
One stream, two jobs: introducing SpeakerRevision
Your live transcript and your final record no longer have to come from two different systems.



If you've built anything real-time on top of speech, you know the quiet compromise baked into the architecture. You run a streaming pass for the live experience, and then, when accuracy really counts, you run the whole thing again through async to get a clean final record.
This architectural split creates a burden: redundant pipelines, double-billing, and the headache of reconciling conflicting outputs. The root cause is streaming's inherent limitation—it must assign speaker labels instantly, without the benefit of future context. While asynchronous processing can analyze the entire dialogue to ensure precision, streaming has traditionally lacked that capability.
Today it does. We're shipping SpeakerRevision, a new message that arrives at the end of a stream and returns revised speaker labels for the entire conversation, with async-grade accuracy and only ~400ms of added latency on average.
What SpeakerRevision actually does
During the stream, you get speaker labels in real time, exactly as you do now. That's what drives your live captions, your turn logic, your agent's sense of who's speaking. Nothing about that experience changes.
When the stream ends, SpeakerRevision sends one more message: a corrected speaker map that's had the benefit of hearing the full conversation. Early-stream guesses that only made sense in hindsight get fixed. Speakers who were briefly confused get reconciled. The result is a final transcript you can write to a record, hand to an LLM, or show a customer, without spinning up a separate async job to get there.
The message itself is straightforward. At the end of the session, a single SpeakerRevision message arrives with a revisions array. Each entry revises one turn, and only turns whose speaker assignment changed are included. The turn_order field on each entry maps back to the turn_order of the original Turn message it corrects.
The cost of that final pass is about 400 milliseconds. That's the whole tradeoff.
{
"type": "SpeakerRevision",
"revisions": [
{
"turn_order": 3,
"speaker_label": "B",
"words": [
{ "text": "Hello", "start": 1200, "end": 1450, "speaker": "B" },
{ "text": "there.", "start": 1450, "end": 1780, "speaker": "B" }
]
},
{
"turn_order": 7,
"speaker_label": "A",
"words": [
{ "text": "Got it.", "start": 4100, "end": 4520, "speaker": "A" }
]
}
]
}
The numbers
With SpeakerRevision enabled, the final speaker labels reach a level of accuracy that streaming simply hasn't offered before:
- DER: 17.67%, a 24% relative improvement
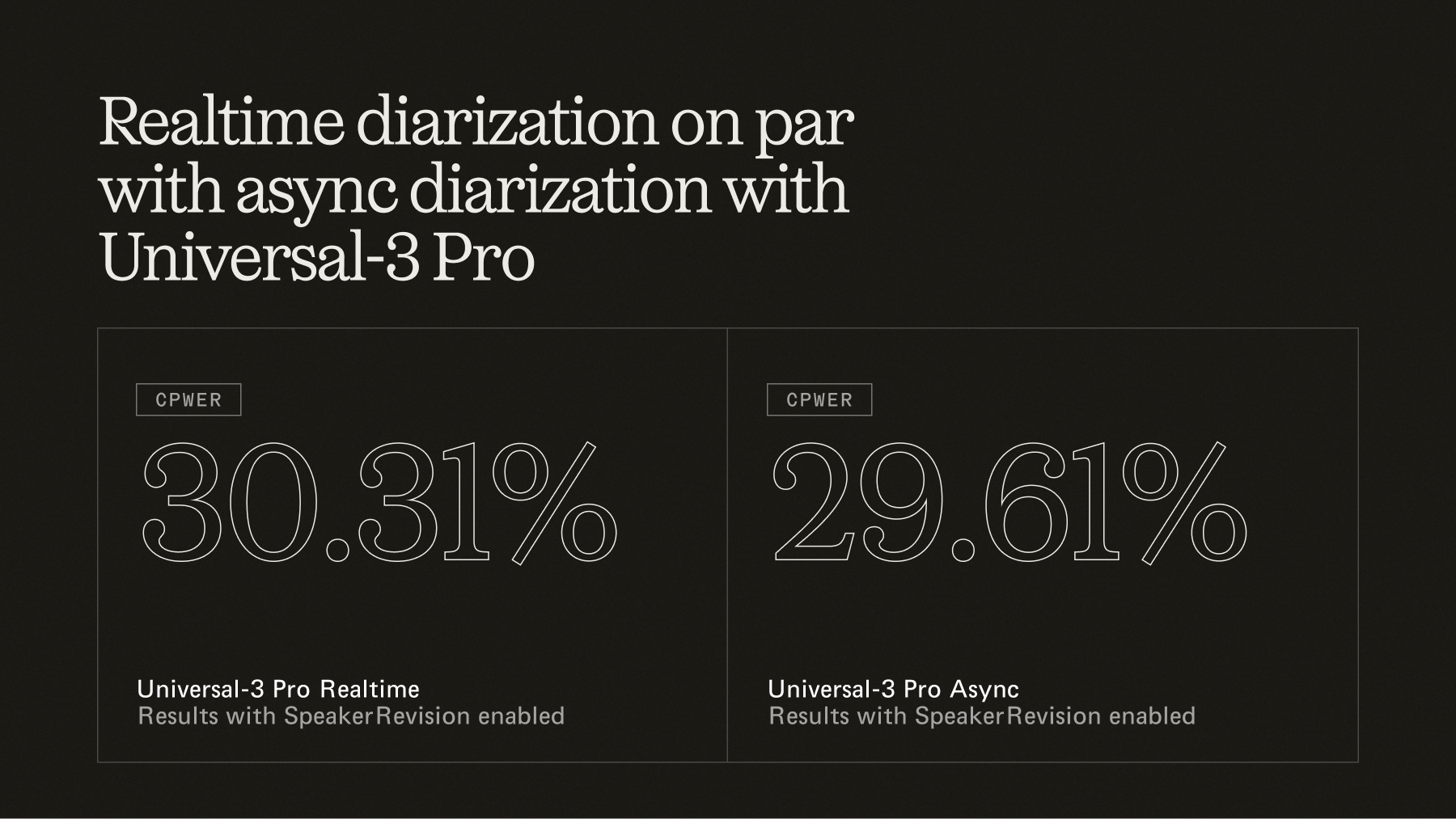
- cpWER: 30.31%, a 22% relative improvement
- False-alarm speakers: 0.14, an 84% relative reduction, meaning hallucinated speakers who were never in the room almost entirely disappear from the final output

The headline, though, is the comparison that used to be impossible to make. Across four test sets, our streaming diarization with SpeakerRevision now lands on par with async on cpWER: 30.31% streaming vs. 29.61% for async Universal-3 Pro. The accuracy you used to need a second pipeline for is now available at the end of your stream.
And against the field:
- vs. Deepgram Nova-3: 47% better on DER, 43% better on cpWER
- vs. Soniox: 49% better on DER, 32% better on cpWER
Why this matters for what you're building
For an AI notetaker, SpeakerRevision means the transcript your user downloads after the meeting is already clean. No separate reprocessing step, no "give us a minute to finalize." The live view and the saved record come from the same stream.
For contact center analytics, it means the final, attributed transcript that feeds your QA scoring and your LLM summaries is async-grade, without doubling your transcription footprint across thousands of calls.
For agent-assist and voice agents, the live labels keep driving the real-time experience, while SpeakerRevision gives your post-call analysis a corrected source of truth to work from.
The pattern is the same everywhere. You stop maintaining two pipelines to get speed and accuracy. One stream gives you both.
Getting started
SpeakerRevision is a new message type, so you'll want to make sure your integration is set up to receive it. Updated SDKs and docs are linked below, and existing streaming diarization customers can opt in today.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts
.png)
.png)
