

PyTorch and TensorFlow are far and away the two most popular Deep Learning frameworks today. The debate over which framework is superior is a longstanding point of contentious debate, with each camp having its share of fervent supporters.
Both PyTorch and TensorFlow have developed so quickly over their relatively short lifetimes that the debate landscape is ever-evolving. Outdated or incomplete information is abundant, and further obfuscates the complex discussion of which framework has the upper hand in a given domain.
While TensorFlow has a reputation for being an industry-focused framework and PyTorch has a reputation for being a research-focused framework, we’ll see that these notions stem partially from outdated information. The conversation about which framework reigns supreme is much more nuanced going into 2023 - let’s explore these differences now.
Practical Considerations
PyTorch and TensorFlow alike have unique development stories and complicated design-decision histories. Previously, this has made comparing the two a complicated technical discussion about their current features and speculated future features. Given that both frameworks have matured exponentially since their inceptions, many of these technical differences are vestigial at this point.
Luckily for those of us who don’t want their eyes glazing over, the PyTorch vs TensorFlow debate currently comes down to three practical considerations:
- Model Availability: With the domain of Deep Learning expanding every year and models becoming bigger in turn, training State-of-the-Art (SOTA) models from scratch is simply not feasible anymore. There are fortunately many SOTA models publicly available, and it is important to utilize them where possible.
- Deployment Infrastructure: Training well-performing models is pointless if they can’t be put to use. Lowering time-to-deploy is paramount, especially with the growing popularity of microservice business models; and efficient deployment has the potential to make-or-break many businesses that center on Machine Learning.
- Ecosystems: No longer is Deep Learning relegated to specific use cases in highly controlled environments. AI is injecting new power into a litany of industries, so a framework that sits within a larger ecosystem which facilitates development for mobile, local, and server applications is important. Also, the advent of specialized Machine Learning hardware, such as Google’s Edge TPU, means that successful practitioners need to work with a framework that can integrate well with this hardware.
We’ll explore each of these three practical considerations in turn, and then provide our recommendations for which framework to use in different areas.
PyTorch vs TensorFlow - Model Availability
Implementing a successful Deep Learning model from scratch can be a very tricky task, especially for applications such as NLP where engineering and optimization are difficult. The growing complexity of SOTA models makes training and tuning simply impractical, approaching impossible, tasks for small-scale enterprises. Startups and researchers alike simply do not have the computational resources to utilize and explore such models on their own, so access to pre-trained models for transfer learning, fine-tuning, or out-of-the-box inference is invaluable.
In the arena of model availability, PyTorch and TensorFlow diverge sharply. Both PyTorch and TensorFlow have their own official model repositories, as we’ll explore below in the Ecosystems section, but practitioners may want to utilize models from other sources. Let’s take a quantitative look at model availability for each framework.
HuggingFace
HuggingFace makes it possible to incorporate trained and tuned SOTA models into your pipelines in just a few lines of code.
When we compare HuggingFace model availability for PyTorch vs TensorFlow, the results are staggering. Below we see a chart of the total number of models available on HuggingFace that are either PyTorch or TensorFlow exclusive, or available for both frameworks. As we can see, the number of models available for use exclusively in PyTorch absolutely blows the competition out of the water. Almost 92% of models are PyTorch exclusive, up from 85% last year. In contrast, only about 8% being TensorFlow exclusive, with only about 14% of all models available for TensorFlow (down from 16% last year). Further, over 45 thousand PyTorch exclusive models were added in 2022, whereas only about 4 thousand TensorFlow exclusive models were added.
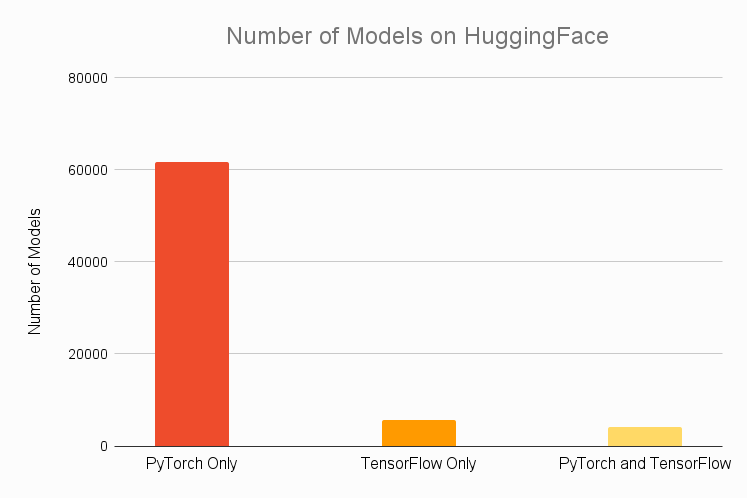
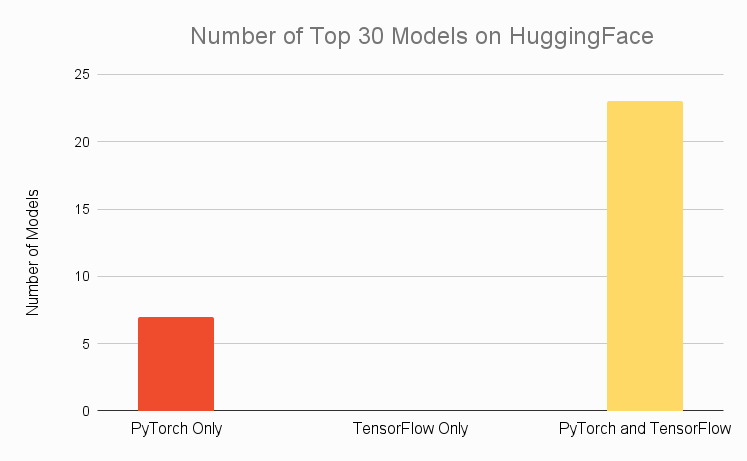
We see interesting results if we relegate our purview to only the 30 most popular models on HuggingFace. While all models are available in PyTorch and none are TensorFlow exclusive, like last year, the number of models available for both has increased from 19 to 23, indicating that there may be an effort for TensorFlow coverage on the most popular models.
Research Papers
For research practitioners especially, having access to models from recently-published papers is critical. Attempting to recreate new models that you want to explore in a different framework wastes valuable time, so being able to clone a repository and immediately start experimenting means that you can focus on the important work.
Given that PyTorch is the de facto research framework, we would expect the trend we observed on HuggingFace to continue into the research community as a whole; and our intuition is correct.
We’ve aggregated data from eight top research journals over the past several years into the below graph, which shows the relative proportion of publications that use PyTorch or TensorFlow. As you can see, the adoption of PyTorch was extremely rapid and, in just a few years, grew from use in just about 7% to use in almost 80% of papers that use either PyTorch or TensorFlow.
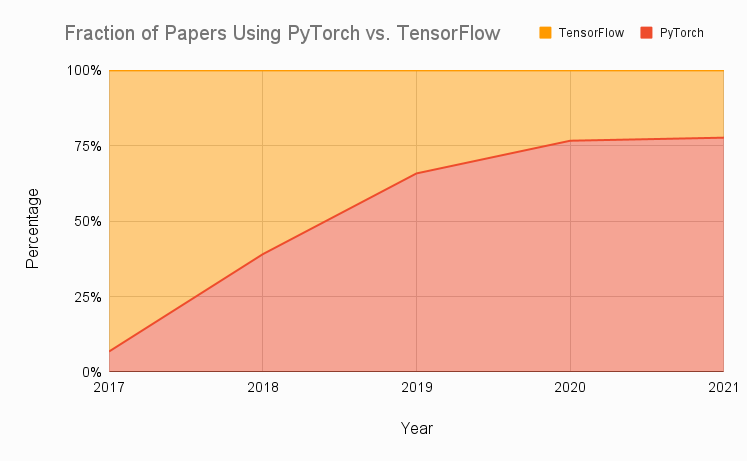
Much of the reason for this rapid adoption was due to difficulties with TensorFlow 1 that were exacerbated in the context of research, leading researchers to look to the newer alternative PyTorch. While many of TensorFlow’s issues were addressed with the release of TensorFlow 2 in 2019, PyTorch’s momentum has been great enough for it to maintain itself as the established research-centric framework, at least from a community perspective.
We can see the same pattern if we look at the fraction of researchers who migrated frameworks. When we look at publications by authors that were using either PyTorch or TensorFlow in 2018 and 2019, we find that the majority of authors who used TensorFlow in 2018 migrated to PyTorch in 2019 (55%), while the vast majority of authors who used PyTorch in 2018 stayed with PyTorch 2019 (85%). This data is visualized in the Sankey diagram below, where the left side corresponds to 2018 and the right side to 2019. Note that the data represent proportions of users of each framework in 2018, not total numbers.
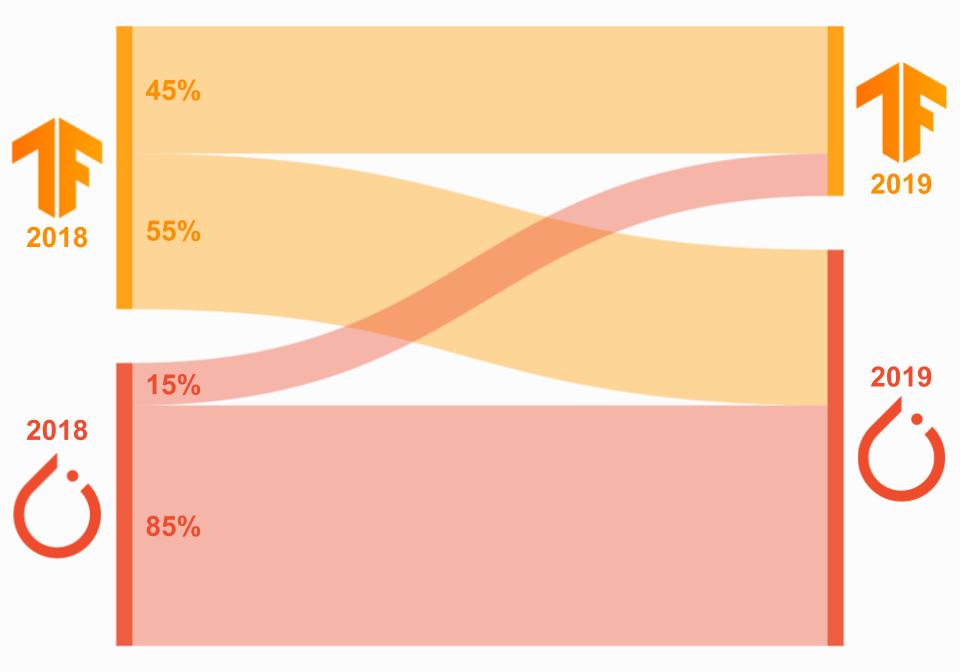
Careful readers will notice that this data is from before the release of TensorFlow 2, but as we will see in the next section, this fact is irrelevant in the research community.
Papers with Code
Lastly, we look at data from Papers with Code - a website whose mission it is to create a free and open resource with Machine Learning papers, code, datasets, etc. We’ve plotted the percentage of papers which utilize PyTorch, TensorFlow, or another framework over time, with data aggregated quarterly, from late 2017 to the current quarter. We see the steady growth of papers utilizing PyTorch - out of the 3,319 repositories created this quarter, nearly 70% of them are implemented in PyTorch, with just 4% implemented in TensorFlow (down from 11% last year).
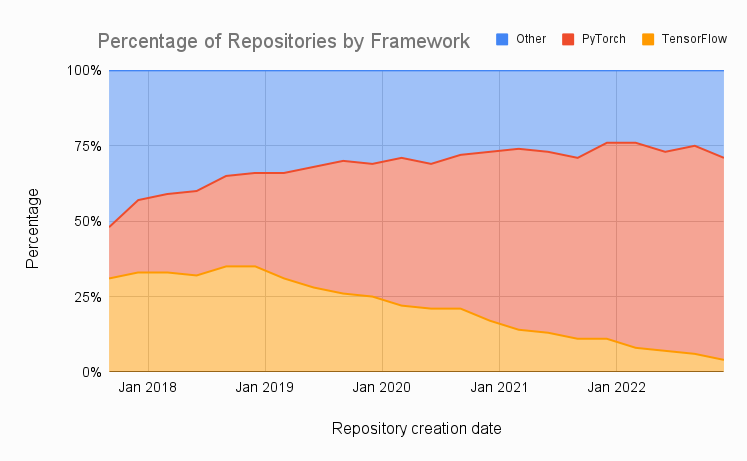
Conversely, we see the steady decline in use of TensorFlow. Even the release of TensorFlow 2 in 2019, which addressed many of the issues that made using TensorFlow 1 painful for research, was not enough to reverse this trend. We see a near-monotonic decline in the popularity of TensorFlow, even after the release of TensorFlow 2.
Model Availability - Final Words
It is obvious from the above data that PyTorch currently dominates the research landscape. While TensorFlow 2 made utilizing TensorFlow for research a lot easier, PyTorch has given researchers no reason to go back and give TensorFlow another try. Furthermore, backward compatibility issues between old research in TensorFlow 1 and new research in TensorFlow 2 only exacerbate this issue.
For now, PyTorch is the clear winner in the area of research simply for the reason that it has been widely adopted by the community, and most publications/available models use PyTorch.
There are a couple of notable exceptions / notes:
- Google Brain: Google Brain makes heavy use of JAX and makes use of Flax - Google's neural network library for JAX.
- DeepMind: DeepMind standardized the use of TensorFlow in 2016, although they announced in 2020 that they were using JAX to accelerate their research. In this announcement they also give an overview of their JAX ecosystem, most notably Haiku, their JAX-based neural network library.
DeepMind created Sonnet, which is a high-level API for TensorFlow that is tailored towards research and sometimes called “the research version of Keras”, that may be useful to those considering using TensorFlow for research. Note that its development has slowed down. Further, DeepMind’s Acme framework may be essential to Reinforcement Learning practitioners. - OpenAI: On the other hand, OpenAI standardized the usage of PyTorch internally in 2020; but, once again for those in Reinforcement Learning, their older baselines repository is implemented in TensorFlow. Baselines provides high-quality implementation of Reinforcement Learning algorithms, so TensorFlow may be the best choice for Reinforcement Learning practitioners.
- JAX: Google has another project called JAX that is growing in popularity in the research community. There is, in some sense, a lot less overhead in JAX compared to PyTorch or TensorFlow; but it’s underlying philosophy is different than both PyTorch and TensorFlow, and for this reason migrating to JAX may not be a good option for most. There are a growing number of models/papers that utilize JAX, and it is being developed at a very rapid pace. While last year the future of JAX was less clear, it is now apparent that JAX is here to stay.
TensorFlow has a long and arduous, if not impossible, journey ahead if it wants to reestablish itself as the dominant research framework.
Round 1 in the PyTorch vs TensorFlow debate goes to PyTorch.
PyTorch vs TensorFlow - Deployment
While employing state-of-the-art (SOTA) models for cutting-edge results is the holy grail of Deep Learning applications from an inference perspective, this ideal is not always practical or even possible to achieve in an industry setting. Access to SOTA models is pointless if there is a laborious, error-prone process of making their intelligence actionable. Therefore, beyond considering which framework affords you access to the shiniest models, it is important to consider the end-to-end Deep Learning process in each framework.
TensorFlow has been the go-to framework for deployment-oriented applications since its inception, and for good reason. TensorFlow has a litany of associated tools that make the end-to-end Deep Learning process easy and efficient. For deployment specifically, TensorFlow Serving and TensorFlow Lite allow you to painlessly deploy on clouds, servers, mobile, and IoT devices.
PyTorch used to be extremely lackluster from a deployment perspective, but it has worked on closing this gap in recent years. The introduction of TorchServe last year and PyTorch Live just a couple of weeks ago has afforded much-needed native deployment tools, but has PyTorch closed the deployment gap enough to make its use worthwhile in an industry setting? Let’s take a look.
TensorFlow
TensorFlow offers scalable production with static graphs which are optimized for inference performance. When deploying a model with TensorFlow, you use either TensorFlow Serving or TensorFlow Lite depending on the application.
TensorFlow Serving
TensorFlow Serving is for use when deploying TensorFlow models on servers, be them in-house or on the cloud, and is used within the TensorFlow Extended (TFX) end-to-end Machine Learning platform. Serving makes it easy to serialize models into well-defined directories with model tags, and select which model is used to make inference requests while keeping server architecture and APIs static.
Serving allows you to easily deploy models on specialized gRPC servers, which run Google’s open-source framework for high-performance RPC. gRPC was designed with the intent on connecting a diverse ecosystem of microservices, so these servers are well suited for model deployment. Serving as a whole is tightly integrated with Google Cloud via Vertex AI and integrates with Kubernetes and Docker.
TensorFlow Lite
TensorFlow Lite (TFLite) is for use when deploying TensorFlow models on mobile or IoT/embedded devices. TFLite compresses and optimizes models for these devices, and more widely addresses 5 constraints for on-device Artificial Intelligence - latency, connectivity, privacy, size, and power consumption. The same pipeline is used to simultaneously export both standard Keras-based SavedModels (used with Serving) and TFLite models, so model quality can be compared.
TFLite can be used for both Android and iOS, as well as microcontrollers (ARM with Bazel or CMake) and embedded Linux (e.g. a Coral device). TensorFlow's APIs for Python, Java, C++, JavaScript, and Swift (archived as of this year), give developers a wide array of language options.
PyTorch
PyTorch has invested in making deployment easier, previously being notoriously lackluster in this arena. Previously, PyTorch users would need to use something like Flask or Django to build a REST API on top of the model, but now they have native deployment options in the form of TorchServe and PyTorch Live.
TorchServe
TorchServe is an open-source deployment framework resulting from a collaboration between AWS and Facebook (now Meta) and was released in 2020. It has features like endpoint specification, model archiving, and observing metrics; but is still older than the TensorFlow alternative. Both REST and gRPC APIs are supported with TorchServe.
PyTorch Live
PyTorch first released PyTorch Mobile in 2019, which was designed to create an end-to-end workflow for the deployment of optimized machine learning models for Android, iOS, and Linux.
PyTorch Live was released in late 2022 to build upon Mobile. It uses JavaScript and React Native to create cross-platform iOS and Android AI-powered apps with associated UIs. The on-device inference is still performed by PyTorch Mobile. Live comes with example projects to bootstrap from, and has plans to support audio and video input in the future
Deployment - Final Words
Currently, TensorFlow still wins on the deployment front. Serving and TFLite are more robust than the PyTorch competitors, and the ability to use TFLite for local AI in conjunction with Google’s Coral devices is a must-have for many industries. In contrast, PyTorch Live focuses on mobile only, and TorchServe is still in its infancy. The playing field is more even for applications where models run in the cloud instead of on edge devices. It will be interesting to see how the deployment arena changes in the coming years, but for now Round 2 in the PyTorch vs TensorFlow debate goes to TensorFlow.
A final note on the issues of model availability and deployment: For those who want to use the TensorFlow deployment infrastructure but want access to models that are only available in PyTorch, consider using ONNX to port the models from PyTorch to TensorFlow
PyTorch vs TensorFlow - Ecosystems
The final important consideration that separates PyTorch and TensorFlow in 2023 is the ecosystems in which they are situated. Both PyTorch and TensorFlow are capable frameworks from a modeling perspective, and their technical differences at this point are less important than the ecosystems surrounding them, which provide tools for easy deployment, management, distributed training, etc. Let’s take a look at each framework’s ecosystem now.
PyTorch
Hub
Beyond platforms like HuggingFace, there is also the official PyTorch Hub - a research-oriented platform for sharing repositories with pre-trained models. Hub has a wide range of models, including those for Audio, Vision, and NLP. It also has generative models, including a GAN for generating high-quality images of celebrity faces.

PyTorch-XLA
If you want train PyTorch models on Google's Cloud TPUs, then PyTorch-XLA is the tool for you. PyTorch-XLA is a Python package that connects the two with the XLA compiler. You can check out PyTorch-XLA's GitHub repo here.
TorchVision
TorchVision is PyTorch's official Computer Vision library. It includes everything you need for your Computer Vision projects, including model architectures and popular datasets. For more vision models, you can check out TIMM (pyTorch IMage Models). You can check out the TorchVision GitHub repo here.
TorchText
If your area of expertise is Natural Language Processing rather than Computer Vision, then you might want to check out TorchText. It contains datasets frequently seen in the NLP domain, as well as data processing utilities to operate on these and other datasets. You might want to check out fairseq too, so you can perform tasks like translation and summarization on your text. You can check out the TorchText GitHub repo here.
TorchAudio
Perhaps before you can process text, you need to extract it from an audio file with ASR. In this case, check out TorchAudio - PyTorch's official audio library. TorchAudio includes popular audio models like DeepSpeech and Wav2Vec, and provides walkthroughs and pipelines for ASR and other tasks. You can check TorchAudio's GitHub repo here.
SpeechBrain
If TorchAudio isn't quite what you're looking for, then you might want to check out SpeechBrain - an open-source speech toolkit for PyTorch. SpeechBrain supports ASR, speaker recognition, verification and diarization, and more! If you don’t want to build any models and instead want a plug-and-play tool with features like Auto Chapters, Sentiment Analysis, Entity Detection, and more, check out AssemblyAI’s own Speech-to-Text API.
ESPnet
ESPnet is a toolkit for end-to-end speech processing which uses PyTorch in conjunction with Kaldi's style of data processing. With ESPnet, you can implement end-to-end speech recognition, translation, diarization, and more!
AllenNLP
If you're looking for even more NLP tools, you might want to check out AllenNLP, an open-source NLP research library built on PyTorch and backed by the Allen Institute for AI.
Ecosystem Tools
Check out PyTorch’s Tools page for other libraries that may be useful, such as those tailored to Computer Vision or Natural Language Processing. This includes fast.ai - a popular library for producing neural networks using modern best practices.
TorchElastic
TorchElastic was released in 2020 and is the result of collaboration between AWS and Facebook. It is a tool for distributed training which manages worker processes and coordinates restart behaviors so that you can train models on a cluster of compute nodes which can change dynamically without affecting training. Therefore, TorchElastic prevents catastrophic failures from issues such as server maintenance events or network issues so you do not lose training progress. TorchElastic features integration with Kubernetes and has been incorporated into PyTorch 1.9+.
TorchX
TorchX is an SDK for the quick building and deployment of Machine Learning applications. TorchX includes the Training Session Manager API to launch distributed PyTorch applications onto supported schedulers. It is responsible for launching the distributed job while natively supporting jobs that are locally managed by TorchElastic.
Lightning
PyTorch Lightning is sometimes called the Keras of PyTorch. While this comparison is slightly misleading, Lightning is a useful tool for simplifying the model engineering and training processes in PyTorch, and it has matured significantly since its initial release in 2019. Lightning approaches the modeling process in an object-oriented way, defining reusable and shareable components that can be utilized across projects. For more information on Lightning and a comparison of how its workflow compares to vanilla PyTorch, you can check out this tutorial.
TensorFlow
Hub
TensorFlow Hub is a repository of trained Machine Learning models ready for fine-tuning, allowing you to use a model like BERT with just a few lines of code. Hub contains TensorFlow, TensorFlow Lite, and TensorFlow.js models for different use cases, with models available for image, video, audio, and text problem domains. Get started with a tutorial here, or see a list of models here.
Model Garden
If ready-to-use pre-trained models aren’t going to work for your application, then TensorFlow’s Model Garden is a repository that makes the source code for SOTA models available. It is useful if you want to go under-the-hood to understand how models work, or modify them for your own needs - something that is not possible with serialized pre-trained models beyond transfer learning and fine tuning.
Model Garden contains directories for official models maintained by Google, research models maintained by researchers, and curated community models maintained by the community. TensorFlow’s long term goal is to provide pre-trained versions of models from Model Garden on Hub, and for pretrained models on Hub to have available source code in Model Garden.
Extended (TFX)
TensorFlow Extended is TensorFlow's end-to-end platform for model deployment. You can load, validate, analyze, and transform data; train and evaluate models; deploy models using Serving or Lite; and then track artifacts and their dependencies. TFX can be used with Jupyter or Colab, and can use Apache Airflow/Beam or Kubernetes for orchestration. TFX is tightly integrated with Google Cloud and can be used with Vertex AI Pipelines.
Vertex AI
Vertex AI is Google Cloud’s unified Machine Learning platform. It was released this year and seeks to unify services on GCP, AI Platform, and AutoML into one platform. Vertex AI can help you automate, monitor, and govern Machine Learning systems by orchestrating workflows in a serverless manner. Vertex AI can also store artifacts of a workflow, allowing you to keep track of dependencies and a model’s training data, hyperparameters, and source code.
MediaPipe
MediaPipe is a framework for building multimodal, cross-platform applied Machine Learning pipelines which can be used for face detection, multi-hand tracking, object detection, and more. The project is open-source and has bindings in several languages including Python, C++, and JavaScript. More information on getting started with MediaPipe and its ready-to-use solutions can be found here.
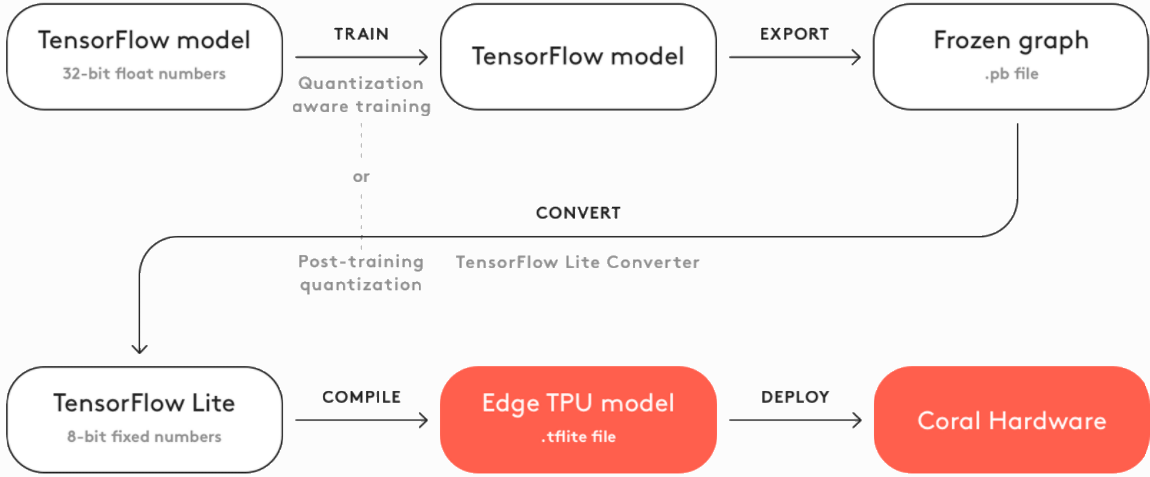
Coral
While there are a variety of SaaS companies that rely on cloud-based AI, there is a growing need for local AI in many industries. Google Coral was created to address this need, and is a complete toolkit to build products with local AI. Coral was released in 2020 and addresses the difficulties of implementing on-board AI mentioned in the TFLite portion of the Deployment section, including privacy and efficiency.
Coral offers an array of hardware products for prototyping, production, and sensing, some of which are essentially more powerful Raspberry Pis created specifically for AI applications. Their products utilize their Edge TPUs for high performance inference on low-power devices. Coral also offers pre-compiled models for image segmentation, pose estimation, speech recognition, and more to provide scaffolding for developers looking to create their own local AI systems. The essential steps to create a model can be seen in the flowchart below.
TensorFlow.js
TensorFlow.js is a JavaScript library for Machine Learning that allows you to train and deploy models both in the browser and server-side with Node.js. They provide documentation with examples and information on how to import Python models, pre-trained models ready for out-of-the-box use, and live demos with associated code.
Cloud
TensorFlow Cloud is a library that allows you to connect your local environment to Google Cloud. The provided APIs are designed to bridge the gap from model building and debugging on your local machine to distributed training and hyperparameter tuning on Google Cloud, without the need to use Cloud Console.
Colab
Google Colab is a cloud-based notebook environment, very similar to Jupyter. It is easy to connect Colab to Google Cloud for GPU or TPU training. Note that PyTorch can also be used with Colab.
Playground
Playground is a small but polished educational tool for understanding the basics of neural networks. It offers a simple dense network visualized inside a clean UI. You can change the number of layers in the network and their sizes to see in real time how features are learned. You can also see how changing hyperparameters like learning rate and regularization strength affects the learning process on different datasets. Playground allows you to play the learning process in real time to see in a highly visual way how inputs are transformed during the training process. Playground even comes with an open-source small neural network library on which it was built so you can understand the nuts and bolts of the network.
Datasets
Google Research’s Datasets is a dataset resource on which Google periodically releases datasets. Google also has a Dataset Search for access to an even wider dataset database. PyTorch users can of course take advantage of these datasets as well.
Ecosystems - Final Words
This round is easily the closest of the three. Google has invested heavily in ensuring that there is an available product in each relevant area of an end-to-end Deep Learning workflow, although how well-polished these products are varies across this landscape. Even still, the close integration with Google Cloud along with TFX make the end-to-end development process efficient and organized, and the ease of porting models to Google Coral devices hands a landslide victory to TensorFlow for some industries. That having been said, it is clear TensorFlow is a fading framework, and the rapid development of ONNX only exacerbates this process given that the TensorFlow ecosystem can be leveraged by teams who build with PyTorch for many applications. For this reason, unlike last year, PyTorch will win this battle.
Round 3 in the PyTorch vs TensorFlow debate goes to PyTorch.
PyTorch 2.0 and JAX
PyTorch 2.0
At the end of 2022, PyTorch 2.0 was announced, and it marks a very substantial shift in the story of Deep Learning frameworks. Just as PyTorch had the benefit of learning from TensorFlow's mistakes, PyTorch 2 has the benefit of learning from PyTorch 1's "mistakes". These "mistakes" are really design decisions that made sense in 2016, but less so in 2023. Deep Learning is much more mature than it was when PyTorch 1 was created - just in the last year we've seen substantial progress in models like DALL-E 2, Stable Diffusion, and ChatGPT.
The flagship feature of PyTorch 2.0 (if you had to pick) is model compilation, which will allow models to be ahead-of-time compiled for lightning-fast execution. PyTorch 2.0 has made efforts to make distributed training simpler too, which means that the lifecycle for PyTorch Deep Learning projects may be reduced.
PyTorch 2.0's first stable release is slated for early March of 2023
JAX
Google's JAX has quickly been growing in popularity. While not a Deep Learning framework itself, it is a numerical computing library with autograd and easy distributed training. Combined with the fact that it is built on XLA, JAX is clearly a very strong candidate for the future of Deep Learning.
The big caveat is that much of its power stems from the fact that JAX takes a functionally-pure approach that may be foreign to PyTorch and TensorFlow practitioners. That having been said, the Deep Learning infrastructure surrounding JAX matures every month; and if the functionally-pure approach does not prove to make JAX a nonstarter, we expect a rapid adoption in the coming years.
At this point, it is apparent that the battle for the future of Deep Learning will be PyTorch 2.0 vs JAX, and only time will tell who the victor is.
Should I Use PyTorch or TensorFlow?
As you probably expect, the PyTorch vs TensorFlow debate does not have a single correct answer - it is only sensible to say that one framework is superior to another with respect to a specific use-case. To help you decide which framework is best for you, we’ve compiled our recommendations into flow charts below, with each chart tailored to a different area of interest.
What if I’m in Industry?
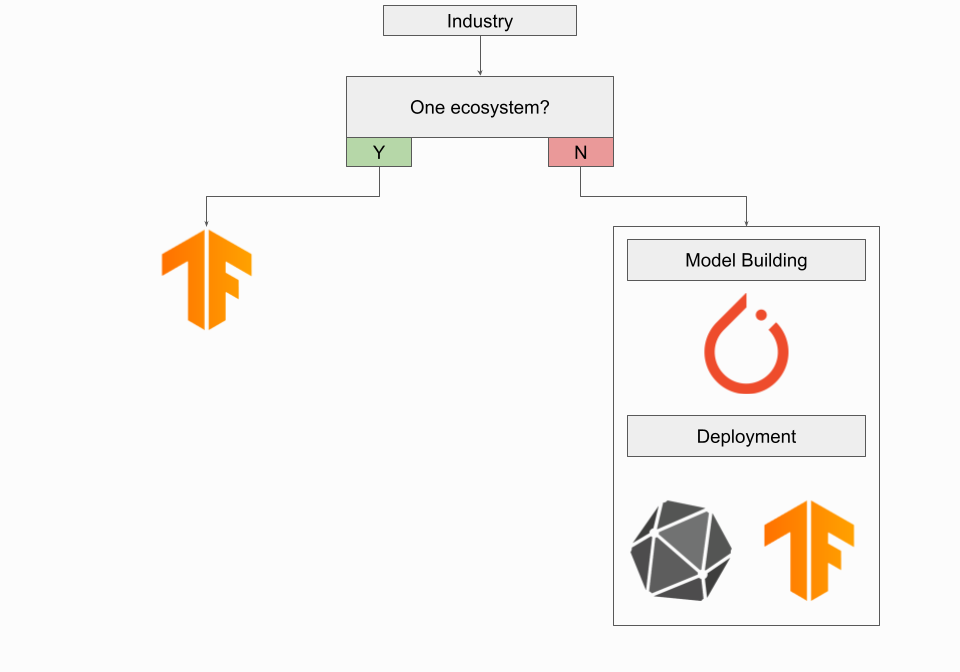
If you perform Deep Learning engineering in an industry setting, you’re likely using TensorFlow. In this case, you should probably stick with it. TensorFlow’s robust deployment framework and end-to-end TensorFlow Extended platform are invaluable for those who need to productionize models. Easy deployment on a gRPC server along with model monitoring and artifact tracking are critical tools for industry use. You may want to start thinking about migrating to PyTorch in the future, but for now you can stick with your current workflow.
On the other hand, if you're starting a project from scratch, it may be advisable to build with PyTorch and then deploy with TensorFlow's tools. If you want to use one ecosystem and don't want to deal with the hassle of ONNX, then TensorFlow remains a good option.
Bottom line: if you have to choose one framework, choose TensorFlow.
What if I’m a Researcher?
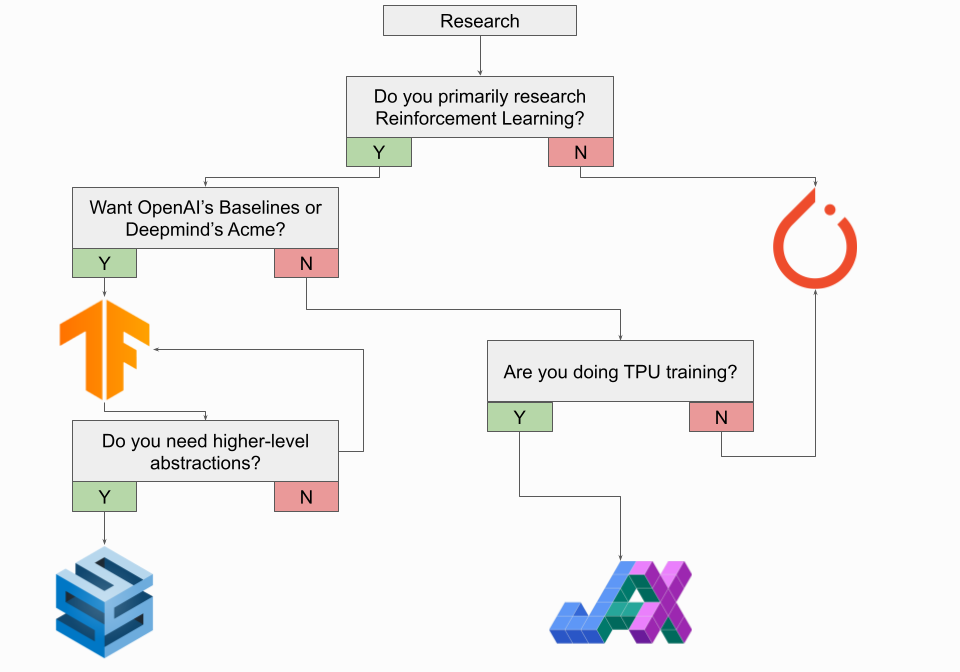
If you’re a researcher, you’re likely using PyTorch and should probably stick with it for now. PyTorch is the de facto research framework, and the announcement of PyTorch 2.0 only makes its future more promising. We certainly encourage you to check out JAX (especially if you train on TPUs) and think about being an early adopter, but most researchers will probably want to stick with PyTorch this year.
There are a couple of notable exceptions to this rule, the most notable being that those in Reinforcement Learning should consider using TensorFlow. TensorFlow has a native Agents library for Reinforcement Learning, and DeepMind’s Acme framework is implemented in TensorFlow. OpenAI’s Baselines model repository is also implemented in TensorFlow, although OpenAI’s Gym can be used with either TensorFlow or PyTorch. If you plan to use TensorFlow for your research, you should also check out DeepMind’s Sonnet for higher-level abstractions. That having been said, Reinforcement Learning is finding its way into more and more Deep Learning research, so a stronger PyTorch ecosystem is likely to develop around it in the coming years.
Whichever framework you choose, you should keep your eye on JAX in 2023, especially as its community grows and more publications begin utilizing it.
Bottom line: if you need to choose one framework, choose PyTorch
What if I’m a Professor?
If you’re a professor, which framework to use for a Deep Learning course depends on the goals of the course. If the focus of your course is to produce industry-ready Deep Learning engineers who can hit the ground running with competency in the entire end-to-end Deep Learning process, not just Deep Learning theory, then you should use TensorFlow. In this case, exposure to the TensorFlow ecosystem and its tools along with end-to-end practice projects will be very instructive and valuable.
If the focus of your course is on Deep Learning theory and understanding the under-the-hood of Deep Learning models, then you should use PyTorch. This is especially true if you are teaching a high-level undergraduate course or an early graduate-level course which intends to prepare students to perform Deep Learning research.
Ideally, students should get exposure to each framework, and dedicating some time to understanding the differences between the frameworks is probably valuable despite the time constraints of a single semester. If the course is part of a larger program in Machine Learning with many classes dedicated to different topics, it may be better to stick with the framework best suited for the course material rather than try to give exposure to both.
What if I’m a Hobbyist?
If you’re a hobbyist who’s interested in Deep Learning, which framework you use will depend on your goals. If you’re implementing a Deep Learning model as part of some larger project, then TensorFlow is likely what you want to use, especially if you are deploying to an IoT/embedded device. While you could use PyTorch for mobile applications given the release of PyTorch Live, TensorFlow + TFLite is still the preferred methodology for now.
If your goal is to learn about Deep Learning for its own sake, then which framework is best in this case depends on your background. In general, PyTorch is probably the better option here, especially if you’re used to working in Python. If you’re a total beginner who’s just getting started learning about Deep Learning, see the next section.
What if I’m a Total Beginner?
If you’re a total beginner who’s interested in Deep Learning and just wants to get started, we recommend using Keras. Using its high-level components, you can easily get started understanding the basics of Deep Learning. Once you are prepared to start understanding more thoroughly the nuts-and-bolts of Deep Learning, you have a couple of options:
If you do not want to install a new framework and are worried about how well your competency will translate to a new API, then you can try “dropping down” from Keras to TensorFlow. Depending on your background, TensorFlow may be confusing, in which case try moving to PyTorch.
If you want a framework that more natively feels like Python, then moving to PyTorch may be your best move. In this case, be aware that you’ll have to install a new framework and potentially rewrite custom scripts. Further, if PyTorch seems a bit cumbersome to you, you can compartmentalize your code and get rid of some boilerplate by using PyTorch Lightning.
If you’re a complete beginner, consider watching some YouTube tutorials in both TensorFlow and PyTorch to decide which framework feels more intuitive to you.
Final Words
As you can see, the PyTorch vs TensorFlow debate is a nuanced one whose landscape is constantly changing, and out-of-date information makes understanding this landscape even more difficult. In 2023, both PyTorch and TensorFlow are very mature frameworks, and their core Deep Learning features overlap significantly. Today, the practical considerations of each framework, like their model availability, time to deploy, and associated ecosystems, supersede their technical differences.
You’re not making a mistake in choosing either framework, for both have good documentation, many learning resources, and active communities. While PyTorch has become the de facto research framework after its explosive adoption by the research community and TensorFlow remains the legacy industry framework, there are certainly use cases for each in both domains.
Hopefully our recommendations have helped you navigate the complicated PyTorch vs TensorFlow landscape! For more helpful information, check out other content on our blog!





{kind=link}
{kind=link}
{kind=link}