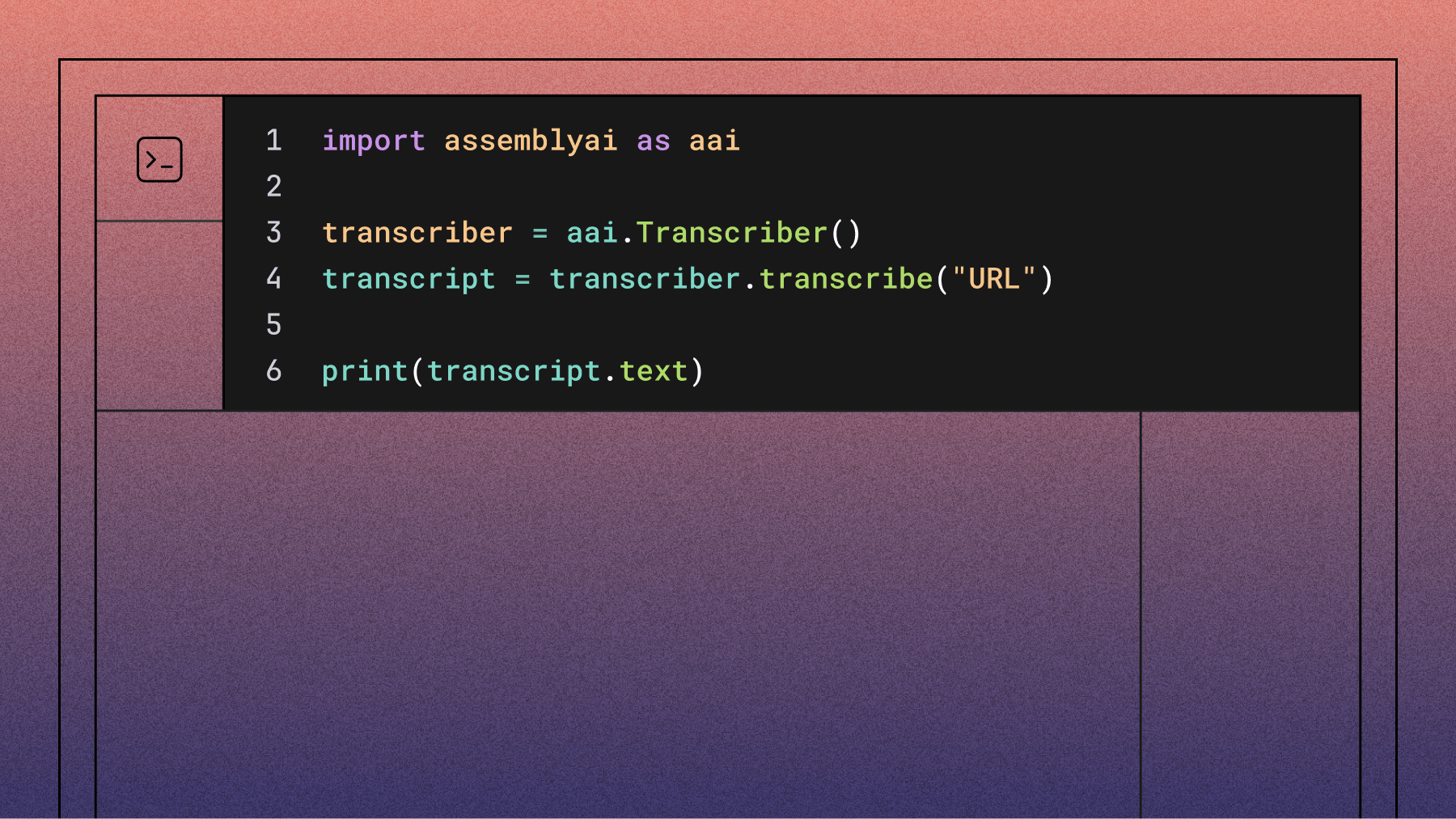
How to build a voice agent for IT helpdesk and technical support
A step-by-step tutorial for building an IT support voice agent that routes, looks up docs, and handles ITSM tickets.



Tier-1 IT support is the most universal use case in the enterprise, and it’s the one people still reach by phone. The reason is almost funny: the moment someone genuinely needs IT, the channels you’d rather they use are often the ones that are broken. You can’t open the self-service portal when you’re locked out of SSO. You can’t chat the helpdesk when the VPN is down and the chat tool is behind it. So the phone rings — “I can’t log in,” “my laptop won’t connect to the network,” “what’s the status on my ticket” — and a human reads from the same runbook for the four-hundredth time this month.
That repetitive front line is exactly what a voice agent should absorb. This tutorial builds an IT helpdesk voice agent on the AssemblyAI Voice Agent API that does four things real support lines need: it routes by issue type, looks up answers in your internal knowledge base, creates and checks tickets in your ITSM system, and escalates to a human when an issue needs one. We’ll build it on the managed Voice Agent API first because that’s the fastest path to something running, then show the bring-your-own-key (BYOK) alternative for teams that need a specific LLM or a cloned brand voice. A runnable repository is linked at the end.
One framing to set up front, because it drives every design decision below: in IT support, the speech-to-text layer is the part most likely to break the whole interaction. Helpdesk speech is dense with alphanumerics — ticket numbers like INC0012345, error codes like 0x80070005, asset tags, employee IDs, VLAN numbers, license keys. A general-purpose transcription model fumbles exactly those strings, and a single wrong character means the agent looks up the wrong ticket or files a useless one. Universal-3 Pro Streaming is tuned for this: 21% fewer alphanumeric errors and 28% better accuracy on consecutive numbers than the previous generation. That’s not a vanity metric for a helpdesk — it’s the difference between a contained call and an escalated one.
What the agent needs to do
Strip an IT helpdesk call down and there are four jobs. Map each to a concrete capability:
The Voice Agent API gives you the conversation loop — speech-to-text, the LLM, text-to-speech, turn detection, and tool calling — over a single WebSocket at a flat $4.50/hour. Your job is to define the four tools and write a system prompt that knows when to use them. Everything else (transcription accuracy, interruption handling, generating speech) is handled inside that one connection.
Architecture
Caller --PSTN--> Twilio number
|
| <Connect><Stream> (bidirectional, audio/pcmu)
v
bridge_server.py --ws--> Voice Agent API
| STT (Universal-3 Pro) + LLM + TTS
| + turn detection + tool calling
| |
| tool.call --------|
| +--------------+-------+-----------+-----------+
| v v v v
| search_kb create_ticket check_status escalate_to_human
| (interactive) (interactive) (interactive) (hold -> transfer)
| | | | |
| +---- tool.result (JSON) -------+ terminal: no result,
| returned on reply.done hand call to a queue
v
Your KB + ITSM (ServiceNow / Jira SM / Zendesk)
The bridge server is thin: it shuttles audio between Twilio and the Voice Agent API, and when the agent fires a tool call, it runs the work and returns the result. The three non-terminal tools (search_knowledge_base, create_ticket, check_ticket_status) follow a request/response round-trip — the agent asks, you answer, the conversation continues. The fourth, escalate_to_human, is terminal: it ends the agent’s session and hands the call to a person.
Before you start
You’ll need:
- An AssemblyAI account with Voice Agent API access
- A Twilio account with a voice-capable phone number
- Read/write API access to your ITSM (ServiceNow, Jira Service Management, or Zendesk) and a searchable knowledge base
- Python 3.11+
Install the dependencies:
pip install fastapi uvicorn "websockets>=14" python-dotenv twilio httpxStep 1: Define the helpdesk tools
Tools are JSON Schema function definitions you pass in the session config. The Voice Agent API emits a tool.call event when the LLM decides to use one; you run the work and send back a tool.result. Good tool descriptions are the highest-leverage thing you’ll write — the description is when to call this, and when not to, in plain language, because that’s the only instruction the model gets at call time.
# tools.py
SEARCH_KB = {
"type": "function",
"name": "search_knowledge_base",
"description": (
"Search the internal IT knowledge base for how-to steps
and known fixes. "
"Call this for any 'how do I' or 'why is X happening' question —
VPN setup, "
"password policy, software install steps, printer config, known
outages. "
"Do NOT call this to look up a specific ticket; use
check_ticket_status for that."
),
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The user's question, rephrased as a
search query.",
},
"category": {
"type": "string",
"enum": ["access", "network", "hardware", "software",
"security"],
},
},
"required": ["query"],
},
"execution_mode": "interactive",
"timeout_seconds": 15,
}
CREATE_TICKET = {
"type": "function",
"name": "create_ticket",
"description": (
"Open a new support ticket. Call this only after you have a
clear, "
"one-line problem description and the caller's employee ID. Read
the "
"returned ticket number back to the caller exactly as digits."
),
"parameters": {
"type": "object",
"properties": {
"employee_id": {"type": "string"},
"category": {
"type": "string",
"enum": ["access", "network", "hardware", "software",
"security"],
},
"priority": {"type": "string", "enum": ["low", "normal",
"high", "urgent"]},
"summary": {"type": "string", "description": "One-line
problem statement."},
},
"required": ["employee_id", "category", "summary"],
},
"execution_mode": "interactive",
"timeout_seconds": 15,
}
CHECK_STATUS = {
"type": "function",
"name": "check_ticket_status",
"description": (
"Look up the status of an existing ticket by its number "
"(for example INC0012345). Use this whenever the caller asks "
"'what's the status of my ticket' or gives you a ticket number."
),
"parameters": {
"type": "object",
"properties": {"ticket_id": {"type": "string"}},
"required": ["ticket_id"],
},
"execution_mode": "interactive",
"timeout_seconds": 15,
}
ESCALATE = {
"type": "function",
"name": "escalate_to_human",
"description": (
"Transfer the caller to a human technician. Call this when the
caller "
"asks for a person, when the issue is a security incident, when
a system "
"is down for many users, or when you cannot resolve the issue
after two "
"attempts. Always write a one-line summary first."
),
"parameters": {
"type": "object",
"properties": {
"queue": {
"type": "string",
"enum": ["service_desk", "identity_access", "network",
"security", "on_call"],
"description": "Which team should take the call.",
},
"summary": {
"type": "string",
"description": (
"One sentence a technician can read in two seconds.
Example: "
"'Dana Okafor (emp 4471) locked out of SSO after a
password "
"reset, MFA not arriving, needs urgent access.'"
),
},
},
"required": ["queue", "summary"],
},
"execution_mode": "hold",
}
HELPDESK_TOOLS = [SEARCH_KB, CREATE_TICKET, CHECK_STATUS, ESCALATE]
Two design points worth calling out. First, the category enum is your routing key — it appears in the KB search, the ticket, and the escalation queue, so the same classification the LLM makes for one tool carries through the whole call. Second, escalate_to_human uses execution_mode: "hold" while the other three use "interactive". Interactive tools are expected to resolve in a few seconds and the agent waits silently. A transfer is different — it takes longer and the agent should keep the line warm (“Let me get a technician for you — one moment”), which is what hold mode is for. The tool-calling docs cover the execution modes in full.
Step 2: The tool execution loop
This is the piece the conversational tutorials gloss over and the piece you have to get exactly right. The contract is specific: the agent sends a tool.call, and you return a tool.result keyed by the same call_id, with the result encoded as a JSON string (not a raw object). The timing matters too — you return results when the agent is idle, not the instant the call arrives, so you never interrupt audio that’s still playing.
# tool_loop.py
import json
async def run_tool(call: dict) -> dict:
"""Dispatch one tool.call to its handler. Returns a plain dict."""
name = call["name"]
args = json.loads(call.get("arguments") or "{}")
if name == "search_knowledge_base":
return await kb_search(args["query"], args.get("category"))
if name == "create_ticket":
return await itsm_create_ticket(args)
if name == "check_ticket_status":
return await itsm_get_ticket(args["ticket_id"])
return {"error": f"unknown tool {name}"}
async def flush_pending(va_ws, pending, last_type):
"""Return results only at a reply.done boundary, so we never
cut off audio the agent is still speaking."""
if last_type != "reply.done" or not pending:
return
for call in pending:
result = await run_tool(call)
await va_ws.send(json.dumps({
"type": "tool.result",
"call_id": call["call_id"],
"result": json.dumps(result), # result must be a JSON STRING
}))
pending.clear()The flow is: stash each tool.call in a pending list, and on the next reply.done, run the work and send every result. If the caller barges in (input.speech.started) before you’ve answered, drop the pending calls — the caller has moved on, and answering a stale question is worse than not answering it.
escalate_to_human is the exception to all of this. You never send a tool.result for it. Transferring the call ends the <Connect><Stream>, which tears down the Voice Agent session — there’s no live session left to receive a result. It’s a terminal tool. The deep mechanics of doing the transfer warmly (keeping a live transcript running for the technician across a conference bridge) are their own subject; the short version is that you detect the call, package the summary, and hand off at the telephony layer. The pattern below does the hand-off; the voice agents solution page covers the warm-handoff variant.
Step 3: Bridge Twilio to the Voice Agent API
Now wire it together. Twilio streams G.711 μ-law at 8 kHz, which the Voice Agent API accepts natively when you set the encoding to audio/pcmu — no transcoding, lowest latency. A few endpoint-specific details:
- The endpoint is wss://agents.assemblyai.com/v1/ws.
- Auth is Authorization: Bearer YOUR_KEY — note the Bearer prefix, which is specific to the Voice Agent API.
- The first message is a session.update event with everything nested under a session object. There is no separate session.start.
- Wait for session.ready before sending any input.audio frames. Voice, greeting, and output format are fixed once the session is ready, so set them in this first message — see the session configuration docs.
# bridge_server.py
import asyncio, json, os
import websockets
from fastapi import FastAPI, Request, WebSocket
from fastapi.responses import Response
from prompts import SYSTEM_PROMPT, GREETING
from tools import HELPDESK_TOOLS
from tool_loop import flush_pending, run_tool
from transfer import start_transfer
VOICE_AGENT_WS = "wss://agents.assemblyai.com/v1/ws"
ASSEMBLYAI_KEY = os.environ["ASSEMBLYAI_API_KEY"]
app = FastAPI()
@app.post("/twilio/voice")
async def twilio_voice(request: Request):
host = request.url.hostname
twiml = f"""<?xml version="1.0" encoding="UTF-8"?>
<Response>
<Connect>
<Stream url="wss://{host}/media-stream" />
</Connect>
</Response>"""
return Response(content=twiml, media_type="application/xml")
@app.websocket("/media-stream")
async def media_stream(twilio_ws: WebSocket):
await twilio_ws.accept()
stream_sid = {"value": None}
call_sid = {"value": None}
session_config = {
"type": "session.update",
"session": {
"system_prompt": SYSTEM_PROMPT,
"greeting": GREETING,
"tools": HELPDESK_TOOLS,
"input": {
"format": {"encoding": "audio/pcmu"},
# Boost the alphanumeric jargon a helpdesk hears
constantly.
"keyterms": ["Okta", "VPN", "MFA", "VLAN", "Kerberos",
"SSO", "ServiceNow", "Active Directory"],
"turn_detection": {
"vad_threshold": 0.5,
"min_silence": 800,
"max_silence": 2500,
"interrupt_response": True,
},
},
"output": {"voice": "ivy", "format": {"encoding":
"audio/pcmu"}},
},
}
async with websockets.connect(
VOICE_AGENT_WS,
additional_headers={"Authorization": f"Bearer
{ASSEMBLYAI_KEY}"},
) as va_ws:
await va_ws.send(json.dumps(session_config))
ready = asyncio.Event()
state = {"last_type": None, "pending": [], "transferring":
False}
async def twilio_to_va():
async for raw in twilio_ws.iter_text():
event = json.loads(raw)
kind = event.get("event")
if kind == "start":
stream_sid["value"] = event["start"]["streamSid"]
call_sid["value"] = event["start"]["callSid"]
elif kind == "media" and ready.is_set():
await va_ws.send(json.dumps({
"type": "input.audio",
"audio": event["media"]["payload"],
}))
elif kind == "stop":
return
async def va_to_twilio():
async for raw in va_ws:
event = json.loads(raw)
t = event.get("type")
state["last_type"] = t
if t == "session.ready":
ready.set()
elif t == "reply.audio" and stream_sid["value"]:
await twilio_ws.send_text(json.dumps({
"event": "media",
"streamSid": stream_sid["value"],
"media": {"payload": event["data"]},
}))
elif t == "input.speech.started":
state["pending"].clear() # caller barged in; drop
stale calls
elif t == "tool.call":
if event["name"] == "escalate_to_human" and not
state["transferring"]:
state["transferring"] = True
asyncio.create_task(
start_transfer(call_sid["value"],
event.get("arguments", {}))
)
else:
state["pending"].append(event)
elif t == "reply.done":
await flush_pending(va_ws, state["pending"],
state["last_type"])
await asyncio.gather(twilio_to_va(), va_to_twilio())That’s the whole bridge. Notice the asymmetry in how tools are handled in the tool.call branch: escalate_to_human fires off a telephony transfer and is never added to pending (it gets no result), while the three data tools are stashed and answered on the next reply.done. The keyterms list is doing quiet but important work — it nudges the recognizer toward the product names a helpdesk hears all day, so “Okta” doesn’t come back as “octa” and “VLAN” doesn’t become “v-land.”
Step 4: The system prompt does the routing
There’s no separate “router” component. Routing is the system prompt plus the tool descriptions — the LLM reads the caller’s problem, classifies it, and either resolves it with a tool or escalates to the right queue. Write the prompt as an operations runbook, not a personality.
# prompts.py
GREETING = "IT support, this line is recorded for quality. What can I help you with?"
SYSTEM_PROMPT = """You are the IT helpdesk voice agent for Northwind Corp.
You are calm, fast, and precise. One or two sentences per turn. Never lecture.
WHAT YOU HANDLE DIRECTLY (use search_knowledge_base, then guide the caller):
- Access: password policy, SSO setup, MFA enrollment, account unlock STEPS
- Network: VPN setup and troubleshooting, Wi-Fi, known outages
- Hardware: printer setup, monitor/dock issues, loaner requests
- Software: install/license steps for approved apps
TICKETS:
- Open a ticket with create_ticket when the issue needs follow-up or you cannot
resolve it live. Always get the employee ID first. Read the returned ticket
number back digit by digit and confirm it.
- For "what's the status of my ticket," use check_ticket_status with the number.
ROUTING / ESCALATION (call escalate_to_human with the right queue):
- "identity_access": account lockouts you cannot clear, suspicious login activity
- "network": a system or site down for MANY users
- "security": anything that sounds like a security incident, phishing, or breach
- "on_call": production outage outside business hours
- "service_desk": caller asks for a person, or two resolution attempts failed
HARD RULES:
- NEVER ask for or accept a password, PIN, or MFA code over the phone. To reset
credentials, trigger the self-service reset (it sends a secure link) or escalate
to identity_access for verified identity checks.
- NEVER invent a ticket number, an error-code meaning, or a fix. If the knowledge
base doesn't have it, say so and open a ticket or escalate.
- Confirm ticket numbers and error codes by reading them back before acting.
- For a security incident, escalate immediately — do not troubleshoot.
"""
Three things in that prompt earn their place. The routing block maps issue types to escalation queues, so “the whole sales floor lost network ten minutes ago” goes to network while “I think I clicked a phishing link” goes straight to security with no troubleshooting. The credential rule is a security boundary, not a nicety — a voice agent should never collect passwords or MFA codes; it triggers a self-service reset link or routes to a verified human check. And the anti-fabrication rule (“never invent a ticket number, an error-code meaning, or a fix”) is what keeps the agent trustworthy: it answers from the knowledge base or it says it doesn’t know and opens a ticket. An IT agent that confidently makes up a fix is worse than no agent.
Step 5: Ground every answer in the knowledge base
The search_knowledge_base handler is where “looks up answers in your docs” becomes real. The pattern that matters: return source snippets, and instruct the model to answer only from them. This is retrieval-augmented generation applied to a phone call — the LLM’s job is to read your runbook back conversationally, not to recall IT trivia from its training data.
# integrations.py
import httpx, os
KB_URL = os.environ["KB_SEARCH_URL"]
ITSM_URL = os.environ["ITSM_API_URL"]
ITSM_TOKEN = os.environ["ITSM_TOKEN"]
async def kb_search(query: str, category: str | None = None) -> dict:
async with httpx.AsyncClient(timeout=10) as http:
resp = await http.get(KB_URL, params={"q": query, "category":
category, "top": 3})
resp.raise_for_status()
hits = resp.json().get("results", [])
# Return only grounded snippets. The agent is instructed to answer
from these.
return {
"found": bool(hits),
"snippets": [{"title": h["title"], "text": h["summary"], "url":
h["url"]}
for h in hits],
}
async def itsm_create_ticket(args: dict) -> dict:
async with httpx.AsyncClient(timeout=10) as http:
resp = await http.post(
f"{ITSM_URL}/tickets",
headers={"Authorization": f"Bearer {ITSM_TOKEN}"},
json={
"requester_id": args["employee_id"],
"category": args["category"],
"priority": args.get("priority", "normal"),
"short_description": args["summary"],
"channel": "voice_agent",
},
)
resp.raise_for_status()
ticket = resp.json()
return {"ticket_id": ticket["number"], "state": ticket["state"]}
async def itsm_get_ticket(ticket_id: str) -> dict:
async with httpx.AsyncClient(timeout=10) as http:
resp = await http.get(
f"{ITSM_URL}/tickets/{ticket_id}",
headers={"Authorization": f"Bearer {ITSM_TOKEN}"},
)
if resp.status_code == 404:
return {"found": False}
resp.raise_for_status()
t = resp.json()
return {"found": True, "ticket_id": t["number"], "state":
t["state"],
"assigned_to": t.get("assigned_to"), "updated":
t.get("updated_at")}
The create_ticket handler returns the system-generated ticket number, and the prompt tells the agent to read it back digit by digit and confirm. That read-back loop is where Universal-3 Pro Streaming’s alphanumeric accuracy pays off twice: once when the agent hears the caller’s existing ticket number correctly, and again when the caller confirms the new one. Tag tickets with "channel": "voice_agent" so you can measure containment later — you’ll want to know how many of these the agent closed without a human.
When to go BYOK instead
The managed Voice Agent API is the fastest path: one connection, a flat rate, and STT, LLM, and TTS handled for you. But some teams need to choose their own components — a fine-tuned LLM that knows their internal systems, a cloned brand voice for TTS, or an existing orchestration stack they’ve already standardized on. That’s the bring-your-own-key path, and it’s where the competitive noise around “BYOK voice stacks” lives.
Here’s the honest framing. A composed voice stack is a chain — STT, then LLM, then TTS — and its accuracy ceiling is set by the first link. If transcription mishears INC0012345 as INC0012845, no downstream LLM or voice can recover; the agent confidently looks up the wrong ticket. So in a BYOK stack the speech-to-text layer isn’t a commodity, it’s the foundation. Universal-3 Pro Streaming (u3-rt-pro) is built for exactly the alphanumeric-dense speech IT support generates, at $0.45/hour, and it drops into any orchestrator.
Tools like LiveKit and Pipecat are orchestration frameworks — they manage the media transport and the STT→LLM→TTS loop. They’re integration partners, not alternatives: you point them at Universal-3 Pro Streaming for the transcription leg. The connection is the standalone Universal Streaming API, and the auth differs from the Voice Agent API in one easy-to-miss way:
# byok_stt.py — the transcription leg of a BYOK stack
import asyncio, json
import websockets
from urllib.parse import urlencode
STREAMING_WS = "wss://streaming.assemblyai.com/v3/ws"
async def transcribe_leg(pcm16_audio_source, on_final_transcript):
params = urlencode({
"speech_model": "u3-rt-pro", # Universal-3 Pro Streaming; no
default — required
"sample_rate": 8000, # match the telephony source;
don't upsample
"format_turns": "true",
})
async with websockets.connect(
f"{STREAMING_WS}?{params}",
additional_headers={"Authorization": ASSEMBLYAI_KEY}, # RAW
key, no "Bearer"
) as aai_ws:
async def send_audio():
async for pcm16_chunk in pcm16_audio_source:
await aai_ws.send(pcm16_chunk)
async def read_turns():
async for raw in aai_ws:
msg = json.loads(raw)
if msg.get("type") == "Turn" and msg.get("end_of_turn"):
# Hand the final transcript to YOUR LLM, then YOUR
TTS.
await on_final_transcript(msg["transcript"])
await asyncio.gather(send_audio(), read_turns())
Note the auth difference, because it’s the most common reason a copy-pasted snippet returns a 401: the standalone Streaming API takes the raw API key in the Authorization header, while the Voice Agent API takes Bearer YOUR_KEY. From there, on_final_transcript is your handoff point — send the text to your own LLM, or to the OpenAI-compatible LLM Gateway if you want a single endpoint fronting 25+ models, then to your TTS of choice. (If you’re in Python, pip install assemblyai wraps this WebSocket in a StreamingClient with the same parameters.)
The decision in one line: use the managed Voice Agent API to ship fast on a flat rate; go BYOK with Universal-3 Pro Streaming when you need a specific LLM or voice, or you already run LiveKit or Pipecat. Either way the transcription is the same accuracy, which is the part that decides whether the agent gets the ticket number right.
Measuring whether it’s working
Four numbers tell you if the helpdesk agent is earning its keep:
- Containment rate: the share of calls the agent resolved without escalating. Tag voice-agent tickets (we set channel: "voice_agent" above) and compare closed-without-transfer against total. This is the headline ROI number.
- Escalation precision: of the calls the agent escalated, how many genuinely needed a human. Too many means your routing rules are too eager; too few (callers asking twice for a person) means they’re too conservative.
- Alphanumeric accuracy: sample calls with ticket numbers and error codes, and check how often the agent captured them correctly. This is the metric most directly tied to your STT model — it’s where Universal-3 Pro Streaming should show its margin.
- First-contact resolution: of contained calls, how many didn’t generate a repeat call within 48 hours. A high containment rate with low first-contact resolution means the agent is closing calls it didn’t actually fix.
The complete repository
Fork the runnable repo at github.com/kelsey-aai/voice-agent-it-helpdesk. It includes the Twilio bridge, the four-tool definitions, the execution loop, mock KB and ITSM integrations you can swap for ServiceNow / Jira Service Management / Zendesk, the routing system prompt, and the BYOK transcription leg. Around 500 lines of Python.
Build your IT helpdesk agent
The fastest way to feel the difference accuracy makes on helpdesk speech is to call your own number and read it a ticket number. Create an AssemblyAI account to get an API key, then start from the Voice Agent API docs — the four tools above are the whole agent.
Frequently asked questions
How do I build a voice agent for IT helpdesk and technical support?
Build it on the AssemblyAI Voice Agent API, a single WebSocket that handles speech-to-text, the LLM, text-to-speech, turn detection, and tool calling. Define four function tools — search_knowledge_base for grounded how-to answers, create_ticket and check_ticket_status for your ITSM system, and escalate_to_human for transfers — and write a system prompt that classifies each call by issue type and picks the right tool or escalation queue. Bridge it to telephony with Twilio using audio/pcmu encoding, and run Universal-3 Pro Streaming so the agent transcribes ticket numbers, error codes, and asset tags accurately. The managed Voice Agent API runs at a flat $4.50/hour; a BYOK alternative uses Universal-3 Pro Streaming as the transcription layer under your own LLM and TTS.
Can a voice agent create and look up tickets in ServiceNow, Jira, or Zendesk?
Yes. Define create_ticket and check_ticket_status as function tools in the Voice Agent API session config. When the agent calls one, your bridge receives a tool.call event, makes the corresponding REST request to your ITSM platform (ServiceNow, Jira Service Management, or Zendesk), and returns a tool.result keyed by the same call_id with the result encoded as a JSON string. The agent then reads the ticket number back to the caller. Tag tickets with a voice_agent channel so you can measure containment afterward. The ITSM platform is yours to choose — the Voice Agent API doesn’t integrate with a specific one, it just calls whatever tool you define.
How does the voice agent route calls by issue type?
Routing happens in the system prompt and the tool descriptions, not in a separate component. The LLM reads the caller’s problem, classifies it into a category (access, network, hardware, software, security), and either resolves it with a knowledge-base lookup and a ticket, or escalates to the matching human queue. You encode the routing rules as plain instructions — for example, “a system down for many users goes to the network queue; anything that sounds like a security incident goes to security immediately with no troubleshooting.” Because the same category drives the KB search, the ticket, and the escalation queue, one classification carries through the whole call.
How do I stop the voice agent from making up answers about IT issues?
Two mechanisms. First, ground every answer: the search_knowledge_base tool returns source snippets from your runbooks, and the system prompt instructs the agent to answer only from those snippets and to say it doesn’t know (then open a ticket or escalate) when the knowledge base has nothing. This is retrieval-augmented generation on a phone call. Second, add explicit anti-fabrication rules to the prompt — “never invent a ticket number, an error-code meaning, or a fix” — and require the agent to read ticket numbers and error codes back to the caller for confirmation before acting.
Accurate transcription matters here too: if the agent mishears the input, even a grounded answer is about the wrong thing.
Should I use the managed Voice Agent API or a BYOK stack for IT support?
Use the managed Voice Agent API when you want to ship fast on a single connection and a flat $4.50/hour rate, with speech-to-text, LLM, and text-to-speech handled for you. Choose a bring-your-own-key (BYOK) stack when you need a specific fine-tuned LLM, a cloned brand voice, or you already run an orchestration framework like LiveKit or Pipecat. In the BYOK case, use Universal-3 Pro Streaming (u3-rt-pro, $0.45/hour) as the transcription layer — it’s the foundation of the stack, because if speech-to-text mishears a ticket number, no downstream LLM or voice can recover. LiveKit and Pipecat are orchestration partners, not alternatives; you point them at Universal-3 Pro Streaming for the speech-to-text leg.
Why does speech-to-text accuracy matter so much for IT support voice agents?
Because IT support speech is unusually dense with alphanumerics — ticket numbers like INC0012345, error codes like 0x80070005, asset tags, employee IDs, VLAN numbers, and license keys. A single wrong character means the agent looks up the wrong ticket, files a useless one, or troubleshoots the wrong error. General-purpose transcription models tend to fumble exactly these strings. Universal-3 Pro Streaming is tuned for them, with 21% fewer alphanumeric errors and 28% better accuracy on consecutive numbers than the previous generation, which on a helpdesk is the difference between a call the agent contains and one it has to escalate. Adding domain key terms (product names like Okta, VLAN, Kerberos) to the session config sharpens recognition further.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts