Using multichannel and speaker diarization
Learn how multichannel transcription and speaker diarization work, what their outputs look like, when to use each feature, and how you can implement them.


Separating and identifying multiple speakers in audio recordings is essential for creating accurate, organized transcripts, and it's a capability gaining significant attention; in fact, an industry survey found that 50% of respondents are excited about the future of speaker recognition and voice embeddings. Two techniques that make this possible are multichannel transcription and speaker diarization.
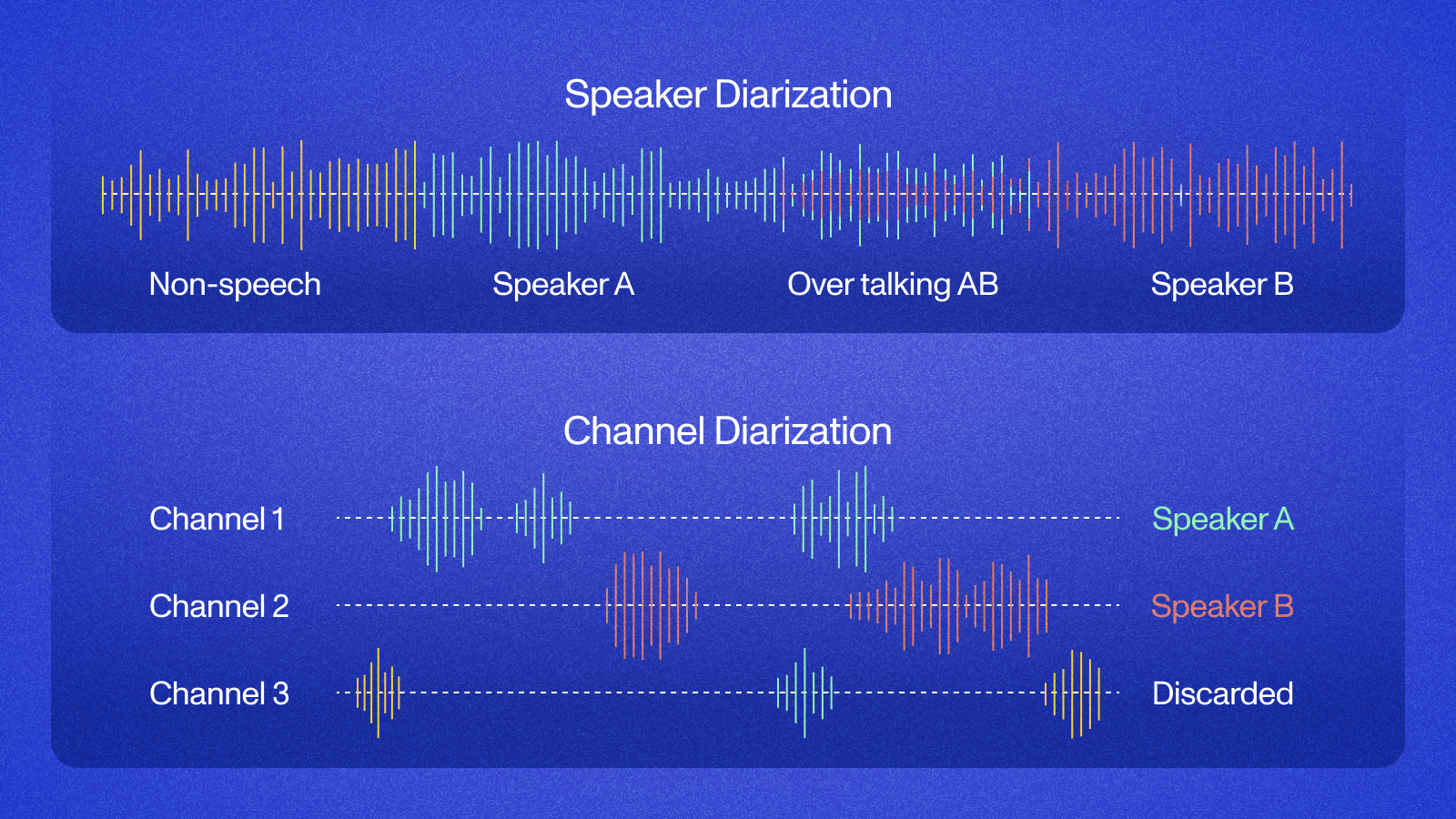
Multichannel transcription, also known as channel diarization, processes audio with separate channels for each speaker, making it easier to isolate individual contributions. Speaker diarization distinguishes speakers in single-channel recordings. Both methods help create structured transcripts that are easy to analyze and use.
In this article, we'll explain how multichannel transcription and speaker diarization work, what their outputs look like, and how you can implement them using AssemblyAI's Voice AI models.
Understanding multichannel transcription
Multichannel transcription separates speakers by processing distinct audio channels—each channel contains one speaker's audio. This eliminates speaker overlap and delivers higher accuracy than single-channel processing.
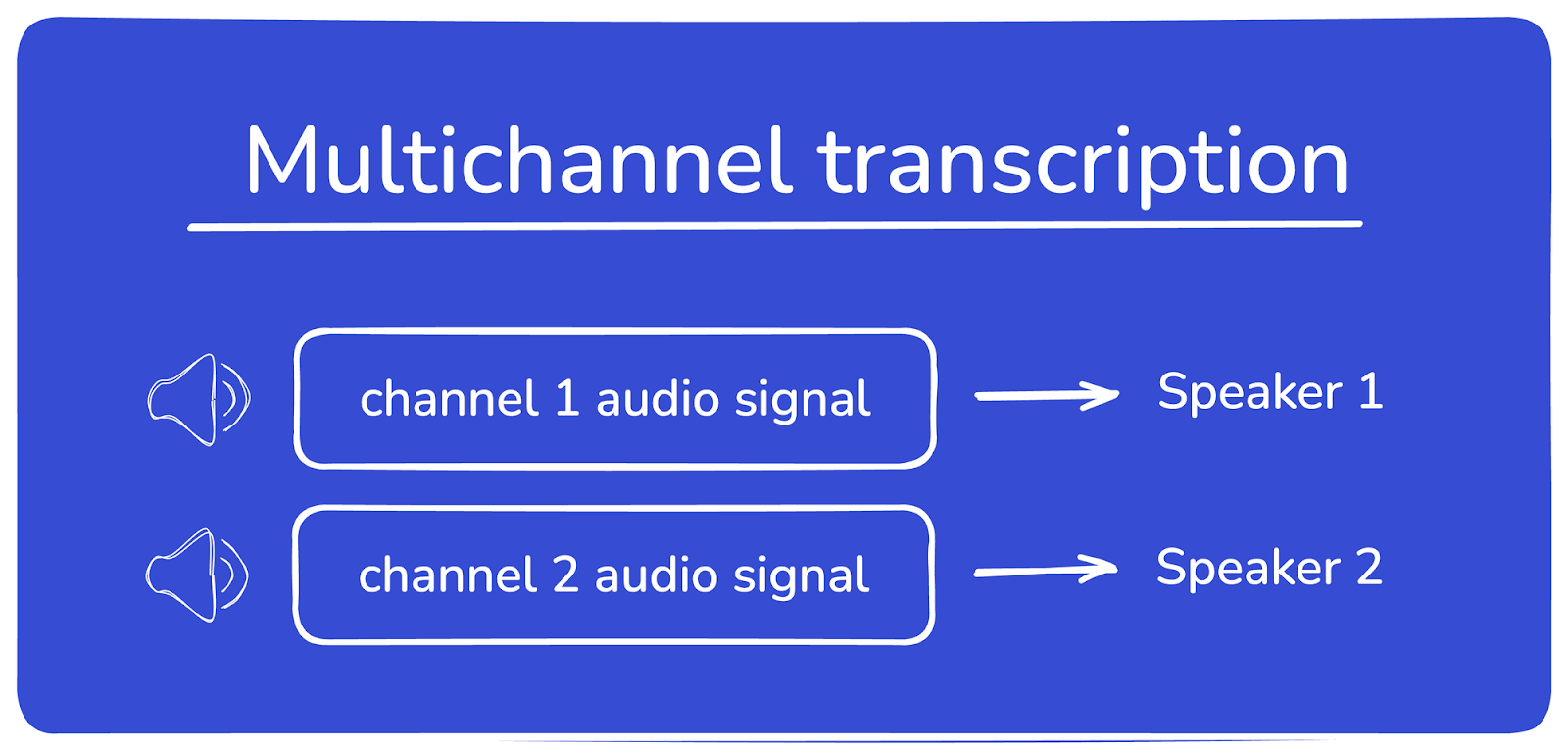
Common multichannel setups include:
- Conference calls: Each participant's microphone records to a separate channel
- Stereo recordings: Interviewer on left channel, interviewee on right channel
- Podcast recordings: Hosts and guests on individual channels
- Customer service: Agent and customer on separate channels
Multichannel transcription delivers higher accuracy because speakers are pre-separated at the recording level.
Note: Multichannel audio increases transcription time by approximately 25%.
Understanding speaker diarization
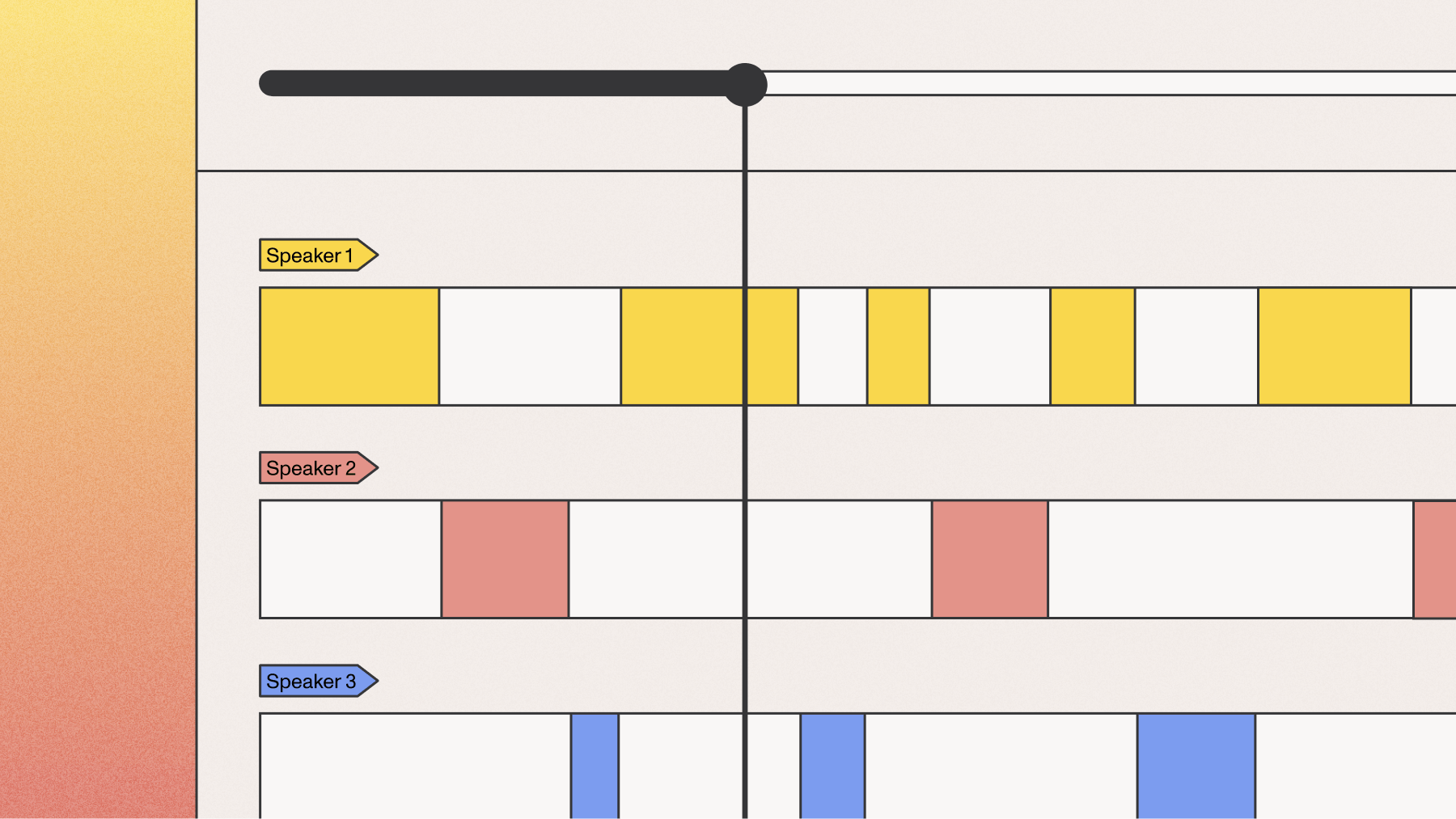
Speaker diarization identifies and distinguishes speakers within single-channel audio recordings. It answers the question: "Who spoke when?" by segmenting the audio into speaker-specific portions.
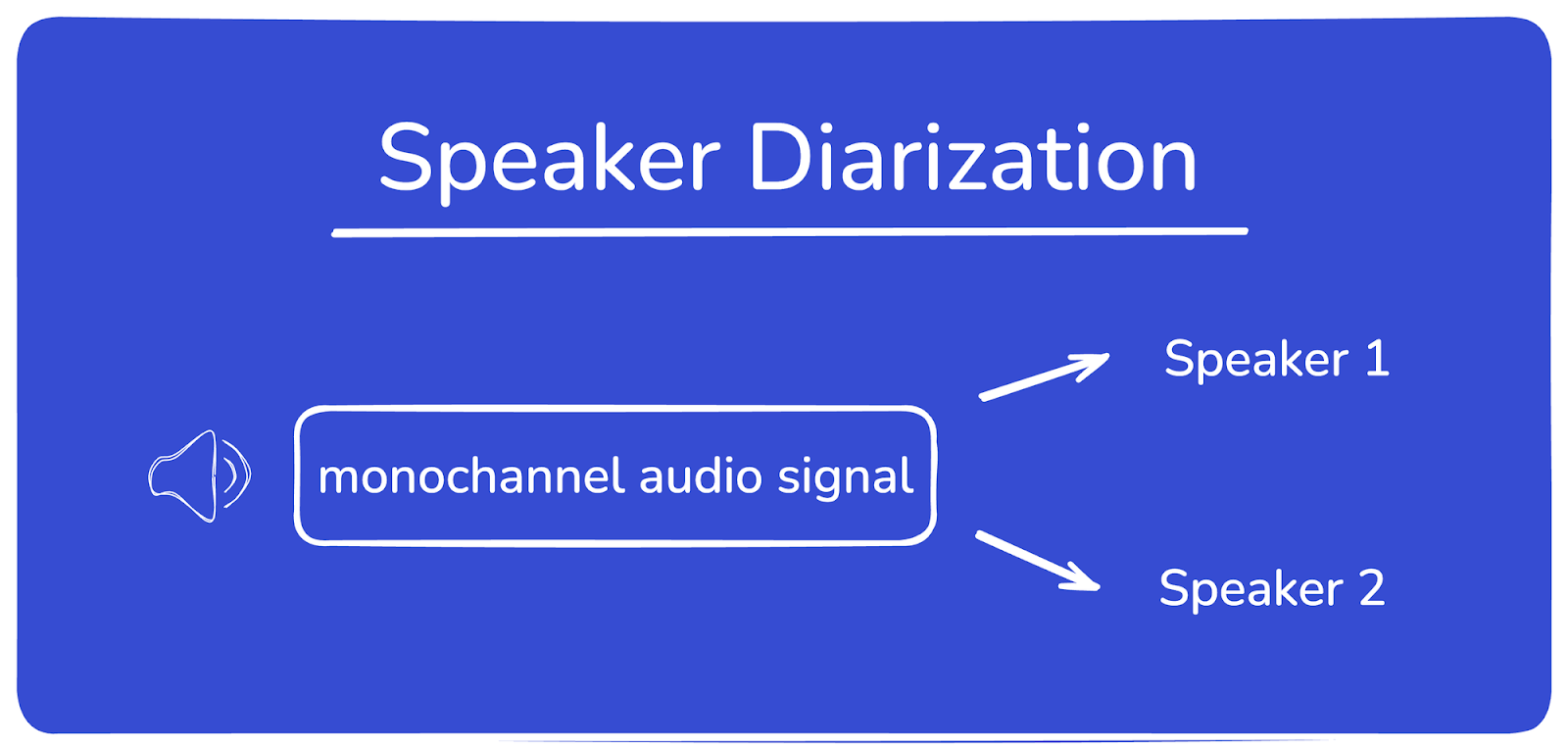
Speaker diarization works on single-channel audio by analyzing voice characteristics like pitch, tone, and cadence. It identifies "who spoke when" even with overlapping speech.
This technique is especially valuable in scenarios like recorded meetings, interviews, and panel discussions where speakers share the same recording track, with documented applications in fields ranging from market research and healthcare to call centers and legal depositions. For instance, a single-channel recording of a business meeting can be processed with diarization to label each participant's speech, providing a structured transcript that makes conversations easy to follow.
Important: Speaker Diarization and Multichannel transcription cannot be used together. Enabling both features will result in an error. Choose the method that best fits your audio recording setup.
By using speaker diarization, you can create clear and organized transcripts without the need for separate audio channels. This ensures accurate speaker attribution, improves usability, and allows for deeper insights into speaker-specific contributions in any audio recording.
Choosing between multichannel and speaker diarization
Deciding between Multichannel transcription and Speaker Diarization depends on the structure of your audio and your specific needs. Both approaches are effective for separating and identifying speakers, but they are suited to different scenarios.
When to use multichannel transcription
Multichannel transcription is ideal when your recording setup allows for distinct audio channels for each speaker or source. For example, conference calls, podcast recordings, or customer service calls often produce multichannel audio files. With each speaker recorded on a separate channel, transcription becomes straightforward, as there's no need to differentiate speakers within a single track. Multichannel transcription ensures clarity, reduces overlap issues, and is particularly useful when high accuracy is required.
When to use speaker diarization
Speaker diarization is the better choice for single-channel recordings where all speakers share the same audio track. This technique is commonly applied in scenarios like in-person interviews, panel discussions, or courtroom recordings. Diarization uses advanced algorithms to differentiate speakers, making it effective when you don't have the option to record each participant on their own channel.
Making the right choice
If your recording setup supports separate channels for each speaker, multichannel transcription is generally the more precise and efficient option.
However, if your audio is limited to a single channel or includes overlapping voices, speaker diarization is essential for creating structured and accurate transcripts.
Ultimately, the choice depends on the recording setup and the level of detail needed for the transcript.
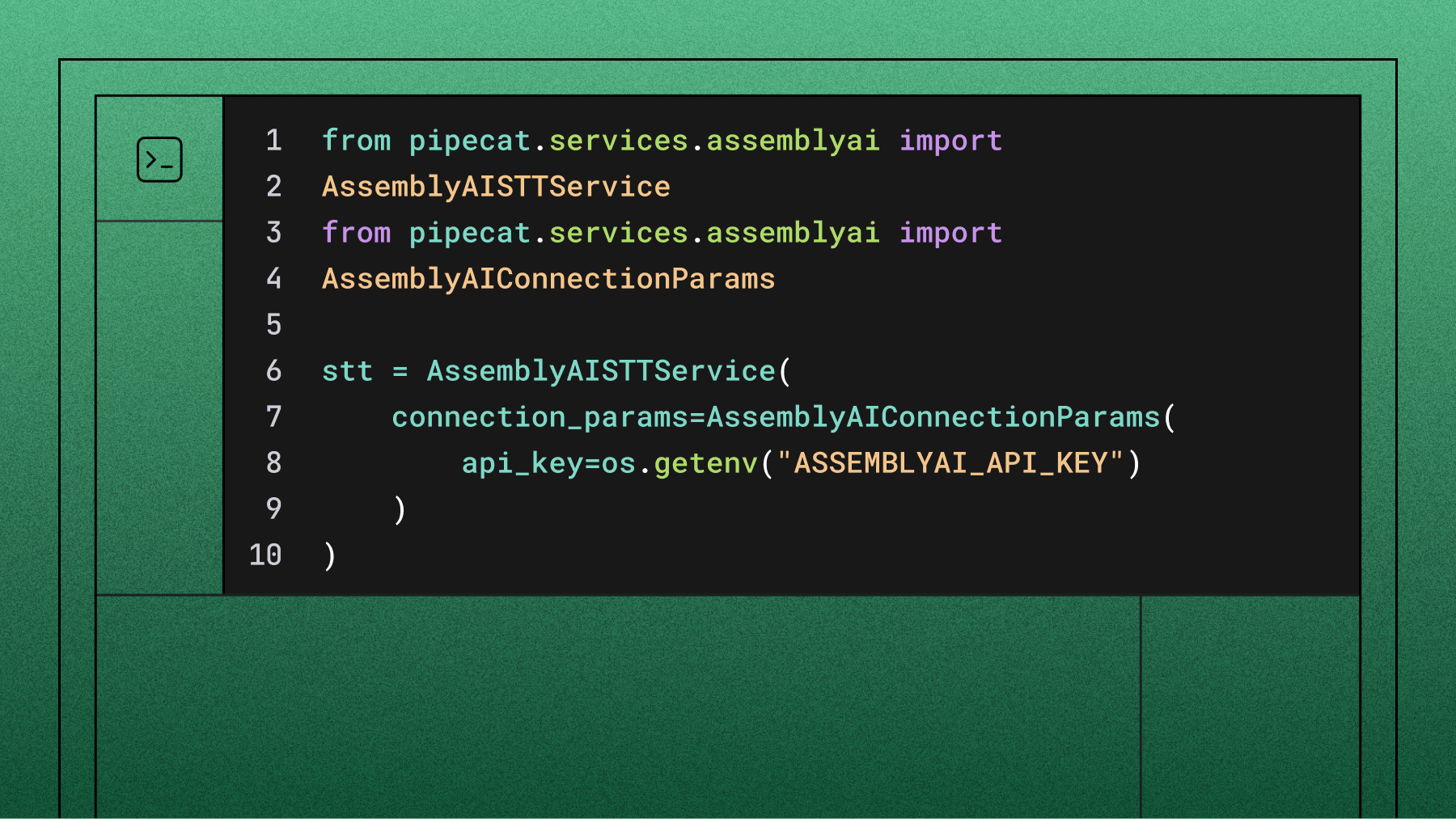
How to implement multichannel transcription with AssemblyAI
You can use the API or one of the AssemblyAI SDKs to implement multichannel transcription (see developer documentation).
Let's see how to use multichannel transcription with the AssemblyAI Python SDK:
import assemblyai as aai
audio_file = "./multichannel-example.mp3"
config = aai.TranscriptionConfig(multichannel=True)
transcript = aai.Transcriber().transcribe(audio_file, config)
print(f"Number of audio channels: {transcript.json_response['audio_channels']}")
for utt in transcript.utterances:
print(f"Speaker {utt.speaker}, Channel {utt.channel}: {utt.text}")
Set multichannel=True in your TranscriptionConfig and call transcribe():
The response includes speaker, channel, and text for each utterance.
Multichannel response
With AssemblyAI, you can transcribe each audio channel independently by configuring the multichannel parameter. See how to implement it in the previous section.
Here is an example JSON response for an audio file with two separate channels when multichannel transcription is enabled:
{
"multichannel": true,
"audio_channels": 2,
"utterances": [
{
"text": "Here is Laura talking on channel one.",
"speaker": "1",
"channel": "1",
"start": 1000,
"end": 4500,
"confidence": 0.98,
"words": [
{
"text": "Here",
"speaker": "1",
"channel": "1",
"start": 1000,
"end": 1350,
"confidence": 0.99
},
{
"text": "is",
"speaker": "1",
"channel": "1",
"start": 1400,
"end": 1550,
"confidence": 0.98
}
]
},
{
"text": "And here is Alex talking on channel two.",
"speaker": "2",
"channel": "2",
"start": 5000,
"end": 8200,
"confidence": 0.97,
"words": [
{
"text": "And",
"speaker": "2",
"channel": "2",
"start": 5000,
"end": 5250,
"confidence": 0.99
},
{
"text": "here",
"speaker": "2",
"channel": "2",
"start": 5300,
"end": 5600,
"confidence": 0.98
}
]
}
]
}
The response contains the multichannel field set to true, and the audio_channels field with the number of different channels.
The important part is in the utterances field. This field contains an array of individual speech segments, each containing the details of one continuous utterance from a speaker. For each utterance, a unique identifier for the speaker (e.g., 1, 2) and the channel number are provided.
Additionally, the words field is provided, containing an array of information about each word, again with speaker and channel information.
Related posts