The top free speech-to-text APIs, AI models, and open source engines
This post compares the best free Speech-to-Text APIs and AI models on the market today, including APIs that have a free tier. We’ll also look at several free open-source Speech-to-Text engines and explore why you might choose an API vs. an open-source library, or vice versa.



This post compares the best free Speech-to-Text APIs and AI models on the market today—a market that recent market analysis projects will grow from $8.49 billion in 2024 to $23.11 billion by 2030. We'll examine APIs that have a free tier, several free open-source Speech-to-Text engines, and explore why you might choose one vs. the other. We'll also look at several free open-source Speech-to-Text engines and explore why you might choose an API vs. an open-source library, or vice versa.
Choosing the best Speech-to-Text API, AI model, or open-source engine to build with can be challenging. You need to compare accuracy, model design, features, support options, and documentation—factors that a recent insights report found are top-of-mind for developers, including cost (64%), performance (58%), and accuracy (47%).
This post examines the best free Speech-to-Text APIs and AI models on the market today, including ones that have a free tier, to help you make an informed decision. We'll also look at several free open-source Speech-to-Text engines and explore why you might choose an API or AI model vs. an open-source library, or vice versa.
What is a speech-to-text API?
A speech-to-text API converts spoken audio into written text through cloud-based Voice AI models—a deployment method that market data shows accounts for 62% of the market—eliminating the need to build your own speech recognition infrastructure.
As industry projections show, the global market for this technology is expected to reach $19.09 billion by 2025. This growth is driven by the rise of AI voice agents and real-time applications, yet a recent survey found that 95% of people have been frustrated with voice agents, highlighting the need for high-quality underlying technology.
Instead of training models on massive datasets or managing servers, developers simply send audio files to the API and receive accurate transcriptions back.
Modern APIs handle complex audio processing automatically:
- Accent processing: Recognizes different regional and international accents
- Noise filtering: Works effectively with background noise and poor audio quality
- Speaker identification: Distinguishes between multiple speakers in conversations
- Domain terminology: Understands industry-specific vocabulary and jargon
The technology has evolved significantly from early voice recognition systems. As recent analysis confirms, today's speech-to-text APIs combine deep learning models with sophisticated audio processing to deliver near-human accuracy.
Advanced capabilities include:
- Support for dozens of languages
- Real-time streaming transcription
- Speaker diarization for multi-person conversations
- Sentiment analysis and emotion detection
- Automatic punctuation and formatting
For developers and businesses, this means you can add voice capabilities to your applications in days rather than months. Whether you're building a transcription service, adding voice commands to your app, or analyzing customer calls, speech-to-text APIs provide the foundation for Voice AI applications.
Free speech-to-text APIs and Voice AI models
APIs and AI models offer different trade-offs compared to open-source options:
If you're looking to use an API or AI model for a small project or a trial run, many of today's Speech-to-Text APIs and AI models have a free tier. This means that the API or model is free for anyone to use up to a certain volume per day, per month, or per year.
Let's compare three of the most popular Speech-to-Text APIs and AI models with a free tier: AssemblyAI, Google, and AWS Transcribe.
AssemblyAI
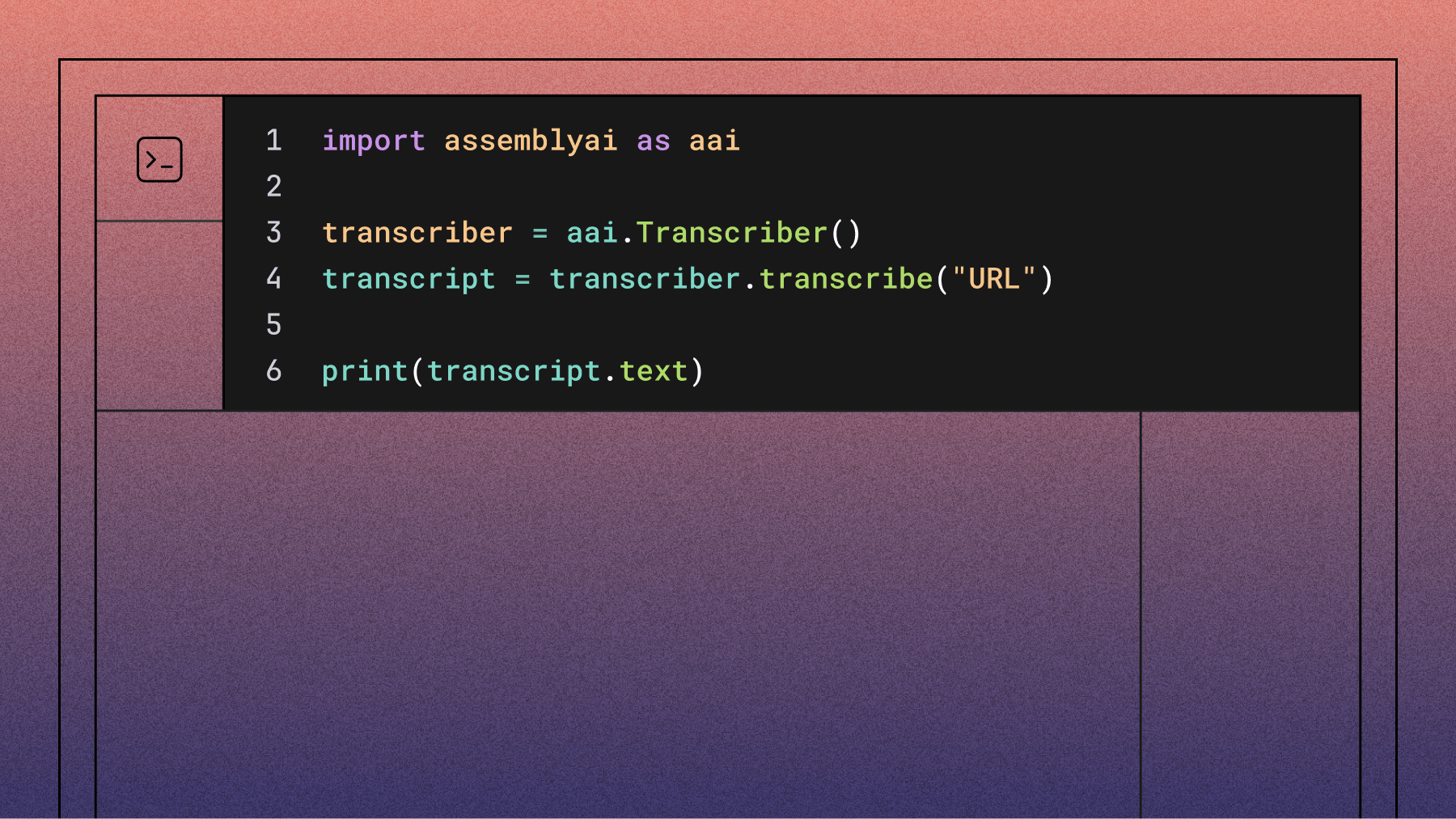
AssemblyAI offers asynchronous (batch) speech-to-text, real-time (streaming) speech-to-text, and additional Voice AI models via an API that product teams and developers can use to build powerful AI solutions based on voice data for their users.
AssemblyAI offers cutting-edge speech understanding models such as Speaker Diarization, Translation, Topic Detection, Entity Detection, Automated Punctuation and Casing, Sentiment Analysis, Summarization, Automatic Language Detection, as well as Guardrails like Content Moderation. These AI models help users get more out of voice data, with continuous improvements being made to accuracy.
The company offers $50 in free transcription credits to get users started, which is enough to process hundreds of hours of audio depending on the models used.
AssemblyAI also offers LLM Gateway. LLM Gateway enables users to leverage Large Language Models (LLMs) to pull valuable information from their voice data—including answering questions, generating summaries and action items, and more. The company also offers its powerful prompt-based Speech Language Model, Universal-3 Pro, which improves industry terminology for specific use cases through prompting.
Its high accuracy and diverse collection of AI models built by AI experts make AssemblyAI a sound option for developers looking for a free Speech-to-Text API, as developer reports indicate accuracy improvements of up to 23% when switching from other providers. The API also supports virtually every audio and video file format out-of-the-box for easier transcription.
AssemblyAI also supports numerous languages at high accuracy other than English--you can see the full list here.
AssemblyAI's easy-to-use models also allow for quick set-up and transcription in any programming language. You can copy/paste code examples in your preferred language directly from the AssemblyAI Docs or use the AssemblyAI Python SDK or another one of its ready-to-use integrations.
Pricing
- Free to test in the AI playground, plus $50 in free credits with an API sign-up
- Speech-to-Text (Universal-2 model) – $0.15 per hour
- Speech-to-Text (Universal-3 Pro model) – $0.21 per hour
- Universal-3 Pro Streaming – $0.45 per hour
- Universal-Streaming (English or Multilingual) – $0.15 per hour
- Whisper Streaming – $0.30 per hour
- Speech understanding – varies
- Volume pricing is also available
See the full pricing list here.
Pros
- High accuracy
- Breadth of AI models available, built by AI experts
- Continuous model iteration and improvement
- Developer-friendly documentation and SDKs
- Pay as you go and custom plans
- White glove support
- Strict security and privacy practices
Cons
- Models are not open-source
Google Speech-to-Text is a well-known speech transcription API. Google gives users 60 minutes of free transcription, with $300 in free credits for Google Cloud hosting.
Google only supports transcribing files already in a Google Cloud Bucket, so the free credits won't get you very far. Google also requires you to sign up for a GCP account and project — whether you're using the free tier or paid.
With good accuracy and 125+ languages supported, Google is a decent choice if you're willing to put in some initial work.
Pricing
- 60 minutes of free transcription
- $300 in free credits for Google Cloud hosting
Pros
- Free tier
- Decent accuracy
- Multi-language support
Cons
- Only supports transcription of files in a Google Cloud Bucket
- Difficult to get started
- Lower accuracy than other similarly-priced APIs
AWS Transcribe
AWS Transcribe offers one hour free per month for the first 12 months of use.
Like Google, you must create an AWS account first if you don't already have one. AWS also has lower accuracy compared to alternative APIs and only supports transcribing files already in an Amazon S3 bucket.
However, if you're looking for a specific feature, like medical transcription, AWS has some options. Its Transcribe Medical API is a medical-focused ASR option that is available today.
Pricing
- One hour free per month for the first 12 months of use
- Tiered pricing, based on usage, ranges from $0.02400 to $0.00780
Pros
- Integrates into existing AWS ecosystem
- Medical language transcription
- Decent accuracy
Cons
- Difficult to get started from scratch
- Only supports transcribing files already in an Amazon S3 bucket
- Lower accuracy than other similarly-priced APIs
How to evaluate speech-to-text solutions
Choosing the right speech-to-text solution requires evaluating multiple factors beyond just free tier offerings. A systematic approach ensures your solution scales and delivers reliable production results.
Key evaluation criteria:
- Accuracy testing: Performance with your specific audio conditions
- Feature completeness: Available capabilities and integrations
- Developer experience: Documentation quality and SDK availability
- Scalability limits: Concurrent processing and rate limits
- Total cost of ownership: All costs including development time
Accuracy testing for your use case
Accuracy varies dramatically based on audio conditions and content type. Test potential solutions using audio samples that match your specific environment:
- Audio conditions: Same background noise levels and recording quality
- Speaker characteristics: Similar accents and speaking patterns
- Content type: Industry-specific terminology and conversation styles
- Model specialization: Phone call optimization vs. video content models
Look for providers offering customization through prompting to improve accuracy on technical terms specific to your domain.
Feature completeness
Modern speech-to-text APIs offer features beyond basic transcription. Essential capabilities to evaluate include speaker diarization for multi-speaker conversations, automatic punctuation and formatting for readable transcripts, real-time streaming for live applications, and batch processing for large volumes of pre-recorded audio.
Consider which features are must-haves versus nice-to-haves for your application. Features like sentiment analysis or topic detection might be critical for call analytics but unnecessary for simple transcription tasks.
Developer experience and documentation
The quality of documentation and developer tools significantly impacts implementation speed, as independent reviews confirm, with some developers reporting production-ready implementations in just hours. Well-designed APIs provide clear getting-started guides, code examples in multiple languages, comprehensive API references, and responsive support channels.
SDKs and pre-built integrations accelerate development. A solution with official libraries for your programming language and integrations with your existing tools saves considerable development time compared to working with raw API endpoints.
Scalability and reliability
Free tiers help you test, but production applications need consistent performance at scale. Evaluate how the API handles concurrent requests, what rate limits exist, and whether the provider offers guaranteed uptime SLAs.
Infrastructure considerations include geographic availability of endpoints, redundancy and failover capabilities, and whether the provider can handle sudden traffic spikes without degradation.
Total cost of ownership
The true cost extends beyond per-minute pricing. Consider these key cost factors:
Development costs:
Initial integration time and ongoing maintenance updates
Infrastructure costs:
Server hosting, scaling, and monitoring for self-hosted solutions
Engineering overhead:
Error handling, edge case management, and model improvements
API-based solutions typically offer lower total cost of ownership when accounting for engineering resources required for self-hosted alternatives, as some teams find that the infrastructure overhead for open-source models can cost more than using hosted APIs. As a recent report highlights, the financial burden of in-house AI implementation includes not just infrastructure but also hiring specialized talent, ongoing maintenance, and ensuring compliance.
Open-source speech transcription engines
An alternative to APIs and AI models, open-source Speech-to-Text libraries are completely free--with no limits on use. Some developers also see data security as a plus, since your data doesn't have to be sent to a third party or the cloud. However, security remains a top concern across the board, with a 2025 market survey finding that over 30% of teams view data privacy as a significant challenge when integrating speech recognition.
There is work involved with open-source engines, so you must be comfortable putting in a lot of time and effort to get the results you want, especially if you are trying to use these libraries at scale. In fact, industry analysis suggests that most teams underestimate the engineering effort required to get open-source solutions production-ready. Open-source Speech-to-Text engines are typically less accurate than the APIs discussed above.
If you want to go the open-source route, here are some options worth exploring:
DeepSpeech
DeepSpeech is an open-source embedded Speech-to-Text engine that was designed to run in real-time on a range of devices, from high-powered GPUs to a Raspberry Pi 4. While it was a popular option that used an end-to-end model architecture pioneered by Baidu, the project is no longer actively maintained by Mozilla as of late 2022. It has decent out-of-the-box accuracy for an open-source option and is easy to fine-tune, but lacks ongoing support and updates.
Pros
- Easy to customize
- Can use it to train your own model
- Can be used on a wide range of devices
Cons
- No longer actively maintained by Mozilla (archived late 2022)
- Lack of official support
- No model improvements outside of individual custom training
- Heavy lift to integrate into production-ready applications
See Also: DeepSpeech Tutorial for Asynchronous and Real-time transcription
Kaldi
Kaldi is a speech recognition toolkit that has been widely popular in the research community for many years.
Like DeepSpeech, Kaldi has good out-of-the-box accuracy and supports the ability to train your own models. It's also been thoroughly tested—a lot of companies currently use Kaldi in production and have used it for a while—making more developers confident in its application.
Pros
- Decent accuracy
- Can use it to train your own models
- Active user base
Cons
- Can be complex and expensive to use
- Uses a command-line interface
- Heavy lift to integrate into production-ready applications
You May Also Like: Kaldi Speech Recognition for Beginners Tutorial
Flashlight ASR (formerly Wav2Letter)
Flashlight ASR, formerly Wav2Letter, is Facebook AI Research's Automatic Speech Recognition (ASR) Toolkit. It is also written in C++ and uses the ArrayFire tensor library.
Like DeepSpeech, Flashlight ASR is decently accurate for an open-source library and is easy to work with on a small project.
Pros
- Customizable
- Easier to modify than other open-source options
- Processing speed
Cons
- Very complex to use
- No pre-trained libraries available
- Need to continuously source datasets for training and model updates, which can be difficult and costly
SpeechBrain
SpeechBrain is a PyTorch-based transcription toolkit. The platform releases open implementations of popular research works and offers a tight integration with Hugging Face for easy access.
Overall, the platform is well-defined and constantly updated, making it a straightforward tool for training and finetuning.
Pros
- Integration with Pytorch and Hugging Face
- Pre-trained models are available
- Supports a variety of tasks
Cons
- Even its pre-trained models take a lot of customization to make them usable
- Lack of extensive docs makes it not as user-friendly, except for those with extensive experience
Coqui
Coqui is another deep learning toolkit for Speech-to-Text transcription. Coqui is used in over twenty languages for projects and also offers a variety of essential inference and productionization features.
The platform also releases custom-trained models and has bindings for various programming languages for easier deployment.
Pros
- Generates confidence scores for transcripts
- Large support community
- Pre-trained models are available
Cons
- No longer updated and maintained by Coqui
- No model improvement outside of individual custom training
- Heavy lift to integrate into production-ready applications
Whisper
Whisper by OpenAI, released in September 2022, is comparable to other current state-of-the-art open-source options.
Whisper can be used either in Python or from the command line and can also be used for multilingual translation.
Whisper has five different models of varying sizes and capabilities, depending on the use case, including v3 released in November 2023.
However, you'll need fairly large computing power and access to an in-house team to maintain, scale, update, and monitor the model to run Whisper at a large scale, making the total cost of ownership higher compared to other options.
As of March 2023, Whisper is also now available via API. On-demand pricing starts at $0.006/minute.
Pros
- Multilingual transcription
- Can be used in Python
- Five models are available, each with different sizes and capabilities
Cons
- Need an in-house research team to maintain and update
- Costly to run
- Heavy lift to integrate into production-ready applications
See Also: How to run OpenAI's Whisper speech recognition model
Understanding free tier limitations and scaling considerations
Free tiers provide an excellent starting point for testing speech-to-text solutions, but understanding their boundaries helps you plan for growth.
Common free tier restrictions:
- Usage caps: 1-400+ hours per month depending on provider
- Concurrency limits: Restricted simultaneous audio processing
- Feature restrictions: Advanced capabilities like speaker diarization or real-time streaming may require paid plans
- Overage policies: Automatic transition to paid tiers or service suspension
Planning for scale
Your usage patterns determine when you'll outgrow free tiers. A podcast transcription service processing weekly episodes might stay within limits indefinitely, while a customer service tool analyzing hundreds of daily calls will quickly exceed them.
Consider not just current usage but growth trajectories. If you're processing 50 hours monthly today but growing at a significant rate, you'll hit paid tiers within months. Planning for this transition ensures smooth scaling without service interruptions.
Cost modeling beyond free tiers
Understanding pricing models helps you budget effectively. Most APIs charge per minute or hour of audio processed, with rates varying based on features used. Real-time transcription often costs more than batch processing, and additional features like translation or sentiment analysis typically incur extra charges.
Volume discounts become available at higher usage levels. Providers often offer tiered pricing where per-minute costs decrease as volume increases, or enterprise agreements for predictable high-volume usage.
Migration strategies
Moving from free to paid tiers should be seamless. Well-designed APIs require no code changes—you simply update billing information. However, switching between providers is more complex, potentially requiring updates to API calls, response handling, and feature implementations.
Building with abstraction layers from the start simplifies future migrations. Rather than tightly coupling your application to a specific provider's API, create an interface that standardizes how your application interacts with speech-to-text services.
Which free speech-to-text API, Voice AI model, or open-source engine is right for your project?
The best free Speech-to-Text API, AI model, or open-source engine will depend on your project. Do you want something that is easy-to-use, has high accuracy, and has additional out-of-the-box features? If so, one of these APIs might be right for you:
Alternatively, you might want a completely free option with no data limits—if you don't mind the extra work it will take to tailor a toolkit to your needs. If so, you might choose one of these open-source libraries:
Whichever you choose, make sure you find a product that can continually meet the needs of your project now and what your project may develop into in the future.
Getting started with speech-to-text integration
Once you've evaluated your options and selected a solution, the next step is implementation. Modern speech-to-text APIs are designed for rapid integration, allowing you to get your first transcription working in minutes rather than days.
Quick start with APIs
API-based solutions offer the fastest path to working transcription. The typical integration process involves signing up for an account and obtaining API credentials, installing the SDK for your programming language, and making your first API call with a test audio file.
Most providers offer interactive playgrounds where you can test transcription without writing code. This helps you quickly assess quality and features before committing to integration.
Integration best practices
Start with the simplest possible implementation—transcribing a single audio file—before adding complexity. This baseline helps you understand the API's behavior and response format. Once basic transcription works, layer in additional features like speaker diarization or sentiment analysis as needed.
Error handling deserves special attention. Network issues, rate limits, and malformed audio files are common failure points. Robust applications implement retry logic, graceful degradation, and clear error messaging to users.
Development workflow optimization
Create a consistent testing dataset with various audio samples representing your use cases. This enables rapid iteration and quality comparison across different configurations or providers. Include samples with background noise, multiple speakers, technical terminology, and various audio qualities.
Version control your integration code separately from your main application when possible. This modular approach simplifies updates and makes it easier to swap providers if needed.
Moving to production
Production deployment requires additional considerations beyond basic functionality. Implement monitoring to track usage, errors, and performance metrics. Set up alerts for approaching usage limits or unusual error rates. Consider implementing caching for frequently transcribed content to reduce costs.
Security becomes critical in production. Store API keys securely using environment variables or secret management services, never hardcode them. Implement proper authentication and authorization for any endpoints that trigger transcription.
If you're ready to start building with Voice AI, you can begin testing immediately with AssemblyAI's comprehensive platform. Try our API for free and see how quickly you can add professional-grade transcription to your application.
Frequently asked questions about free speech-to-text APIs
What's the difference between speech-to-text APIs and speech recognition APIs?
These terms are used interchangeably and both refer to services that convert spoken audio into written text. "Speech-to-text" describes the function while "ASR" or "speech recognition" refers to the underlying technology.
How accurate are free speech-to-text APIs compared to paid versions?
Free and paid tiers typically use the same underlying AI models, so accuracy remains consistent. The main differences are usage limits and access to advanced features.
When should I choose an API over an open-source solution?
Choose APIs for rapid deployment and minimal maintenance in production applications. Open-source solutions work better when you have ML engineering resources and specific customization needs.
What happens when I exceed free tier limits?
Providers either stop processing requests until the next billing cycle or automatically transition to paid pricing. Review your provider's specific policies and set up usage monitoring to avoid service interruptions.
Can free speech-to-text APIs handle multiple languages?
Yes, leading providers support 100+ languages on free tiers with automatic language detection. Most can transcribe multiple languages within the same audio file.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts