Veterinary transcription API: handling species, breeds, and vet drug names
The vet exam room is one of the hardest audio environments in medicine, and general models fall apart exactly where it matters — on the entities. Here's how to handle species, breeds, and vet drug names.



A vet's exam room is one of the hardest audio environments in medicine, and almost nobody builds for it.
Think about what a general-purpose speech-to-text model has to handle. A clinician dictating over a barking dog. A tech reading back a weight-based dose. An owner answering questions from across the room. Drug names that overlap with human pharmacology but get used at different doses for different reasons. Breed names that sound like nothing in any training corpus built on human conversation. "Brachycephalic." "Maine Coon." "Enrofloxacin."
Most transcription APIs were trained on podcasts, call-center audio, and meetings. Drop a veterinary exam on them and they fall apart exactly where it matters—on the entities. The good news is that the same vocabulary-accuracy engine we built for human clinical work handles veterinary transcription remarkably well. Works for doctors, works for you. Let me show you why, and where the honest gaps are.
The three things that break veterinary transcription
Veterinary audio fails general models in three predictable places. Knowing them tells you exactly what to configure.
Species and breeds. This is the vocabulary humans-only training data never sees. A model that's never encountered "brachycephalic" won't render it correctly—it'll guess something phonetically close and wrong. The same goes for breed names that carry real clinical weight. A French Bulldog's breathing complaint and a Maine Coon's cardiac screening aren't trivia; they're context that shapes the whole note. If the breed is mangled, the record loses meaning.
Drug names, including the dual-use ones. Here's where it gets interesting. A lot of veterinary pharmacology overlaps directly with human medicine. Gabapentin, meloxicam, and metronidazole show up in both. But veterinary practice also leans on drugs and brand names that rarely appear in human dictation: carprofen (Rimadyl), maropitant (Cerenia), enrofloxacin (Baytril), firocoxib (Previcox). A model strong on human clinical terms gets you most of the way. The vet-specific names are the gap.
Clinic-floor audio. Barking. Multiple handlers. An owner, a tech, and a clinician all in one room. This is overlapping, noisy, multi-speaker audio—the kind that needs real diarization to untangle who said what.
The engine: entity accuracy first
The foundation is Universal-3 Pro, which delivers best-in-market accuracy on the words that matter most—drug names, proper nouns, and rare words. That's the category veterinary transcription lives and dies on. A model that handles common conversational English beautifully but drops the drug name is useless in a clinical record, human or animal. We've argued at length that word error rate is the wrong way to judge this—what you actually care about is whether the entities survive.
Universal-3 Pro supports English, Spanish, French, German, Italian, and Portuguese, with native code-switching, at $0.21/hr async.
Then there's Medical Mode. And here I want to be straight with you rather than oversell it.
Medical Mode is built on human clinical terminology. It's tuned for the pharmacology, anatomy, and clinical language of human medicine—and that terminology overlaps heavily with veterinary practice. The drug classes, the dosing language, the anatomical vocabulary, the structure of a clinical note: a large share of that is shared. So Medical Mode gives you a real lift on the overlapping clinical pharmacology that veterinary work shares with human medicine. It is not a veterinary-specific model, and I won't pretend it is. It's a clinical-language engine that happens to cover most of what a vet says, because most of what a vet says is clinical language.
Turning it on is one parameter—domain="medical-v1"—and it works on both Universal-3 Pro and Universal-3.5 Pro Realtime.
Want to try it on a real exam recording? Get your free API key and run a file in minutes.
Keyterms prompting: where you close the gap
So Medical Mode covers the overlap. What covers carprofen, brachycephalic, and the name of the specialty drug your practice stocks that nobody else does?
Keyterms prompting. This is the mechanism for specialized and custom vocabulary, and it's the single most important feature for veterinary work specifically. You hand the model a list of the exact terms you care about—breed names, species, vet-specific and brand drug names, your practice's house vocabulary—and it weights them during recognition.
The limits: up to 1,000 terms on async (a $0.05/hr add-on), up to 100 on streaming, free, and updatable mid-stream. That last detail matters more than it sounds. Mid-stream updates mean a live transcription session can load a new patient's breed and medication context as the exam moves room to room.
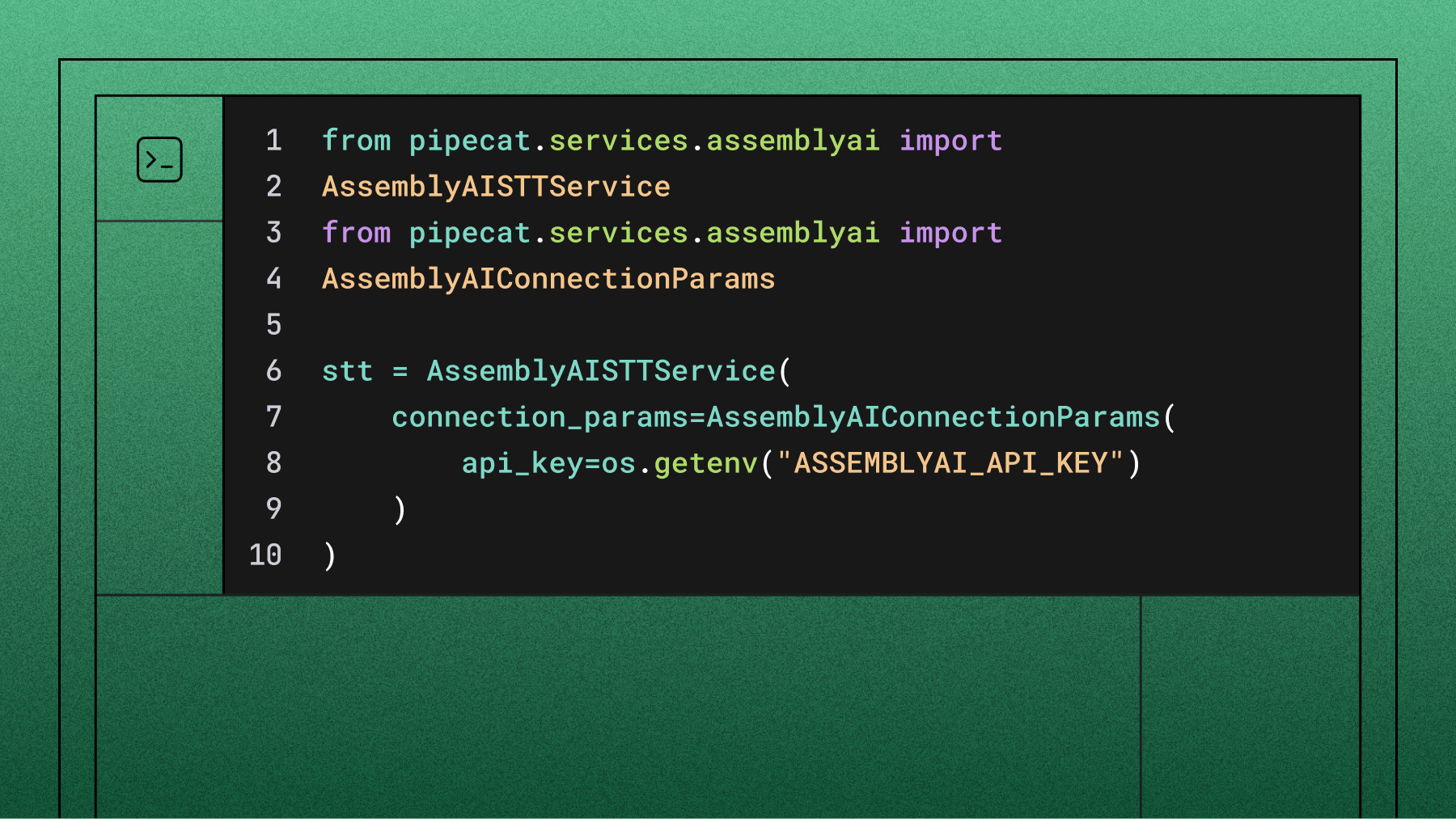
Here's the pattern:
import assemblyai as aai
transcriber = aai.Transcriber()
config = aai.TranscriptionConfig(
speech_models=["universal-3-pro"],
domain="medical-v1",
keyterms_prompt=["carprofen", "maropitant", "brachycephalic"],
)
transcript = transcriber.transcribe("audio.wav", config)Three terms there for illustration. In practice you'd load your full formulary, the breeds your clinic sees most, and any species-specific terms your dictation uses. Load enrofloxacin, firocoxib, Cerenia, Baytril, Previcox, French Bulldog, Maine Coon—whatever your records actually contain.
What the gap actually looks like
Here's an illustrative example—not a measured benchmark, just a concrete picture of the difference keyterms prompting makes on a vet-specific drug.
Illustrative example
Clinician says: "Started the Frenchie on carprofen, 2.2 milligrams per kilogram, twice daily."
Without keyterms prompting: "Started the Frenchie on car profen, 2.2 milligrams per kilogram, twice daily."
With keyterms_prompt=["carprofen"]: "Started the Frenchie on carprofen, 2.2 milligrams per kilogram, twice daily."
The drug name is the whole point of the sentence. Get it wrong and the medication record is wrong, the dose is attached to a non-word, and anything downstream that reads the note inherits the error. This is exactly the entity-accuracy problem at the center of every clinical pipeline—the difference is that in vet work, you've got a clean, simple lever to fix it.
Multi-speaker exam rooms: diarization
A vet exam usually isn't one voice. It's a clinician, a tech, and often the pet owner, all talking in the same room. To turn that into a usable record you need to know who said what.
That's speaker diarization. It separates the speakers so the owner's description of symptoms, the tech's readback, and the clinician's assessment land as distinct contributions instead of one undifferentiated wall of text. Combined with PII redaction for owner details, it gets you a transcript that's structured enough to actually build on.
The part most teams miss
The interesting thing about veterinary transcription is that it's not actually a harder problem than human clinical transcription—it's a different distribution of the same problem. The clinical-language backbone is shared. What changes is the long tail: the breeds, the species, the vet-specific drug names that no general training corpus weights heavily.
And the long tail is the one part of speech recognition you can configure directly. You can't hand-tune how a model handles general English, but you can hand it the exact 200 terms your practice uses every day and have it prioritize them. That makes veterinary transcription one of the more solvable specialized domains out there—not because the audio is easy, but because the hard part is a list you already know.
Write down your formulary and your breed list. That's most of your accuracy problem solved before you transcribe a single second.
Get your free API key and try it on your own exam audio: sign up here, or browse the docs to see the full keyterms prompting reference
Frequently asked questions
Is there a veterinary-specific transcription model?
Not as a separate model—and you don't need one. Universal-3 Pro's entity accuracy plus Medical Mode covers the large overlap between human and veterinary clinical language, and keyterms prompting covers the species, breed, and vet-specific drug gaps. That combination handles veterinary audio without a dedicated model.
Does Medical Mode actually help with animal patients?
Yes, because veterinary pharmacology and clinical language overlap heavily with human medicine—shared drug classes, dosing language, and anatomical terms. Medical Mode is built on human clinical terminology, so it lifts accuracy on everything shared. Keyterms prompting handles the rest.
How do I make sure carprofen, Cerenia, and breed names get transcribed correctly?
Load them into keyterms prompting—up to 1,000 terms on async, up to 100 on streaming, updatable mid-stream. It's the mechanism for custom and specialized vocabulary, and it's where you close the veterinary-specific gap.
Can it handle a noisy exam room with multiple people talking?
Yes. Speaker diarization separates the clinician, tech, and owner so the transcript attributes each statement to the right speaker, even in overlapping, noisy clinic-floor audio.
What does this cost to run?
Universal-3 Pro is $0.21/hr async. Medical Mode adds $0.15/hr ($0.36/hr combined). Keyterms prompting is a $0.05/hr add-on on async and free on streaming. Full details are on the pricing page.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts