The Full Story of Large Language Models and RLHF
Large Language Models have been in the limelight since the release of ChatGPT, with new models being announced seemingly every week. This guide walks through the essential ideas of how these models came to be.




In this article we give a comprehensive overview of what’s really going on in the world of Language Models, building from the foundational ideas, all the way to the latest advancements.
- What is the learning process of a language model?
- How is Reinforcement Learning from Human Feedback (RLHF) used in the attempt to make language models more aligned with human values?
- What makes these models dangerous or not aligned with human intentions in the first place?
We are going to explore these and other essential questions from the ground up, without assuming prior technical knowledge in AI and machine learning.
To learn more about the limitations of RLHF, you may want to read the following dedicated piece:
How RLHF Preference Model Tuning Works (And How Things May Go Wrong)
Language Intelligence
Thanks to the widespread adoption of ChatGPT, millions of people are now using Conversational AI tools in their daily lives. At its essence, ChatGPT belongs to a class of AI systems called Large Language Models, which can perform an outstanding variety of cognitive tasks involving natural language.
The number of people interacting with this relatively new technology has seen an extraordinary acceleration in the last few months. ChatGPT alone rapidly surpassed 100 million unique users shortly after its release, which represents the most rapid adoption of any service in the history of the internet.
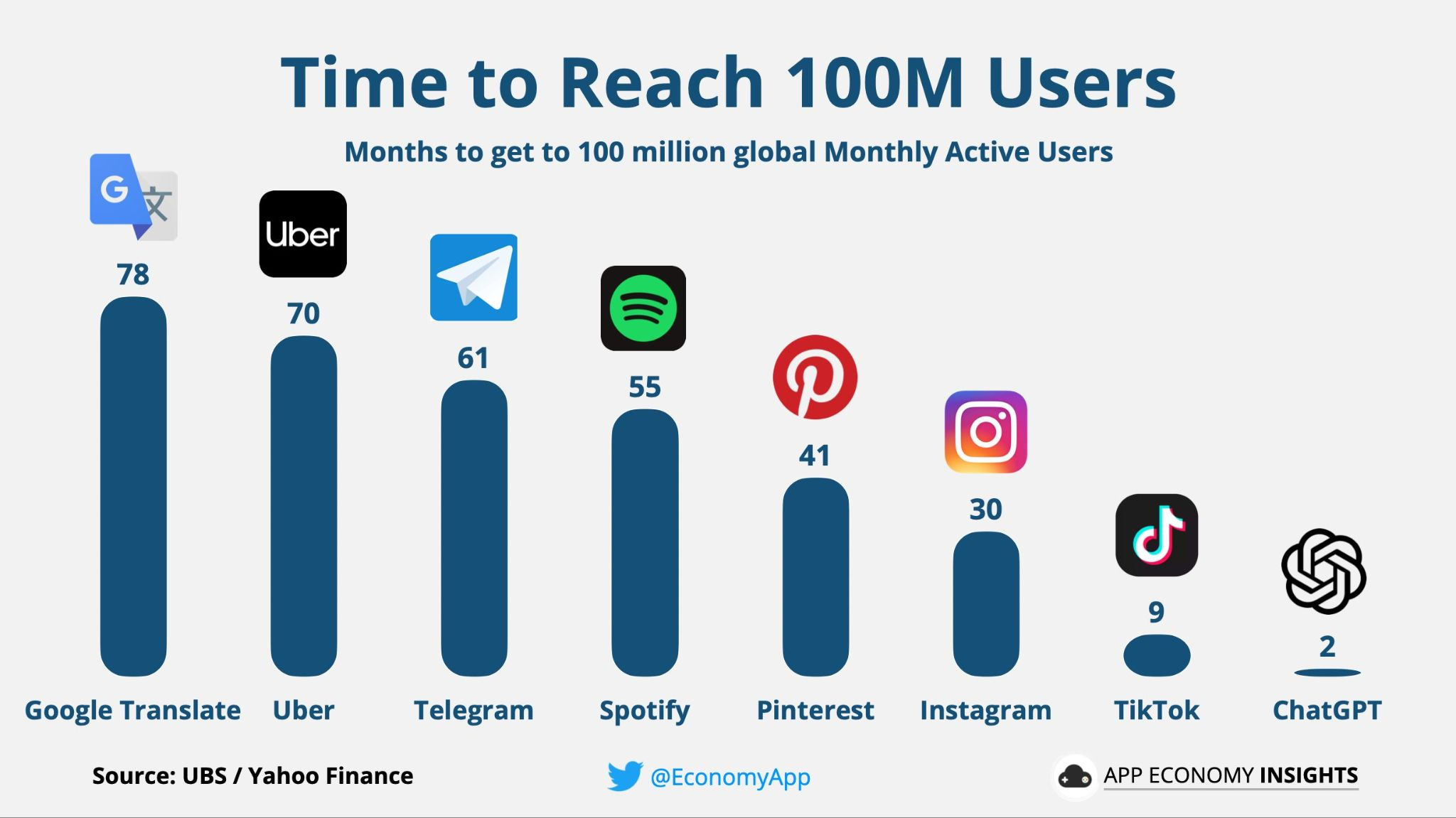
The problem of how to mitigate the risks and misuse of these AI models has therefore become a primary concern for all companies offering access to large language models as online services. With perils of misinformation, plagiarism, the unintended reproduction of offensive or discriminative content, or simply the lack of factuality or ground truth intrinsic to a language model’s output generation mechanism, a failure to successfully address these issues might end up compromising the public trust in the actual potential of this new technology.
Effective methods allowing for better control, or steerability, of large-scale AI systems are currently in extremely high demand in the world of AI research. RLHF is perhaps the most popular of the current methods. We are going to illustrate the key ideas behind this method.
Let’s start by revising the fundamental ideas around language models, how they are trained, and how they actually work.
Language as Computation
Can the processes of language and communication be reduced to computation?
Language Models (LMs) are a class of probabilistic models explicitly tailored to identify and learn statistical patterns in natural language. The primary function of a language model is to calculate the probability that a word succeeds a given input sentence.

How are these models trained to do this? The core process is a general technique known as self-supervised learning, a learning paradigm that leverages the inherent structure of the data itself to generate labels for training.
In the context of natural language processing, self-supervised learning enables models to learn from unannotated text, rather than relying on manually labeled data, which is relatively scarce and often expensive.
During the training process, an LM is fed with a large corpus (dataset) of text and tasked with predicting the next word in a sentence. In practice, this is often achieved by randomly truncating the last part of an input sentence and training the model to fill in the missing word(s). As the model iterates through numerous examples, it learns to recognize and internalize various linguistic patterns, rules, and relationships between words and concepts. One can say that via this process the model creates an internal representation of language.

The outcome of this training process is a pre-trained language model. By exposure to diverse linguistic patterns, the model is equipped with a foundation for understanding natural language and for generating contextually appropriate and coherent text. Some people refer to such pre-trained models as foundation models.
Exploiting a Pre-trained Model: Fine-Tuning & Transfer Learning
Why and how is a pre-trained model useful?
One way to unlock the potential of a pre-trained model is via the process of fine-tuning. The goal is to further upskill a pre-trained model for very specific tasks or to refine and adapt its general non-specialized knowledge (acquired during the pre-training phase) to more specialized domains.

Fine-tuning may involve further training the pre-trained model on a smaller, task-specific labeled dataset, using supervised learning. This step builds upon the linguistic foundation established during pre-training and enables the model to perform a variety of practical tasks with higher accuracy.
An example is machine translation, where a pre-trained language model can be fine-tuned on a parallel corpus containing sentences in the source language along with their translations in the target language. Through this process, the model learns to map the linguistic structures and patterns between the two languages, ultimately enabling it to translate text effectively.
Another common use of fine-tuning is to adapt a pre-trained model to technical or specialized knowledge domains, such as the medical or legal fields. For example, a pre-trained LM could be fine-tuned on a collection of legal documents to facilitate tasks like understanding and summarization of legal agreements. By doing so, the model becomes proficient in handling the unique vocabulary, syntax, and stylistic conventions prevalent in that specific domain.

This process of adapting pre-trained models to new tasks or domains is an example of Transfer Learning, a fundamental concept in modern deep learning. Transfer learning allows a model to leverage the knowledge gained from one task and apply it to another, often with minimal additional training. This concept is not exclusive to natural language processing, and has also been employed in other domains.
From Language Models to Large Language Models
How good can a language model become?
As it turns out, the effectiveness of LMs in performing various tasks is largely influenced by the size of their architectures. These architectures are based on artificial neural networks, which are computational models loosely inspired by the structure and functioning of biological neural networks, such as those in the human brain. Artificial neural networks consist of interconnected layers of nodes, or “neurons” which work together to process and learn from data.
Neurons in the network are associated with a set of numbers, commonly referred to as the neural network’s parameters. The numerical value of these parameters is supposed to represent the strength of connections between different neurons. The parameters within a neural network are adjustable, and they get iteratively updated during the training process to minimize the difference between the model's predictions and the actual target values.

In the context of LMs in particular, larger networks with more parameters have been shown to achieve better performance. Intuitively, the more parameters, the greater their “storage capacity”, even though it should be noted that language models do not store information in a way comparable to the standard way storage memory works in computers (hard drives).
Essentially, a higher number of parameters allows the model to “internalize” a greater variety of statistical patterns (via the numerical relationships of its parameters) within the language data they are exposed to. Larger models, however, also require more computational resources and training data to reach their full potential.

Transformers: The King of AI Architectures
A language model is more than just a neural net.
Modern language models comprise various components or blocks, often formed by different neural networks, each designed to perform specific tasks and featuring specialized architectures. Virtually all current LMs are based on a particularly successful choice of architecture: the so-called Transformer model, invented in 2017.
Starting from the field of Natural Language Processing (NLP), Transformers have been revolutionizing nearly all areas of applied AI, due to their efficiency at processing large chunks of data at once (parallelization) rather than sequentially, a feature that allowed for training on bigger datasets than previous existing architectures. On text data, Transformers have proved exceptionally good at carrying out a form of natural language contextual understanding, which made them the de facto standard choice for most NLP tasks nowadays. Two components are key for this success: the attention mechanism and word embeddings.
- Word Embeddings are high-dimensional vector representations of words that capture their semantic and syntactic properties. These representations enable the model to numerically manipulate words in a mathematical space, a sort of semantic space, where physically nearby words share some form of relationship of meaning or other kinds of similarities. Instead of treating words as isolated entities, word embeddings allow the model to learn and understand the complex interplay of words within a given context.
- Attention Mechanisms allow the model to weigh the importance of different words or phrases in the text. This helps the model to selectively focus on specific parts of the input, assigning different attention scores to the words based on their relevance to the task at hand. Attention can be thought of as a numerical operation that is supposed to mimic the “focusing ability” of a model to the local, specific context as it reads through or generates text.
To learn more about word embeddings and the attention mechanism you might want to check out our dedicated YouTube videos: A Complete Overview of Word Embeddings and Transformers for beginners.
Transformer-based language models employ an encoder-decoder architecture to process and generate text. The encoder is responsible for converting the input text into a continuous representation, usually by processing the word embeddings and incorporating the attention mechanism. The decoder, on the other hand, takes this continuous representation and transforms it to some output text, again using the attention mechanism to selectively focus on relevant portions of the input. Essentially, the idea is the following:
- The encoder takes in text and encodes it into a numerical, high-dimensional, geometrically and statistically meaningful representation.
- The decoder takes in such a representation and decodes it back into text.

Depending on the task, a language model may use only the encoder part, or only the decoder part, or both. The quintessential examples for this distinction are:
- The BERT model, which stands for Bidirectional Encoder Representations from Transformers. It only uses the encoder part of a Transformer, as the name suggests, and it is best at performing any sort of prediction or classification task to a given input text.
- The GPT model, which stands for Generative Pre-trained Transformer. It is decoder-only, and, as its name suggests, is best suitable for tasks that involve generation of novel text.
For a variety of tasks, having both an encoder and decoder can be useful. In most machine translation models, for example, the encoder processes the source language text, while the decoder is responsible for generating the translated text in the target language.
A Matter of Size
You have a Transformer. Now, make it bigger.
The Race for the Largest Language Model
In recent years, the development of LLMs has been characterized by a dramatic increase in size, as measured by the number of parameters. This trend began with models like the original GPT and ELMo, which had millions of parameters, and progressed to models like BERT and GPT-2, with hundreds of millions of parameters. Some of the latest largest models like Megatron-Turing NLG and Google’s PaLM have already surpassed 500 billion parameters.
To put it differently, this means that in the span of the last 4 years only, the size of LLMs has repeatedly doubled every 3.5 months on average.

How much would it actually cost to train a Large Language Model? It is hard to give a very precise answer, due to the high number of variables involved in the process. However, informed estimates are in the range of 10 to 20 million US dollars only for the pre-training of a model like PaLM using customer cloud services. Of course, this figure is only representative for the cost of the final model pre-training and excludes all the costly engineering, research, and testing involved behind these complex systems.
When training a model, its size is only one side of the picture. The size of the dataset the model will be trained against is obviously a crucial aspect for the final outcome.
But, how to determine how much data one needs to train an LLM?
Scaling Laws: A New Perspective
Double the parameters, double the dataset. Et voilà !
Previous prevailing heuristics have long been claiming that increasing the size of a model was the most effective way to improve its performance, while scaling the training datasets was less important. However, more recent research has radically reshaped this perspective, revealing that many of the current LLMs are, in fact, significantly undertrained with respect to the amount of data seen during pre-training.

This fundamental shift has led to the formation of a new set of guiding heuristics, emphasizing the importance of training large models with more extensive datasets. In practice, in order to fully train the next massive LLM following these new principles one would need an immense amount of data, corresponding to a significant fraction, if not all of the text data available on the entire internet today.
The implications of this new perspective are profound. On the one hand, the total amount of training data actually available might turn out to be the true fundamental bottleneck for these AI systems.
On the other hand, even an ideal model that perfectly replicates the whole internet knowledge represents by no means the “ultimate LLM.” Concrete risks and safety concerns exist, associated with the fast increasing interaction with such models in the daily lives of many people.
Before discussing these issues, it is essential to first retrace how the mere process of scaling has been revolutionizing our own understanding of the potential cognitive abilities of future LLMs.
The Unexpected Effects of Scaling Up Language Models
Scaling language models yields more than expected.
With scaling, the performance of LLMs has (predictably) shown consistent improvements across a number of quantitative metrics that are supposed to measure to which extent an LM is able to do what it was primarily designed for: calculate probability distributions over words. An example of such metrics is perplexity, a measure of fluency of generated text.
We have seen, however, how the process of scaling language models requires training them on enormous quantities of data, often sourced from the extensive troves of text available online. LLMs thus get to be "fed" with substantial portions of the web, spanning a vast array of information. Being exposed to such a diverse range of linguistic patterns and structures during training, LLMs progressively learn to emulate and reproduce these patterns with high fidelity.
As a byproduct, this process has appeared to give rise to fascinating qualitative behaviors. Empirical studies have found that, as LLMs are scaled, they are able to suddenly "unlock" new capabilities that seem to emerge in a discontinuous manner, in contrast to the more predictable linear improvement of quantitative metrics.

These emergent abilities encompass a wide range of tasks, such as translation between different languages, the ability to write programming code, and many others. Remarkably, LLMs acquire these skills through the mere observation of recurring patterns in natural language during the training process, that is, without explicit task-specific supervision.
Emergence is a very intriguing phenomenon that is, in fact, not restricted to LLMs, but has been observed in other scientific contexts. The interested reader may also take a look at a more general discussion in our recent blog post: Emergent Abilities of Large Language Models.
The Prompting Effect & Instruction Tuning
A striking fact is that these emergent abilities can sometimes be accessed simply by prompting a language model with the appropriate query expressed in natural language.
For instance, an LLM can be prompted with a passage followed by a request for summarization, and it will generate a concise summary of the given text.
However, in many instances, pre-trained LLMs actually fail to properly follow these prompts. This may occur due to the model replicating patterns observed in its training data. For example, if prompted with a question like, What is the capital of France?, the model might respond with another question, such as What is the capital of Italy?, because it has perhaps picked up this pattern from some lists of questions, or quizzes on the internet.
To address this issue, researchers have developed a simple strategy called Instruction Tuning. This technique involves training the LLM on a small dataset of examples that consists of prompts or instructions followed by the correct actions.
By fine-tuning the model on these examples (usually very few per task), it learns to better understand and follow instructions given in natural language.
The outstanding advantage of this process lies in the generalization capability of an instruction-tuned LLM, which will often enable it to then successfully follow instructions on a much wider variety of tasks than those seen in this small dataset.
The rise of this prompting effect has, indeed, superseded the need of extensive fine-tuning smaller, specialized models for some specific tasks. Some of these tasks can in fact be performed more effectively by large, scaled models that have acquired these abilities by mere exposure to diverse data, and subsequently unlocked them via a relatively simple instruction tuning.

From Giant Stochastic Parrots to Preference-Tuned Models
The phenomenon of emergent abilities in LLMs, although quite recent and still not fully understood by researchers, is also not a completely obscure one.
Even though there is no prediction on exactly which new cognitive capabilities further scaled LLM may acquire in the future, the general pattern that allows this to happen is fairly clear. Let’s consider the example of Question-Answering.
Within this massive language dataset, the internet of text, there exist numerous instances of questions followed by answers. These question-answer pairs occur in diverse contexts, such as forums, articles, or educational resources, and cover a multitude of topics, from everyday trivia to specialized technical knowledge.
Ultimately, a statistically significant number of these answers is in fact correct, and this is reflected in the ability of an LLM to carry out a form of information retrieval from web knowledge, by giving reasonably correct answers to common sense questions on disparate topics when requested to do so.
Unfortunately, the internet is also filled with (a statistically significant amount of) false facts and wrong answers to common sense questions. Due to the sheer volume of this data, it is virtually impossible for the researchers to regulate the content LLMs are exposed to during training.
As a matter of fact, LLMs may occasionally exhibit various types of undesirable behavior, such as reproducing harmful or biased content, or generating so-called hallucinations by fabricating nonexistent or false facts.
When such models are proposed as general purpose conversational chatbots (like ChatGPT), it becomes a lot more difficult to identify all the possible threats that arise from a mass use of these systems, since it is almost impossible to predict a priori all the possible scenarios.
Societal Dangers of General Purpose LLMs
As with any technology, the potential for harm exists if it is not used wisely.
The dangers of Large Language Models (LLMs) are not limited to incorrect answers or fabricated information. Their risks are multifaceted and ultimately depend on their specific use case.
With the increasing popularity of general-purpose chatbots like ChatGPT, millions of users now have access to exceptionally powerful LLMs. It is crucial to ensure that these models are not exploited for malicious purposes and that they are designed to decline requests that could lead to real harm.
Some examples of how such real harm could manifest include:
- LLMs with coding abilities could be employed to create sophisticated malware with unprecedented ease.
- They also pose a new threat related to mass propaganda actions, where coordinated networks of chatbots could theoretically be used on social media platforms at scale to distort public discourse.
- Privacy risks arise when LLMs inadvertently replicate personally identifiable information from data used during training.
- Psychological harm may result from users turning to chatbots for social interaction and emotional support, only to be met with unanticipated and potentially harmful responses.
These are only a few from a much wider range of AI safety concerns, which come in different flavors. The current general idea is that general purpose LLMs should be somehow designed to be aiming at three distinct principles:
- Helpfulness: The ability of an LLM to follow instructions, perform tasks, provide answers, and ask relevant questions to clarify user intent when needed.
- Truthfulness: The capacity for an LLM to provide factual, accurate information and to acknowledge its own uncertainties and limitations.
- Harmlessness: The importance of avoiding toxic, biased, or offensive responses and refusing to assist in dangerous activities.
An LLM is considered aligned if it can successfully adhere to these general guidelines. However, the concept of alignment varies among experts. For instance, the prominent AI alignment researcher Paul Christiano defines alignment more narrowly, focusing on the extent to which an AI's actions align with its interpretation of the user's intentions, i.e. a form of intent alignment.
The diverse nature of these problems may necessitate different strategies and approaches for LLMs to adequately respond to various requests. Eventually, it seems undeniable that provably effective mechanisms must be put in place to prevent the misuse of LLM technology.
In light of all this, it might seem surprising that one particular technique, Reinforcement Learning from Human Feedback (RLHF) has emerged as a single methodology that can, in principle, address all these issues simultaneously, making significant strides in aligning LLMs with human values.
RLHF as Value Learning
Can a machine learn human values?
Fundamentally, RLHF is based on a straightforward premise. Imagine having two language models: a baseline (unaligned) model and a secondary preference model. The preference model's role is to determine which action a human would prefer within a given list of possibilities (e.g., two different responses from the baseline model to a user's request). This model could assign a numerical score to each action, effectively ranking them according to human preferences. In technical terms, this is known as a reward model.
Utilizing the reward model, the baseline model can be refined iteratively, altering its internal text distribution to prioritize sequences favored by humans (as indicated by the reward model). In some sense, the reward model serves as a means to introduce a "human preference bias” into the baseline model.

The core idea of RLHF revolves around training a reward model. Multiple approaches exist, but RLHF specifically leverages human feedback to generate a human preferences dataset. This dataset is then used to learn the reward function that represents the desired outcome for a particular task.
Concretely, human feedback can manifest in several ways, such as:
- Preference orderings: Humans assign a preference ordering to different outputs of the baseline model.
- Demonstrations: Instead of scoring the model’s outputs, humans are actually performing the full task of writing the preferred answers to a set of prompts, or requests.
- Corrections: This amounts to editing a model’s output to directly correct the undesirable behaviors.
- Natural language input: Instead of directly correcting a model’s output, humans are asked to describe a critique of these outputs in natural language.
The optimal method depends on the specific task (or set of “human values”) to be optimized. Fine-tuning a model via supervised learning based on high-quality demonstrations is theoretically expected to yield the best results. In practice, however, collecting demonstrations is significantly more time-consuming and expensive than other feedback methods, heavily limiting the scalability of this approach.
Once the reward model has been established, how is it used to train the baseline model?
This is where Reinforcement Learning (RL) comes into play. RL is a machine learning paradigm that focuses on enabling intelligent agents (like an LLM) to learn an optimal policy guiding their actions to maximize a reward.
In this context, the baseline model is the agent, and its actions are responses to user input. The RL framework employs the reward model to effectively develop a human values policy that the language model will use to generate its responses.
A prominent example of a large language model utilizing RLHF is ChatGPT, which integrates unsupervised pre-training, supervised fine-tuning, instruction tuning, and RLHF to achieve remarkable conversational abilities. By incorporating RLHF, ChatGPT has demonstrated how it is possible to leverage human feedback to produce more engaging, context-sensitive, and safety-aligned responses, setting the stage for the next generation of advanced conversational AI.
Let’s take a closer look at how RLHF has been used for ChatGPT.
How RLHF is used to train ChatGPT
OpenAI has applied the general methodology of RLHF to fine-tune ChatGPT through a three-step process.
The initial step involves collecting human demonstrations using a group of about 40 human annotators for a pre-selected set of prompts. The prompts are sourced from two different origins: some are created by annotators or developers, while others are sampled from OpenAI's API requests.
These demonstrations can be thought of as the “ideal answers”, or responses to these prompts, and together constitute a training dataset. This dataset is then used to fine-tune a pre-trained model in a supervised manner, yielding the Supervised Fine-Tuned (SFT) model.

As mentioned earlier, this approach has scalability limitations, resulting in a relatively small dataset (approximately 15k examples).
The second step revolves around preference orderings. Labelers (or annotators) are tasked with voting on a number of SFT model outputs, thereby creating a new dataset composed of comparison data. The reward model is trained on this dataset.
In practice, a list of prompts is chosen, and the SFT model generates multiple outputs (between 4 and 9) for each prompt. Annotators rank these outputs from best to worst, forming a new labeled dataset with rankings serving as labels.
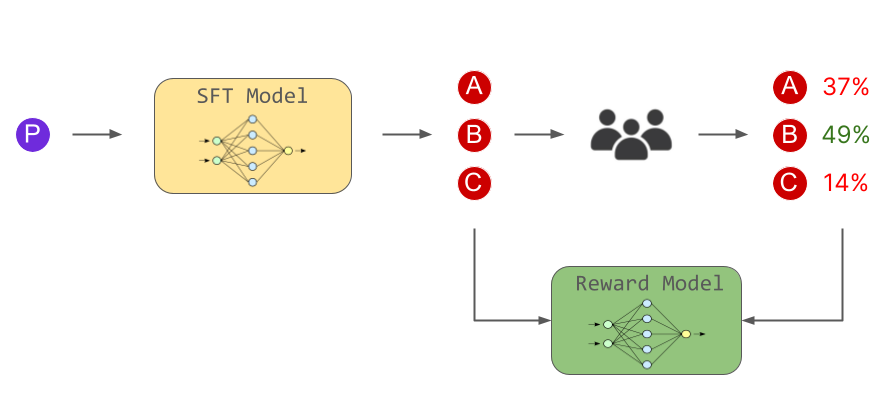
Although the exact details remain undisclosed by OpenAI, the dataset's size may be roughly ten times larger than the curated dataset used for the SFT model.
Finally, the third step involves applying Reinforcement Learning to teach the SFT model the human preference policy through the reward model, essentially as described in the previous section. The SFT model is fine-tuned via the reward model. The outcome is the so-called policy model.
The specific optimization algorithm employed to train the policy model is Proximal Policy Optimization (PPO), which was developed by OpenAI.
A key feature of PPO is the fact that it employs a trust region optimization method to train the policy, constraining policy changes within a certain range of the previous policy to ensure stability. This is to ensure that the policy optimization step does not end up over-optimizing the reward model: without such constraint, the policy model may start to prefer actions which, despite a high reward score, are downgrading the performance of the actual task.
While the collection of demonstrations occurs only once, the second (reward model) and third steps (policy model) are iterated multiple times. More comparison data is gathered on the current best policy model, which is then used to train a new reward model and, subsequently, a new policy.
What RLHF actually does to an LLM
Reinforcement Learning from Human Feedback represents a significant advancement in the field of language models, providing a more user-friendly interface for harnessing their vast capabilities.
But what is the actual effect of RLHF fine-tuning on a “pure” base LLM?
One way to think about it is the following. The base model, trained to approximate the distribution of internet text, possesses a sort of chaotic nature, as it has modeled an entire internet's worth of text, complete with both extremely valuable as well as undesirable content.
Let’s suppose we have an ideal base model which, at such a stage, is able to perfectly replicate this highly multimodal distribution of internet text. That is, it has successfully performed a perfect distribution matching task. Still, at inference, such an ideal model might exhibit a form of instability (with respect to an input prompt) in the way it chooses amongst the millions of modes in the distribution, which altogether represent the whole cacophony of different tones, sources, and voices that exist in its massive training data.

At this point, predicting the quality of the model's output based on an input prompt can be challenging, as the model could generate vastly different responses depending on the source it decides to emulate.
Take, for example, a scenario where a user submits a query about a prominent political figure. The model could produce an output that mimics the tone of a neutral, informative Wikipedia article (it chooses the encyclopedic mode in the distribution, so to speak). Conversely, depending on the phrasing of the question, the model might be swayed to adopt a more extreme perspective inspired by radical viewpoints encountered on the internet.
It is not at all unrealistic to imagine situations in which the base model predicts only a slight difference in its numerical estimation for preferring one between two different modes in the distribution. Which mode to choose? Leaving this entirely up to the model’s stochastic decision making nature may not be the most desirable solution.
RLHF addresses this issue by fine-tuning the model based on human preference data, this way offering a more controlled and reliable user experience.
But does this come at a cost?
A Tradeoff between Safety and Creativity
As we have previously discussed, by treating the language model as a reinforcement learning policy during the fine-tuning phase, RLHF introduces biases into the distribution.
Operationally, we can interpret this effect as the introduction of a mode-seeking behavior which guides the model through the distribution and leads to outputs with higher rewards (as modeled by learned human preferences), effectively narrowing the potential range of generated content.

This bias is, of course, a direct reflection of the preferences and values of the actual selection of people that have contributed to the preference dataset used to train the reward model. In the case of ChatGPT, for example, this bias is heavily geared towards helpful, truthful and safe answers, or at least towards the annotators’ interpretation of these values.
What is it that gets “lost” by the model via this process?
While RLHF improves the consistency of the model's answers, it inevitably does so at the cost of diversity in its generation abilities. This trade-off could be viewed as both a benefit and a limitation, depending on the intended use case.
For instance, in LLM applications such as search engines, where accurate and reliable responses are paramount, RLHF is an ideal solution. On the other hand, when using language models for creative purposes, such as generating novel ideas or assisting in writing, the reduction in output diversity may hinder the exploration of new and intriguing concepts.
Final Words
In this self-contained exploration of Large Language Models and the crucial role of RLHF in aligning them with human values, we have touched on a myriad of concepts that lie at the heart of this fascinating field.
Although we have delved into the essence of LLMs, RLHF, and the main ideas behind them, there is a wealth of interconnected topics waiting to be explored. We will be exploring these in future blog posts.
Enjoyed this article?
Feel free to check out some of our other recent articles to learn about:
- Graph Neural Networks in 2023
- Recent developments in Generative AI for Audio
- How RLHF Preference Model Tuning Works (And How Things May Go Wrong)
You can also follow us on Twitter, where we regularly release fresh content on these subjects and many other exciting aspects of AI.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.