and wider merge request rates. It is clarified that the wider rate includes community contributions while the overall rate includes internal and external requests. There is agreement to track the percentage of total requests from the community over time instead.
Postgres Replication Issue
There is an update on work to address lag in Postgres replication for the data engineering team. Actions include dedicating a host for the data team, database tuning, and improving demand on the database. More work is needed to determine the best solutions. An update will be provided at the next infrastructure key review.
Defect Tracking and SLOs
There is an update on work to track defects against service level objectives (SLOs). Iterations are being made to measure the average age of open bugs and the percentage of open bugs within SLO. More discussion is needed on the best approach.
Key Metrics
The team discusses key metrics. The decline in NPS has slowed, though more data is needed to determine if it is an actual trend. The narrow merge request rate is below target, though it is higher than the same time last year. The rate is expected to rebound in March. The target rate has been adjusted to 10 going forward to focus on other metrics like quality and security.
Closing
The meeting ends with a request for any other discussion. Hearing none, the meeting adjourns.
Final Words
In this tutorial, we learned how to perform automatic summarization using Python and LeMUR. LeMUR is capable of much more than just automatic summarization - feel free to check out our quickstart Colab to see more of what LeMUR can do.
If you found this tutorial helpful, feel free to check out some of the other tutorials on our blog, where you’ll also find other learning resources for AI including
- Introduction to Generative AI
- Emergent Abilities of Large Language Models
- AI Trends in 2023: Graph Neural Networks
Also feel free to check out our YouTube channel for more learning resources, or follow us on Twitter to stay in the loop when we drop new content.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.