How intelligent turn detection (endpointing) solves the biggest challenge in voice agent development
Voice agents struggle with turn detection, or endpointing, leading to awkward pauses and interruptions. Learn how semantic endpointing with Universal-Streaming delivers natural conversations through intelligent end-of-turn detection, replacing traditional silence-based methods with contextual understanding.


Voice agents enable natural conversations between humans and AI systems, representing one of Speech AI's fastest-growing applications. They create fluid, human-like interactions powered by a range of AI models.
The AI agent market has driven advancements across the ecosystem, from foundational models like AssemblyAI's Universal-Streaming to high-level orchestrators like Pipecat by Daily and LiveKit Agents. These improvements have driven parallel growth in how AI agents reach market, whether through platforms like Vapi that enable easy agent building, or companies like Siro that deliver voice agents specifically for sales training.
However, there's a persistent challenge for all these applications that engineers and researchers have been trying to address for a long time—turn detection. How can an AI agent determine when a human finishes speaking so it can respond? This article explores how end-of-turn detection challenges widespread AI agent adoption and examines current approaches for addressing this challenge, including semantic endpointing methods that analyze speech content rather than relying solely on silence detection.
Latency in voice agents
User experience is paramount for voice agent developers. A big component is latency. Voice agent engineers now prioritize lower latency over accuracy for many use cases. This has led to a confusing landscape when it comes to streaming models.
There are generally three fundamental latencies when measuring a streaming speech-to-text (STT) model.
- Partial transcript latency – this measures how quickly after someone speaks that a model returns a partial transcript (or partial) of what's being said
- Final transcript latency – this measures how quickly after someone finishes speaking a finalized transcript (or final) of what's being said
- Endpointing latency – also known as end-of-turn latency or turn detection latency, this measures how quickly a model determines that someone is done speaking after they finish their speech
Voice agent use cases prioritize different latency types. For example, use cases where it's important to get some transcript back as quickly as possible, like live captioning, care about partial transcript latency. Other use cases where it's important to send finalized transcripts as quickly as possible, like simple voice command UIs, care about final transcript latency. And finally other use cases where it's important to know when a user is done speaking, like voice agents, care about endpointing latency.
To further compound the confusion, some providers' transcripts are mutable. This means that the model can retroactively change already-predicted words. In contrast, AssemblyAI's Universal-Streaming model emits immutable transcripts from the start.
While latency is important, voice agent developers have arguably overoptimized on this axis to address the underlying problem that is endpointing. The ability to quickly and accurately detect an end of turn saves a significant amount of time and renders latency overoptimization as the result of an XY problem.
In other words, while developers have been focused on shaving milliseconds on latency, the elephant in the room has been end-of-turn delay. It is a completely different order of magnitude, and addressing turn detection provides far greater improvements to the user experience than incremental latency optimizations.
So, what endpointing methods are available and how do they affect latency?
3 endpointing methods
The first method is rudimentary and leads to poor user experience—manual endpointing. In this approach, the user performs some action to indicate to the AI agent that they are done with their speech. This would most likely manifest as pressing a button on a webpage or a digit on a phone, but could also be implemented as something like a key phrase to say at the end of speech. While response time could be fast, this creates poor user experience that will harm user adoption.
The second, and currently most common method, uses silence detection. This approach waits until the user has not spoken for a specified amount of time—a tunable threshold. This approach is much better than manual endpointing, but is not optimal. The silence threshold needs to be long enough to avoid preemptive interruptions, but not so long that the conversation does not feel fluid. As it turns out, this is a fairly hard target to hit.
The final approach is semantic endpointing, utilized by our latest Universal-Streaming model. It is an intelligent endpointing paradigm that uses a range of semantic features to understand when a user is done speaking, rather than use proxy methods to guess.
What is semantic endpointing?
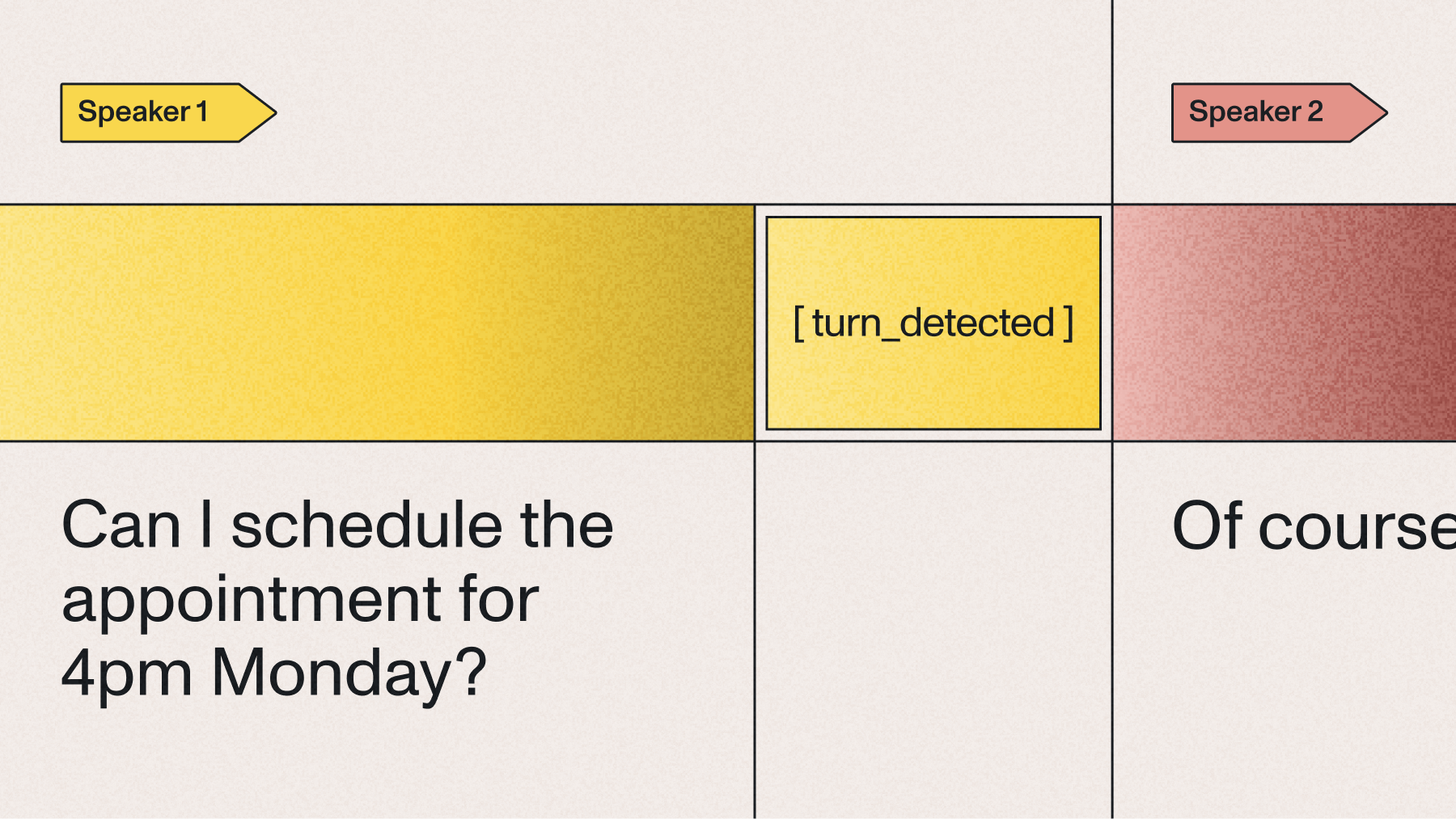
Semantic endpointing analyzes what someone says, not just when they stop talking. Unlike traditional methods that rely on silence duration, it understands when a thought is complete.
For example, it can distinguish between a natural pause mid-sentence ("I went to the store... and then bought some milk") and the end of a complete utterance ("I went to the store and bought some milk."). This creates more natural voice interactions by avoiding premature cutoffs during longer responses and reducing the awkward delays that occur when systems wait for arbitrary silence thresholds.
Modern implementations use language models to predict sentence boundaries and semantic completeness, making voice interfaces feel more conversational and responsive.
How does semantic endpointing work?
Semantic endpointing is more of an umbrella term, and there many potential methods by which one might do it. Universal-Streaming uses semantic endpointing by predicting a special token, which the model learns to appropriately predict given context during training.
There are a series of user-configurable options here that allow voice agent developers to tune the model as their use case requires. In general, several conditions are met for a semantic end-of-turn:
- The model has predicted an end of turn with sufficient confidence, configured via the end_of_turn_confidence_threshold parameter (default: 0.7)
- A minimum silence duration has passed (to prevent false positives), configured via the min_end_of_turn_silence_when_confident parameter (default: 160ms)
- And there is a minimal amount of speech, again to prevent false positives due to noise in the audio signal
Additionally, traditional silence-based endpointing is enabled for completeness as a final catch-all for unusual speech patterns that the model may not predict an end-of-turn for. This is configured in Universal-Streaming via the max_turn_silence parameter (default: 2400ms).
To get started with Universal-Streaming's intelligent endpointing, you can connect to the WebSocket endpoint at wss://streaming.assemblyai.com/v3/ws using your API key. The streaming API provides real-time access to both transcription and endpointing capabilities, enabling you to build responsive voice agents with natural turn-taking behavior.
Comparing turn detection models: LiveKit vs Pipecat vs AssemblyAI
Here, we'll compare three different approaches to turn detection, each with unique architectures and trade-offs.
LiveKit: Semantic-only approach
LiveKit's turn detection model takes a text-first approach, analyzing only the semantic content of transcribed speech without considering audio context.
Key characteristics:
- Input: Transcribed text only
- Dependency: Requires Voice Activity Detection (VAD) to trigger
- Processing: Runs after VAD detects end of speech
Strengths:
- Simple, focused approach on semantic completeness
- Open source availability allows for customization
Limitations:
- Heavy dependence on VAD accuracy—if VAD is continuously triggered by background noise, turn detection can be significantly delayed
- Doesn't leverage audio cues that humans naturally use to detect turn boundaries
- Tends to default to maximum delay periods, potentially creating sluggish conversation flow
Pipecat: Audio-centric detection
Pipecat takes the opposite approach, focusing exclusively on audio characteristics like prosody, intonation, and vocal patterns to predict turn endings.
Key characteristics:
- Input: Audio features only (prosody, intonation)
- Dependency: Direct audio analysis
- Processing: Real-time audio pattern recognition
Strengths:
- Leverages natural audio cues that indicate turn completion
- Can potentially detect turns faster than text-dependent models
- Open source flexibility
Limitations:
- Sensitive to background noise interference
- Performance varies significantly with speaker accents and speech patterns
- Limited by audio quality and availability
- May struggle with speakers who have atypical prosodic patterns
AssemblyAI: Hybrid approach
AssemblyAI combines both semantic content analysis and audio context, creating a more sophisticated turn detection system.
Key characteristics:
- Input: Both transcribed text and audio context
- Dependency: Integrated approach with dynamic thresholds
- Processing: Can end turns early during silence based on syntactic completeness
Strengths:
- Robust performance across various acoustic conditions
- Dynamic adaptation based on sentence completeness rather than static VAD thresholds
- Better handling of background noise due to semantic analysis backup
- More natural conversation flow with context-aware timing
Limitations:
- Closed source limits customization options
- Potentially higher computational requirements
- Dependency on quality transcription for optimal performance
Comparison matrix
Which model should you choose?
Choose LiveKit if:
- You need a simple, semantic-focused approach
- You have clean audio environments with minimal background noise
- Response speed is less critical than accuracy
Choose Pipecat if:
- You have consistent speaker profiles and clean audio
- You want to experiment with pure audio-based detection
Choose AssemblyAI if:
- You want to use both semantic and acoustic endpointing
- You handle diverse speakers and noisy environments
- Natural conversation flow is critical
- Deployment flexibility
The future of turn detection
The comparison reveals an interesting evolution in turn detection approaches. While single-modality solutions (text-only or audio-only) offer simplicity and specialized performance, hybrid approaches like Assembly AI's demonstrate the benefits of combining multiple signal types for more robust and natural conversational experiences.
As conversational AI continues to mature, we can expect to see more sophisticated models that not only combine semantic and prosodic features but also incorporate conversational context, speaker identification, and even visual cues in multimodal scenarios.
The choice between these models ultimately depends on your specific use case requirements, technical constraints, and the trade-offs you're willing to make between accuracy, speed, and robustness.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts