Multilingual streaming with Universal-3 Pro: Native code switching across 6 languages
Multilingual speech-to-text API for real-time streaming with native code switching across 6 languages, speaker diarization, and low-latency accurate transcripts.

.png)

Multilingual speech-to-text APIs process audio containing multiple languages through a single request, automatically detecting and transcribing language switches without requiring separate API calls for each language. Unlike traditional systems that break down when speakers mix languages naturally, modern multilingual APIs handle code-switching—where people alternate between languages mid-sentence—as seamlessly as single-language speech.
This capability matters because real conversations don't follow language boundaries. When a customer service representative switches from English to Spanish mid-conversation, or when someone says "Let's schedule the reunión for Thursday," your application needs to capture every word accurately without losing context or breaking the transcription flow.
This guide covers the core technical concepts behind multilingual Voice AI, from native code-switching detection to speaker diarization across language boundaries, plus practical implementation patterns for production applications using Universal-3 Pro Streaming.
What is a multilingual speech-to-text API?
A multilingual speech-to-text API is a service that converts spoken audio containing multiple languages into written text through a single request. This means you don't need to know which language someone is speaking—the API automatically detects and transcribes multiple languages as speakers switch between them, even within the same sentence.
Traditional speech-to-text systems require separate API calls for each language. If your audio contains English and Spanish, you'd need two different requests and somehow combine the results. Multilingual APIs eliminate this complexity by handling everything in one call.
The real advantage becomes clear when people mix languages naturally. When a customer service representative switches from English to Spanish mid-conversation, or when someone says "Let's schedule the reunión for Thursday," a true multilingual API processes this seamlessly without breaking the transcription or losing context.
Unified multilingual models vs. language-specific models
Unified multilingual models process all languages simultaneously within a single system. This means the same AI model recognizes English, Spanish, French, and other languages without switching between different sub-models.
Language-specific models work differently—they're essentially multiple separate models stitched together. When the system detects a language change, it switches to a different model designed specifically for that language.
The practical difference matters enormously:
- Unified models: Maintain speaker identity when someone switches languages
- Language-specific models: Often treat language switches as new speakers
- Unified models: Handle mid-sentence language mixing naturally
- Language-specific models: Break or produce errors when languages mix within sentences
Here's how different streaming models compare across key capabilities:
Core multilingual capabilities for production
Production applications need three critical capabilities from multilingual APIs. These features determine whether your system can handle real-world multilingual conversations or just basic language detection.
Native code-switching detection
Code-switching is when speakers alternate between languages. This happens in two ways: between complete sentences or within a single sentence.
Inter-sentential code-switching happens between sentences: "How are you today? ¿Cómo está el proyecto?" Most basic multilingual systems can handle this because there's a clear boundary between languages.
Intra-sentential code-switching happens within sentences: "Let's schedule the reunión for Thursday at tres de la tarde." This is where most systems fail—they either produce garbled text or miss words entirely.
Universal-3 Pro's unified model treats intra-sentential switching as natural speech, not an error to correct. The system doesn't need sentence boundaries to recognize language changes. It seamlessly transitions between languages exactly as the speaker does.
To use Universal-3 Pro for multilingual streaming, you only need to specify the model.
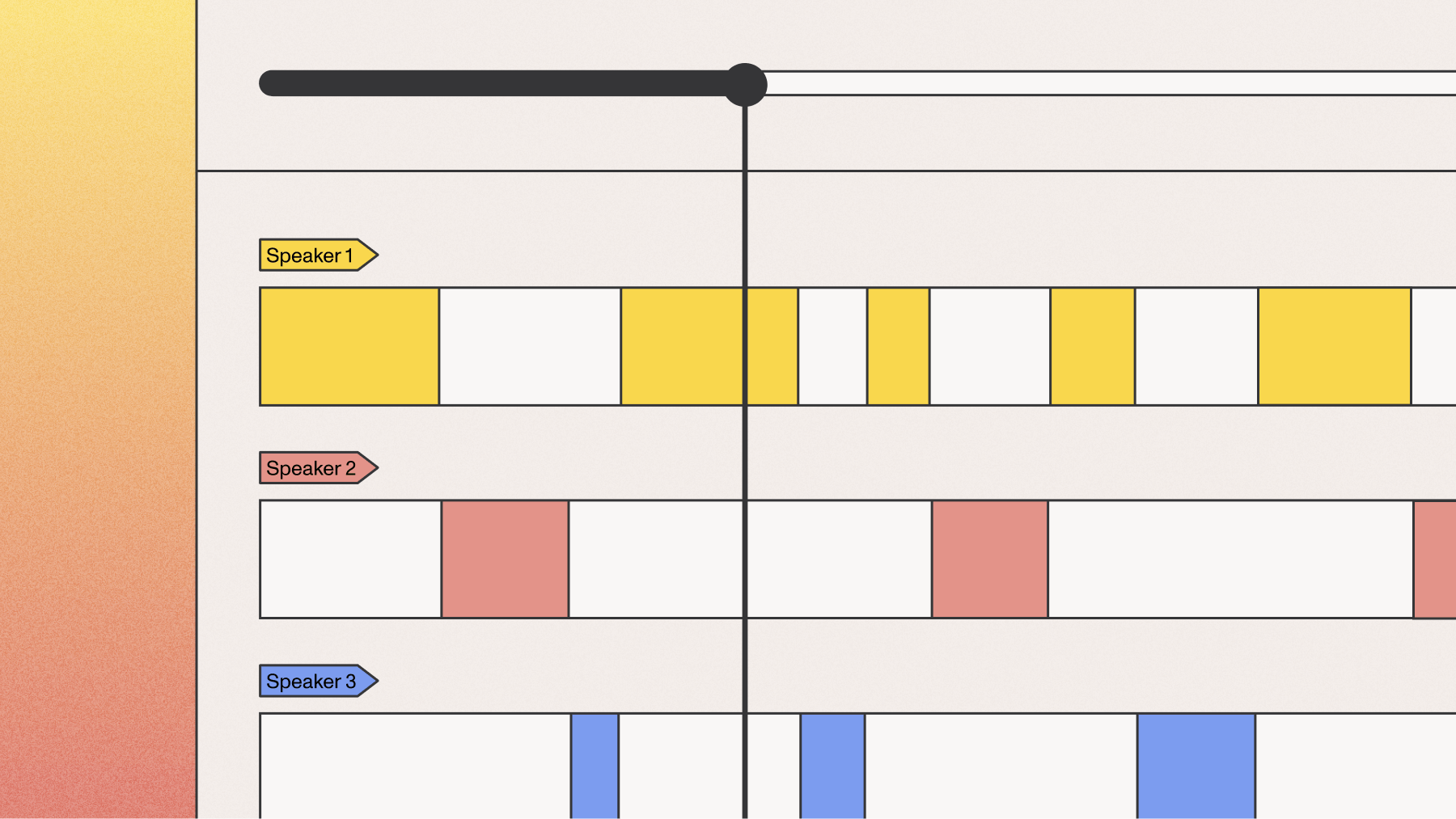
Speaker diarization across language boundaries
Speaker diarization identifies who's speaking when in a conversation. The challenge with multilingual audio is maintaining correct speaker identification when the same person switches languages.
Many systems mistakenly create new speakers when someone switches languages because they interpret the language change as a different person talking. This creates confusing transcripts where one person appears to be multiple participants in the conversation.
Universal-3 Pro maintains speaker identity regardless of which language someone speaks. The same person speaking English then Spanish remains "Speaker A" throughout the entire conversation.
Key capabilities include:
- Language consistency: All six supported languages (English, Spanish, French, German, Italian, Portuguese) include full diarization support
- Speaker limits: Handles up to four speakers reliably in most conditions
- Minimum utterance: Requires approximately three-word utterances for accurate speaker identification
For multilingual diarization, use these parameters:
# Add speaker diarization to base config
config["speaker_labels"] = True
Model selection for streaming applications
The streaming API uses the speech_model parameter (singular) to select one model for the entire streaming session. Unlike the asynchronous API, streaming does not support automatic model routing—you choose a single model that handles your entire conversation.
For multilingual streaming, you have two primary options:
- Universal-3 Pro (
u3-rt-pro): Best accuracy for code-switching across English, Spanish, French, German, Italian, and Portuguese - Universal Streaming Multilingual (
universal-streaming-multilingual): Broader language coverage with per-turn language detection
If your application expects languages outside Universal-3 Pro's six supported languages, implement client-side logic to handle these scenarios. Options include prompting users for language selection, using separate streaming sessions, or implementing post-processing strategies.
Real-time multilingual streaming: Technical considerations
Two Universal-3 Pro behaviors affect how you build streaming applications, and they're different from other streaming models.
Partial transcripts: Universal-3 Pro only produces partial transcripts during periods of silence, not continuously like other streaming models. You'll see at most one partial per silence period. This design prioritizes accuracy over word-by-word streaming, so plan accordingly if you're building live caption displays.
Latency: Despite the multilingual complexity, Universal-3 Pro maintains sub-300ms time-to-complete-transcript latency with unlimited concurrency. This makes it suitable for high-volume applications like call centers and meeting platforms.
Latency impact of language switching
Language switching itself doesn't add measurable latency to Universal-3 Pro because the unified model doesn't restart when languages change. The system uses parallel language probability modeling that determines the most likely language within the current speech segment.
The primary latency control is the min_turn_silence parameter:
- Default: 400ms for u3-rt-pro
- Low latency: 100ms provides the fastest possible response times
- High volume: Unlimited concurrency means thousands of simultaneous streams maintain the same low latency
Streaming language detection works with limited context compared to batch processing, which analyzes entire files before transcription. However, Universal-3 Pro's approach balances speed with accuracy effectively for real-time applications.
Multilingual accuracy: Testing and validation
Generic accuracy metrics don't predict how well a multilingual API will perform on your specific audio. Code-switching boundaries, accented speech, and real-time processing all affect accuracy in ways that standard benchmarks don't capture.
Focus your testing on three key areas that matter for production applications:
- Per-language accuracy: Test each language you expect with your actual domain vocabulary
- Accented speech performance: Use audio from your target user demographics, not generic test samples
- Code-switching accuracy: Test realistic language mixing patterns your users exhibit
Accuracy across regional variants and accents
Regional variants present unique challenges beyond basic language support. A system might excel at Mexican Spanish while struggling with Argentinian Spanish, or handle American English perfectly but falter on Scottish accents.
Training data representation determines performance on regional variants. Models that underrepresent certain dialects produce higher error rates for those variants, even when the base language is well-supported.
Universal-3 Pro shows consistent improvements in accented speech accuracy and medical terminology compared to previous streaming models. These improvements matter particularly for healthcare applications and global enterprise deployments where accent diversity is common.
Always test with audio that matches your specific regional variants and user demographics. Generic test audio won't predict real-world performance accurately.
Implementation patterns for multilingual workflows
You have several approaches for implementing multilingual transcription, each suited to different requirements and use cases.
Recommended default: Start with single API automatic detection for simplicity. Choose a multilingual streaming model that covers your expected languages, with Universal-3 Pro providing the best accuracy for its six supported languages.
Cross-language custom vocabulary and prompting
Universal-3 Pro supports prompting to improve recognition of domain-specific terms, brand names, and technical vocabulary across all supported languages. Prompts apply to the unified model regardless of which language is currently active.
This eliminates the complexity of maintaining separate vocabulary lists for each language. One prompt improves recognition across English, Spanish, French, German, Italian, and Portuguese simultaneously.
Structured prompts work better than abstract instructions.
Final words
Multilingual speech-to-text APIs transform how you handle global voice applications by processing mixed-language conversations through a single request. The key distinctions—native code-switching versus per-turn detection, unified acoustic modeling for consistent speaker identity, and intelligent routing strategies—determine real-world performance far more than supported language counts.
AssemblyAI's Universal-3 Pro Streaming delivers native mid-sentence code switching across six languages, maintains speaker identity regardless of language changes, and provides sub-300ms latency with unlimited concurrency. The unified model architecture handles the complexity of multilingual speech recognition while keeping implementation simple through automatic detection and intelligent routing capabilities.
Frequently asked questions
How accurate is multilingual speech-to-text compared to English-only models?
Multilingual models show slight accuracy differences versus English-only models on pure English audio, but for mixed-language applications, consistency across languages and code-switching correctness matter more than single-language performance. Universal-3 Pro's unified architecture minimizes accuracy gaps while enabling capabilities impossible with single-language models.
Can multilingual APIs handle people switching languages mid-sentence?
Universal-3 Pro handles mid-sentence language switches natively through its unified model architecture. Most other APIs, including Universal-Streaming Multilingual, only detect language changes at sentence or turn boundaries, making them unsuitable for natural code-switching conversations.
Do I need separate API requests for audio containing multiple languages?
Modern multilingual APIs like Universal-3 Pro process mixed-language audio in a single request. The streaming API uses speech_model (singular) to select one multilingual model for the entire session. Choose a model like u3-rt-pro for optimal code-switching support across its six supported languages, or universal-streaming-multilingual for broader language coverage.
What happens when someone speaks a language Universal-3 Pro doesn't recognize?
Universal-3 Pro streaming supports six languages: English, Spanish, French, German, Italian, and Portuguese. For languages outside this set, implement client-side strategies such as using universal-streaming-multilingual which has broader language coverage, prompting users for language selection, or managing separate streaming sessions based on detected language needs.
How do regional accents affect multilingual transcription accuracy?
Regional variants can significantly impact accuracy when training data underrepresents specific dialects. Universal-3 Pro shows improved accented speech performance, but you should still test with audio samples that match your target user demographics rather than relying on generic language benchmarks.
Does real-time streaming reduce multilingual transcription quality?
Streaming operates on shorter context windows compared to batch processing, which can affect language detection at segment boundaries. Universal-3 Pro's streaming and batch models share the same multilingual architecture, so accuracy differences are smaller than with previous model generations.
What should I do when automatic language detection fails?
Common failure scenarios include very short audio segments, heavy background noise, or similar language pairs like Portuguese and Spanish. Use language hints when user languages are known, choose a multilingual model with appropriate language coverage for your use case, and monitor for detection confidence where available in your application.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.