Convert Speech to Text in Python in 5 Minutes
Learn how to perform Automatic Speech Recognition in 5 minutes using Python and the AssemblyAI Speech-to-Text API with this simple tutorial.


Learn how to perform Automatic Speech Recognition in 5 minutes using Python and the AssemblyAI Speech-to-Text API with this simple tutorial, a key skill in an era where a recent report finds that conversation intelligence has reached a tipping point.
In this tutorial, we'll learn how to perform Speech-to-Text in 5 minutes using Python and AssemblyAI's Speech-to-Text API.
We'll use AssemblyAI's Python SDK, which provides high-level functions for creating and working with transcripts. Let's dive in!
Getting Started
To follow along with this tutorial, you'll need to already have Python 3 installed on your system.
Install the SDK
To begin, we'll install the AssemblyAI Python SDK with the following terminal command:
pip install assemblyai
Get a speech-to-text API key
To perform the transcription, we will be using AssemblyAI's Speech-to-Text API. AssemblyAI offers $50 in free credits to get you started. If you don't yet have an account, create one here. Log in to your account to see the Dashboard, which provides an overview of your usage and settings. All we'll need right now is your API key. Click the key under the Your API key section on the Dashboard to copy its value.
This API key is like a fingerprint associated to your account and lets the API know that you have permission to use it.
Important Note
Never share your API key with anyone or upload it to GitHub. Your key is uniquely associated with your account and should be kept secret.
Store your API key
We want to avoid hard coding the API key for both security and convenience reasons. Instead, we'll store the API key as an environment variable.
Back in the terminal, execute one of the following commands, depending on your operating system, replacing <YOUR_API_KEY> with the value copied previously from the AssemblyAI Dashboard:
Windows
set ASSEMBLYAI_API_KEY=<YOUR_API_KEY>
MacOS/Linux
export ASSEMBLYAI_API_KEY=<YOUR_API_KEY>
This variable only exists within the scope of the terminal process, so it will be lost upon closing the terminal. To persist this variable, set a permanent user environment variable.
Alternative: using dotenv
You can alternatively set your API key in the Python script itself using aai.settings.api_key = "YOUR_API_KEY". Note that you should not hard code this value if you use this method. Instead, store your API key in a .env file and use a package like python-dotenv to import it into the script. Do not check the .env file into source control.
Python Speech Recognition Options Comparison
Python developers have several speech recognition options:
- SpeechRecognition library: Good for prototypes but inconsistent accuracy in production
- OpenAI Whisper: Powerful open-source model requiring hardware management and scaling complexity
- AssemblyAI API: Production-ready Voice AI with advanced speech understanding models and simple integration, a key factor for the 40% of tech leaders who prioritize ease of use when choosing an AI vendor, according to a survey of leaders.
How to Transcribe an Audio File with Python
Now we can get started transcribing an audio file, which can be stored either locally or remotely.
Transcribe the audio file
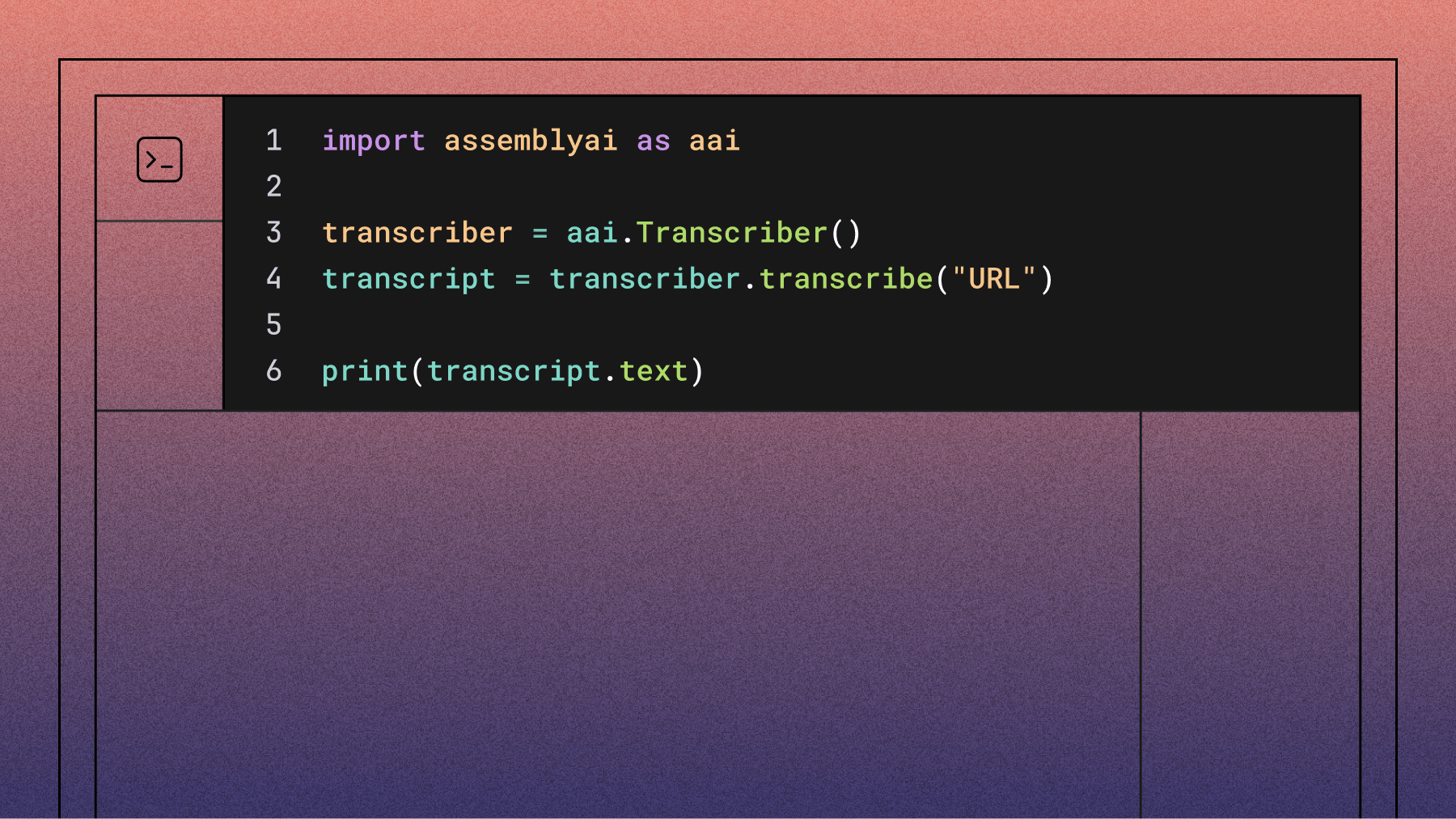
Create a main.py file and paste the below lines of code in:
import assemblyai as aai
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("https://storage.googleapis.com/aai-web-samples/gettysburg.wav")
print(transcript.text)
The code imports AssemblyAI, creates a Transcriber object, and calls transcribe() with your audio file URL. The method returns a Transcript object containing the transcribed text.
Run the file in the terminal with python main.py (or python3) to see the result printed to the console after a few moments. Larger audio files will take longer to process.
Four score and seven years ago our fathers brought forth on this continent a new nation conceived in liberty and dedicated to the proposition that all men are created equal.
HTTPS Note
That's all it takes to transcribe a file using AssemblyAI's Speech-to-Text API. To learn more about what you can do with the AssemblyAI API, like summarize files, analyze sentiment, or apply LLMs to transcripts, continue below. Otherwise, feel free to jump down to the Next Steps section.
Handle Errors and Optimize Performance
Production code needs robust error handling. In fact, a market survey found that over 30% of tech leaders cite security and data privacy as significant challenges when building with speech recognition. While the SDK handles retries on network issues, you should check the status of the transcription job to handle any processing errors:
- Invalid API keys
- Network connectivity issues
- File format errors
- Service timeouts
import assemblyai as aai
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("https://storage.googleapis.com/aai-web-samples/gettysburg.wav")
if transcript.status == aai.TranscriptStatus.error:
print(f"Transcription failed: {transcript.error}")
else:
print(transcript.text)
For performance, our API processes audio asynchronously, meaning you can submit large files without blocking your application. The SDK waits for the transcription to complete before returning the result, making it simple to work with files of any size.
Real-Time Speech Recognition in Python
Many applications, like voice-controlled devices or live captioning, require real-time speech-to-text to deliver the low-latency results—often within milliseconds—that are crucial for immediate feedback. Our Python SDK makes it easy to build streaming transcription capabilities into your application.
You can use the StreamingClient to process audio from a microphone or any other live audio stream. The following example shows how to set up a basic real-time transcriber that prints text as it's spoken.
import assemblyai as aai
from assemblyai.streaming.v3 import (
StreamingClient,
StreamingEvents,
TurnEvent,
StreamingError,
)
# Define event handlers
def on_turn(client: aai.streaming.v3.StreamingClient, event: TurnEvent):
# event.transcript contains the finalized words of the turn
if not event.transcript:
return
# Print partial or final transcripts
if event.end_of_turn:
print(event.transcript, end="\n")
else:
print(event.transcript, end="\r")
def on_error(client: aai.streaming.v3.StreamingClient, error: StreamingError):
print("An error occurred:", error)
# Create a StreamingClient
# The API key is read from the ASSEMBLYAI_API_KEY environment variable
client = StreamingClient()
# Attach event handlers
client.on(StreamingEvents.Turn, on_turn)
client.on(StreamingEvents.Error, on_error)
# Connect to the streaming service
client.connect()
# Stream audio from the microphone
try:
print("Starting to stream from microphone... Press Ctrl+C to stop.")
client.stream(aai.extras.MicrophoneStream())
finally:
client.disconnect()
Analyzing Transcripts with the LLM Gateway
Once you have a transcript, you can use AssemblyAI's LLM Gateway to apply powerful language models for analysis. For example, you can create a custom summary of an audio or video file. This is done by sending the transcript text to the LLM Gateway with a specific prompt.
Note: This example uses the requests library. You may need to install it with pip install requests.
import assemblyai as aai
import requests
# Set your API key
aai.settings.api_key = "YOUR_API_KEY"
# 1. Transcribe the audio file
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("https://storage.googleapis.com/aai-web-samples/meeting.mp4")
if transcript.status != aai.TranscriptStatus.completed:
print(f"Transcription failed: {transcript.error}")
else:
# 2. Prepare the prompt for the LLM Gateway
prompt = """
Summarize the following transcript as a list of bullet points.
Provide the summary in the context of a GitLab meeting to discuss logistics.
"""
# 3. Call the LLM Gateway
response = requests.post(
"https://llm-gateway.assemblyai.com/v1/chat/completions",
headers={"authorization": aai.settings.api_key},
json={
"model": "claude-3-5-haiku-20241022",
"messages": [
{
"role": "user",
"content": f"{prompt}\n\nTranscript:\n{transcript.text}"
}
],
}
)
result = response.json()
if "error" in result:
print(f"LLM Gateway error: {result['error']}")
else:
print(result['choices'][0]['message']['content'])
You can use LLM Gateway for a wide variety of tasks, like asking questions about the transcript or extracting structured data, by changing the prompt. Note that using the LLM Gateway requires a paid account with billing set up.
To learn more about what the LLM Gateway can do and how to use it, you can check out our documentation.
Analyzing Files with Speech Understanding Models
As industry research suggests, winning teams view voice data as more than just a transcript. Beyond LLM Gateway, the AssemblyAI API also offers a suite of Speech Understanding models that can extract useful information from your audio and video files.
For example, the Auto Chapters model will automatically segment the transcript into semantically-distinct chapters, returning the starting and stopping timestamps for each chapter along with a summary of each chapter. The Sentiment Analysis model will return the sentiment for each sentence in the audio as positive, negative, or neutral.
To use these models, all we have to do is "turn them on" in a TranscriptionConfig object which we can pass into our Transcriber:
import assemblyai as aai
config = aai.TranscriptionConfig(
sentiment_analysis=True,
auto_chapters=True
)
transcriber = aai.Transcriber(config=config)
transcript = transcriber.transcribe("https://storage.googleapis.com/aai-web-samples/gettysburg.wav")
print(transcript.chapters)
print(transcript.sentiment_analysis)
To see the full suite of models you can use through the AssemblyAI API, check out our website or docs, or use our Playground to try them directly in a no-code way.
Next Steps with Voice AI in Python
You can now integrate speech-to-text into Python applications using AssemblyAI's API. Try our API for free to build more advanced features like call summaries, meeting analysis, or PII redaction.
Frequently Asked Questions about Python Speech Recognition
How do I debug transcription accuracy issues?
Ensure clean audio with minimal background noise and use the keyterms_prompt feature for domain-specific terms.
What audio formats does AssemblyAI support?
Our API supports a wide range of common audio and video formats, so you don't have to worry about converting files to a specific format like WAV before processing them. The Python SDK can handle local files or publicly accessible URLs directly.
How do I optimize performance when processing large audio files?
AssemblyAI processes files asynchronously in the background, allowing concurrent processing without blocking your application.
Can I use AssemblyAI for real-time speech recognition in Python?
Yes, the AssemblyAI Python SDK includes a RealtimeTranscriber that enables you to process live audio streams from microphones or other sources. This is perfect for applications like live captioning, voice assistants, or real-time translation services.
How do I implement proper error handling and retry logic?
Wrap API calls in try-except blocks to catch APIError exceptions and implement exponential backoff for critical applications.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts