
Blog
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.








No results found!
Please try different search parameters.
Featured



Releases & updates

Insights & use cases
News
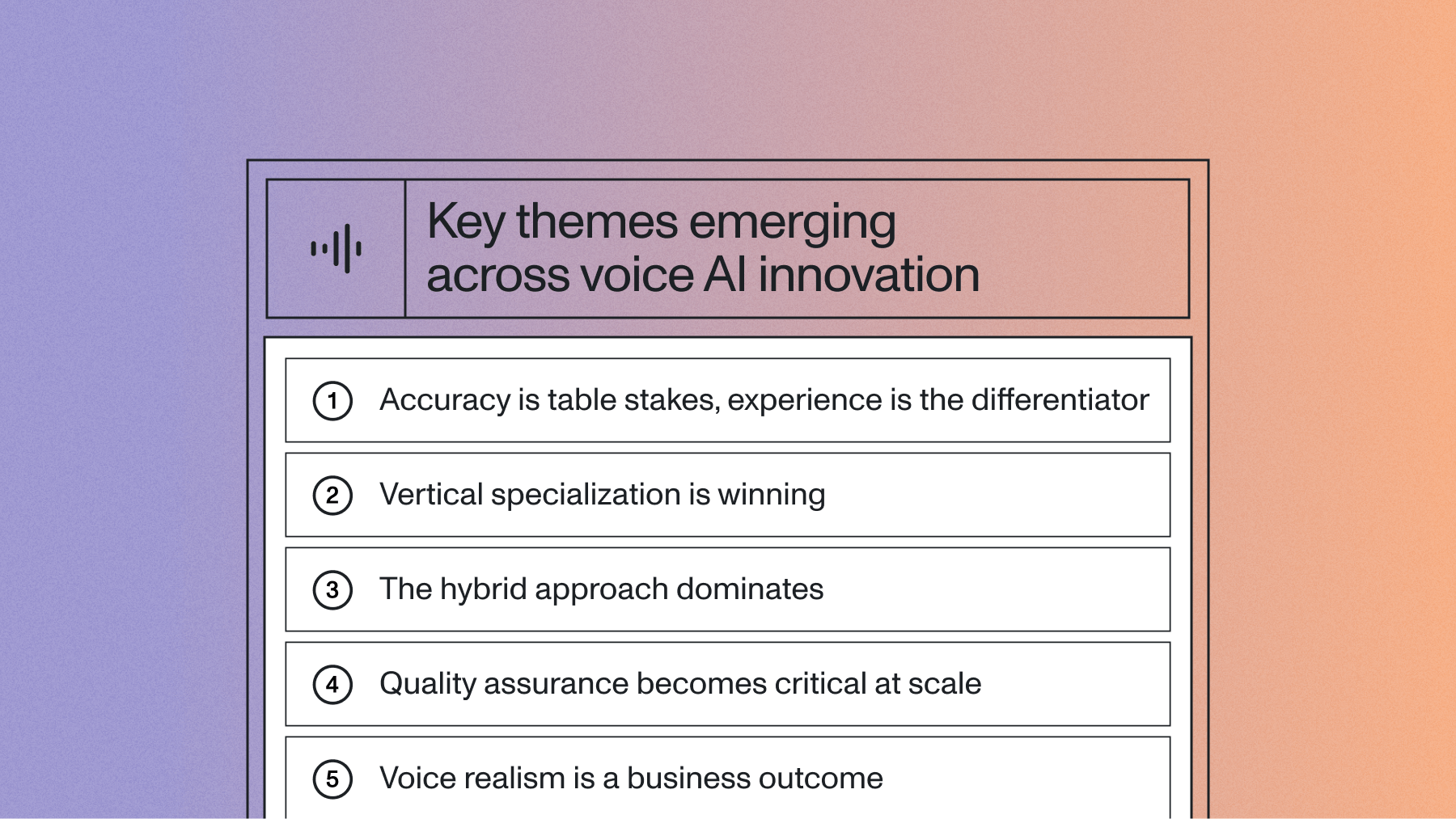


Video

.png)


Newsletter



Subscribe to AssemblyAI’s newsletter
Oops! Something went wrong while submitting the form.
Unlock the value of voice data
Build what’s next on the platform powering thousands of the industry’s leading of Voice AI apps.


