Introducing Universal-3 Pro: A new class of speech language model optimized for Voice AI
Today we're releasing Universal-3 Pro, a first of its kind promptable speech language model. And we’re so confident you’ll be blown away by its performance that you can use the model free for all of February to see for yourself.



There's signal locked in every voice conversation be it customer calls, medical scribes, AI notetaking, voice agents. Almost every vertical is building with voice data. We know because we’re powering most of them.
Today we're releasing Universal-3 Pro, a first of its kind promptable speech language model. And we’re so confident you’ll be blown away by its performance that you can use the model free for all of February to see for yourself.
Start building for free with Universal-3 Pro today. →
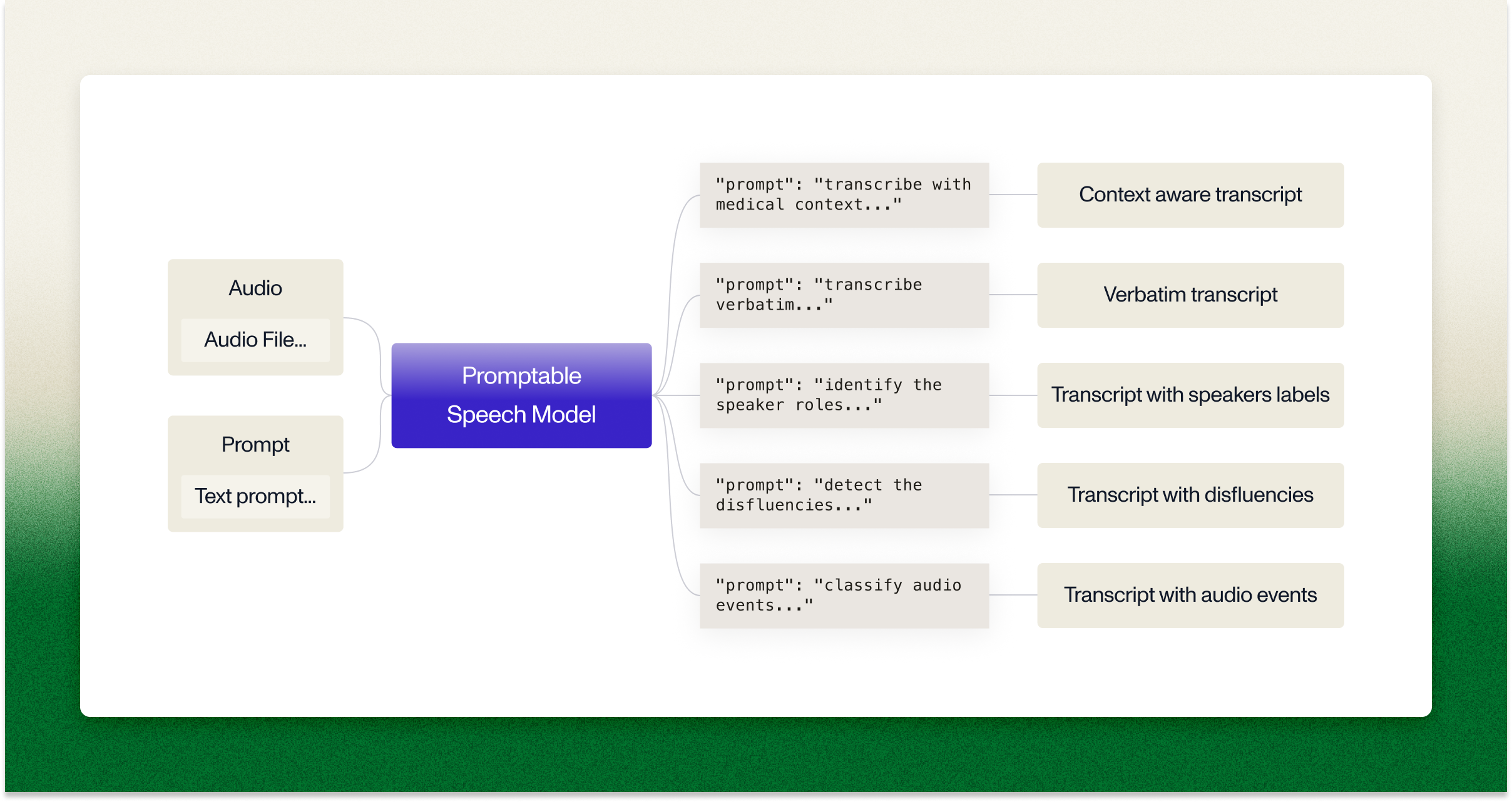
Universal-3 Pro is the first production-quality speech model that adapts its behavior based on the instructions you provide. Every capability in Universal-3-Pro: audio tagging, disfluency capture, speaker labeling, works through prompting. Describe your audio in plain language and the model adjusts its transcription accordingly:

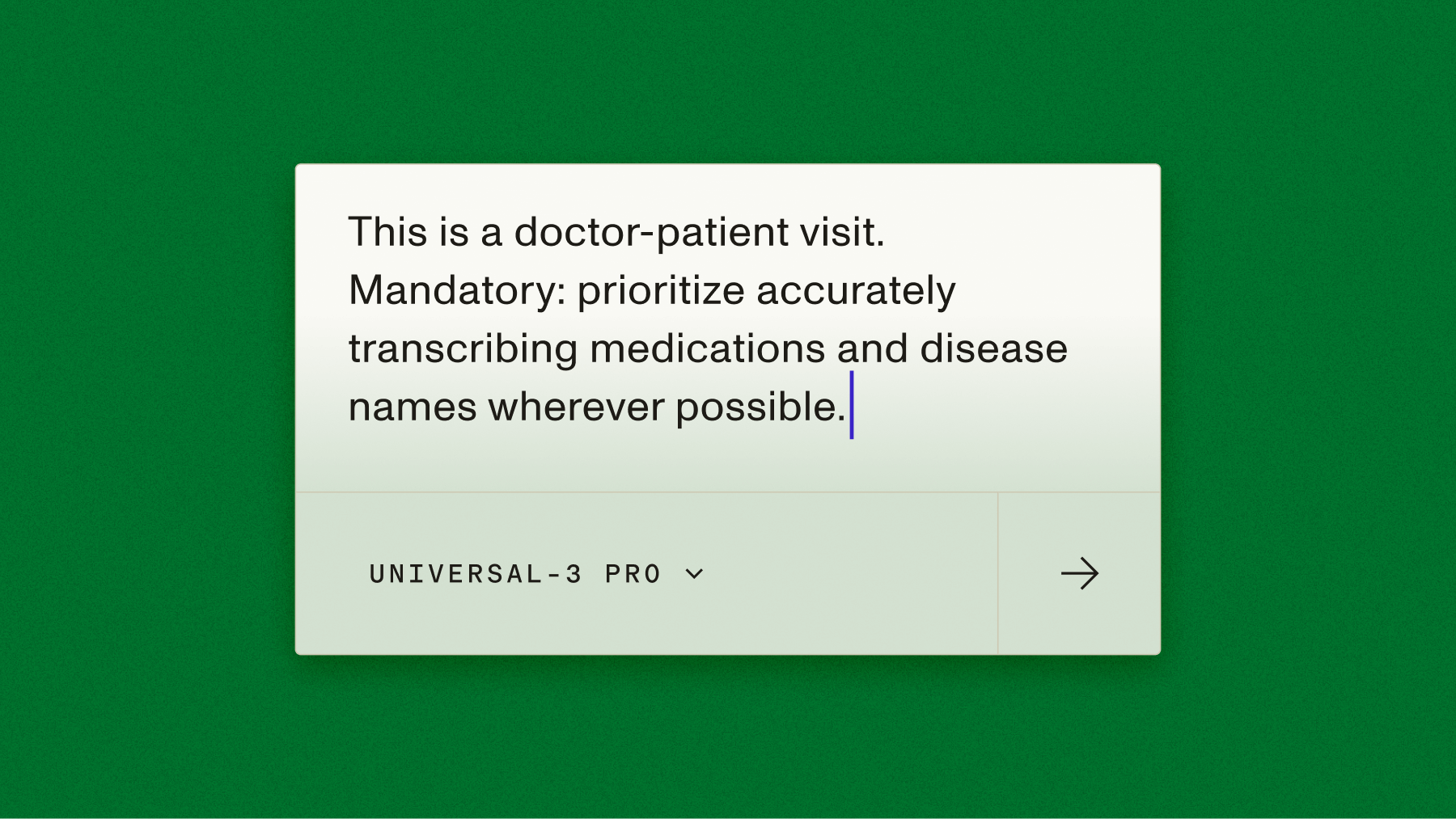
"prompt": "Produce a transcript for a clinical history evaluation. It's important to capture medication and
dosage accurately. Every disfluency is meaningful data. Include: fillers (um, uh, er, erm, ah, hmm, mhm,
like, you know, I mean), repetitions (I I I, the the), restarts (I was- I went), stutters (th-that, b-but,
no-not), and informal speech (gonna, wanna, gotta)"
The model preserves natural speech patterns while correctly transcribing "glycoside"—critical when phonetically similar terms affect patient safety.
Describe what you're transcribing in plain language: "This is a customer support call about technical troubleshooting" or "This is a board meeting discussing Q4 financial results." The model interprets these instructions and adjusts accordingly. No parameter configuration required.
A powerful new way to build with voice:
The old way
Transcribe, then run complex pipelines of regex and LLM calls to extract what you need. Company names get mangled. Jargon becomes gibberish. You build correction layers on correction layers.
Worse: by the time you're fixing errors, you've lost the acoustic information, like tone, hesitation, emphasis, that would have helped you get it right.
The new way
Universal-3 Pro accepts prompts before transcription. Give it context, like names, terminology, topics, format, and it uses that while processing audio, not after.
You get accurate output at the source. The transcript is correct the first time.
The same model, prompted differently, gives you speaker ID, disfluency detection, audio event classification. Instead of separate tools, you get different outputs from one model that understands the full audio. Prompt for verbatim transcription, speakers, or domain-specific output with medical context. One model, one integration.
Keyterm prompting: 45% accuracy improvement on domain-specific terms
Include up to 1,000 words of domain vocabulary through prompting. The model learns error patterns from your examples and applies corrections across related terms, including those not explicitly listed.
"keyterms_prompt": ["Kelly Byrne-Donoghue"]

Testing shows up to 45% accuracy improvements when prompting is used effectively.
Audio tagging: Control what gets captured beyond words
Control whether the model captures non-speech audio and which events matter for your use case. Universal-3 Pro gives you explicit control, preventing garbage transcription from phone system artifacts and reducing false transcription errors.
"prompt": "Produce a transcript suitable for conversational analysis. Every disfluency is meaningful data.
Include: Tag sounds: [beep]"
Trained on 50+ audio event tags including [laughter] [silence] [beep] [hold music] [noise] [inaudible] and more, with the ability to prompt endless custom tags for domain-specific audio events.
Traditional ASR either hallucinates non-speech audio as random words or strips all acoustic context. Through prompting, you control exactly what gets tagged, preserving meaningful audio events that affect how calls are interpreted.
Disfluency control: Prompt for verbatim or clean transcription
Control conversational speech patterns to capture legally-defensible verbatim records or clean, readable transcripts, all without building custom post-processing logic:

Use this prompt structure to capture natural speech patterns:
Transcribe verbatim:
- Fillers: yes (um, uh, like, you know)
- Repetitions: yes (I I, the the)
- False starts: yes (I was- I went)
- Stutters: yes (th-that, b-but)
This capability matters for applications where exact phrasing affects meaning. In legal transcription, "I agree" versus "I, uh, I guess I agree" carries different evidentiary weight. In sales coaching, hesitation patterns reveal where representatives struggle with objection handling. In medical documentation, precise language affects patient consent records.
Promptable speaker diarization: Track every speaker turn, even the shortest injections
Prompting speaker labels with Universal-3 Pro works especially well in cases where there are frequent interjections, such as quick acknowledgments or single-word responses.
"prompt": "Produce a transcript with every disfluency data. Additionally, label speakers with their
respective roles. 1. Place [Speaker:role] at the start of each speaker turn. Example format:
[Speaker:NURSE] Hello there. How can I help you today? [Speaker:PATIENT] I'm feeling unwell. I have a
headache."
}

Code-switching: Support the way your customers actually speak
Universal-3 Pro supports six languages natively: English, Spanish, German, French, Portuguese, and Italian, with built-in code-switching that handles natural language mixing within conversations.
Common code-switching patterns:
- "Hola, can you help me find información about my account balance?"
- "Je voudrais un appointment for next week, s'il vous plaît"
Set "language_detection": True, as shown in the code example below, to automatically detect the spoken language from the audio.
data = { "audio_url": "https://assemblyaiassets.com/audios/code_switching.mp3", "language_detection":
True, "speech_models": ["universal-3-pro", "universal"]
"prompt": "You are transcribing a recording of a natural conversation between bilingual Spanish-English
speakers. These speakers are fluent in both languages and switch between them naturally, sometimes multiple
times within a single sentence. This phenomenon is called code-switching and is common among bilingual
communities. Your task is to transcribe every word exactly as spoken, preserving the language of each word.
Do not translate. Do not normalize. Do not correct perceived errors. Spanish words should be spelled with
proper Spanish orthography including accent marks. English words should remain in English even when
surrounded by Spanish. Capture all filler words, hesitations, and repetitions in both languages."

Intelligent language routing: Comprehensive global coverage
For comprehensive global coverage, use the speech_models parameter to access all 99 languages AssemblyAI supports. Simply list multiple speech models in priority order, and the system automatically routes your audio based on language support, eliminating the need for custom language detection systems.
config=aai.TranscriptionConfig( speech_models=["universal-3-pro", "universal"] )The system attempts to use the models in priority order falling back to the next model when needed. For example, with ["universal-3-pro", "universal"], the system will try to use Universal-3 Pro for languages it supports (English, Spanish, Portuguese, French, German, and Italian), and automatically fall back to Universal for all other languages. This ensures you get the best performing transcription where available while maintaining the widest language coverage.
Why not a multimodal foundation model?
Multimodal foundation models like Gemini can accept audio directly and follow instructions. Why build something specialized?
General-purpose models are designed to be good at many things, which is useful for prototyping, but less so when your business depends on processing thousands of hours of calls daily. These models are generalists built to handle text, images, video, and audio across countless tasks. This creates reliability issues in production: they might try to respond to your audio instead of transcribing it, especially with conversational content. You have to carefully structure outputs as JSON and handle cases where the model doesn't follow your format. When they encounter unclear audio, they often generate plausible-sounding words that weren't actually spoken.
Universal-3 Pro trains exclusively on speech: 100% transcription, speaker identification, and audio understanding. You get instruction-following capability combined with deterministic ASR reliability. The output is always a transcript. Your prompts control how that transcript is generated—not whether you get a transcript at all. This exclusive focus significantly reduces hallucinations, preventing fabricated content from entering your transcripts when accuracy affects compliance, legal records, or clinical documentation.
There's also cost and production reliability to consider. Multimodal models are expensive at scale, and consistent latency, native speaker identification, and handling acoustic edge cases aren't capabilities you get by adding audio as another modality to a foundation model.
For voice-first products, the specialized approach wins.
Best price performance on real-world data
Universal-3 Pro delivers the lowest word error rate on real-world data at a fraction of the cost of competing solutions. The testing methodology uses diverse audio, including call center recordings with background noise, medical consultations with domain terminology, business meetings with multiple speakers, and accented speech across supported languages. This approach measures performance under real-world conditions that production applications actually encounter, not laboratory recordings.
At $0.21/hour, Universal-3 Pro provides best-in-class accuracy at 35-50% lower cost than competing solutions, with no rate limits or upfront commitments. Volume discounts ensure cost-effectiveness as you scale.
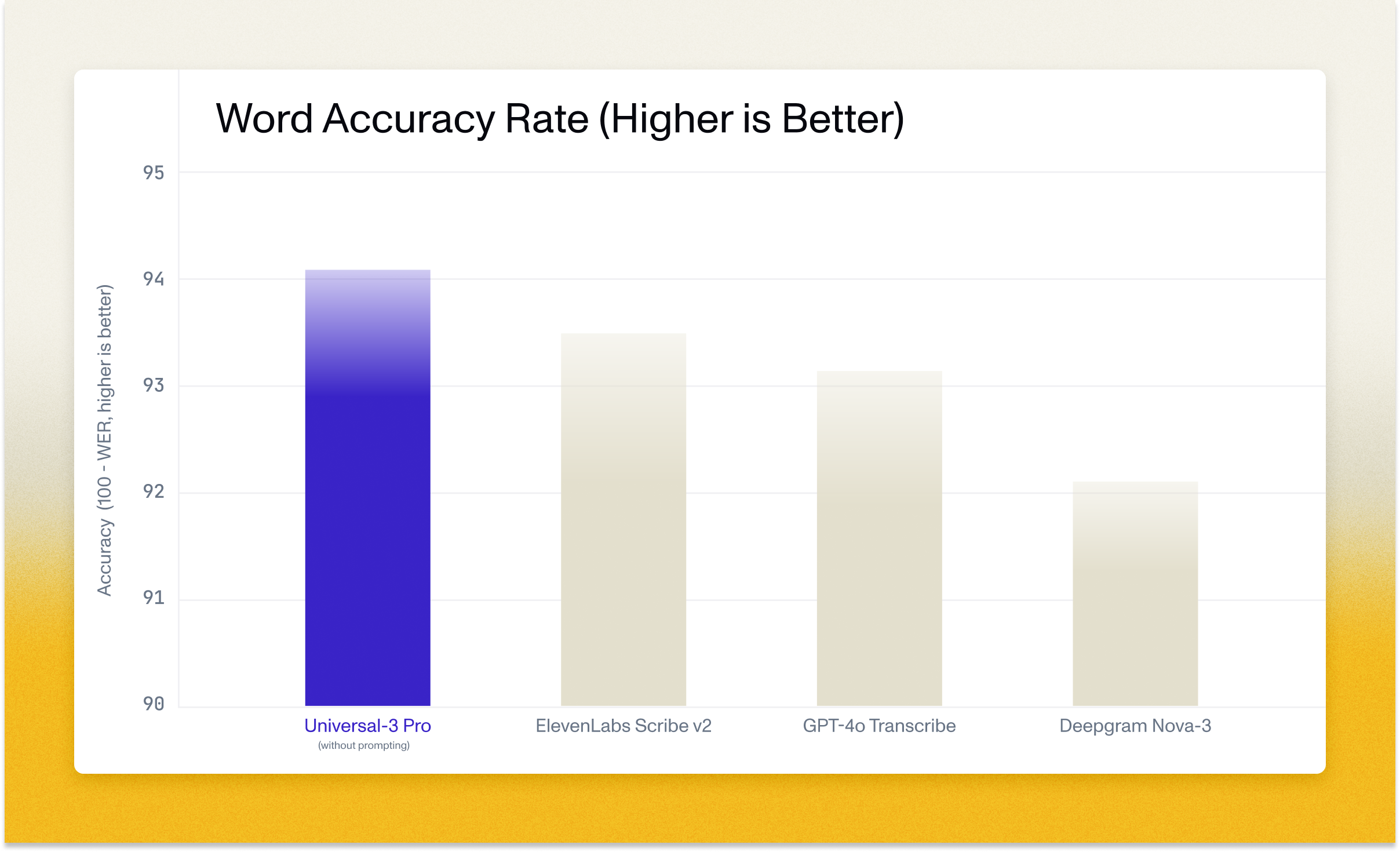
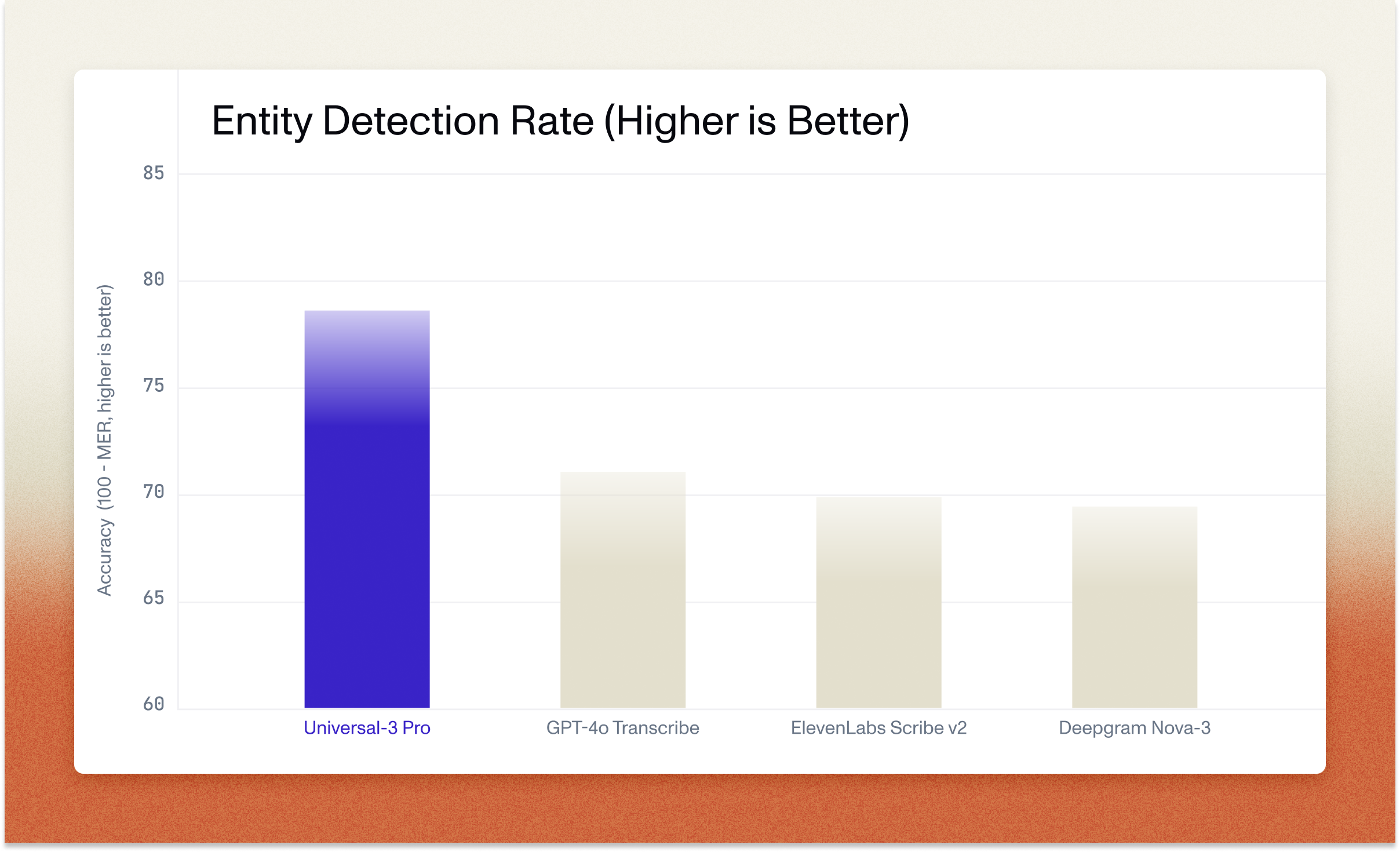
How prompting improves upon baseline accuracy
Universal-3 Pro delivers production-ready accuracy out of the box. With targeted prompting, accuracy improves even further.
Our baseline benchmarks show Universal-3 Pro unprompted performance across multiple data sets. When we optimize prompts for specific data sets (providing domain context, relevant terminology, or instructions about audio characteristics), we see measurable word error rate improvements. The extent of improvement varies by use case: prompts tailored for English-Spanish code-switching improve accuracy on bilingual customer service calls, while prompts emphasizing pharmaceutical terminology reduce errors in medical transcription.
This means you can start with strong baseline accuracy and refine results through prompting, rather than requiring custom model training or extensive post-processing pipelines. The time investment in prompt engineering (typically minutes to hours) replaces what would otherwise require days or weeks of custom model development.
We recommend testing with your specific audio in our Playground to validate performance for your use case before implementation.
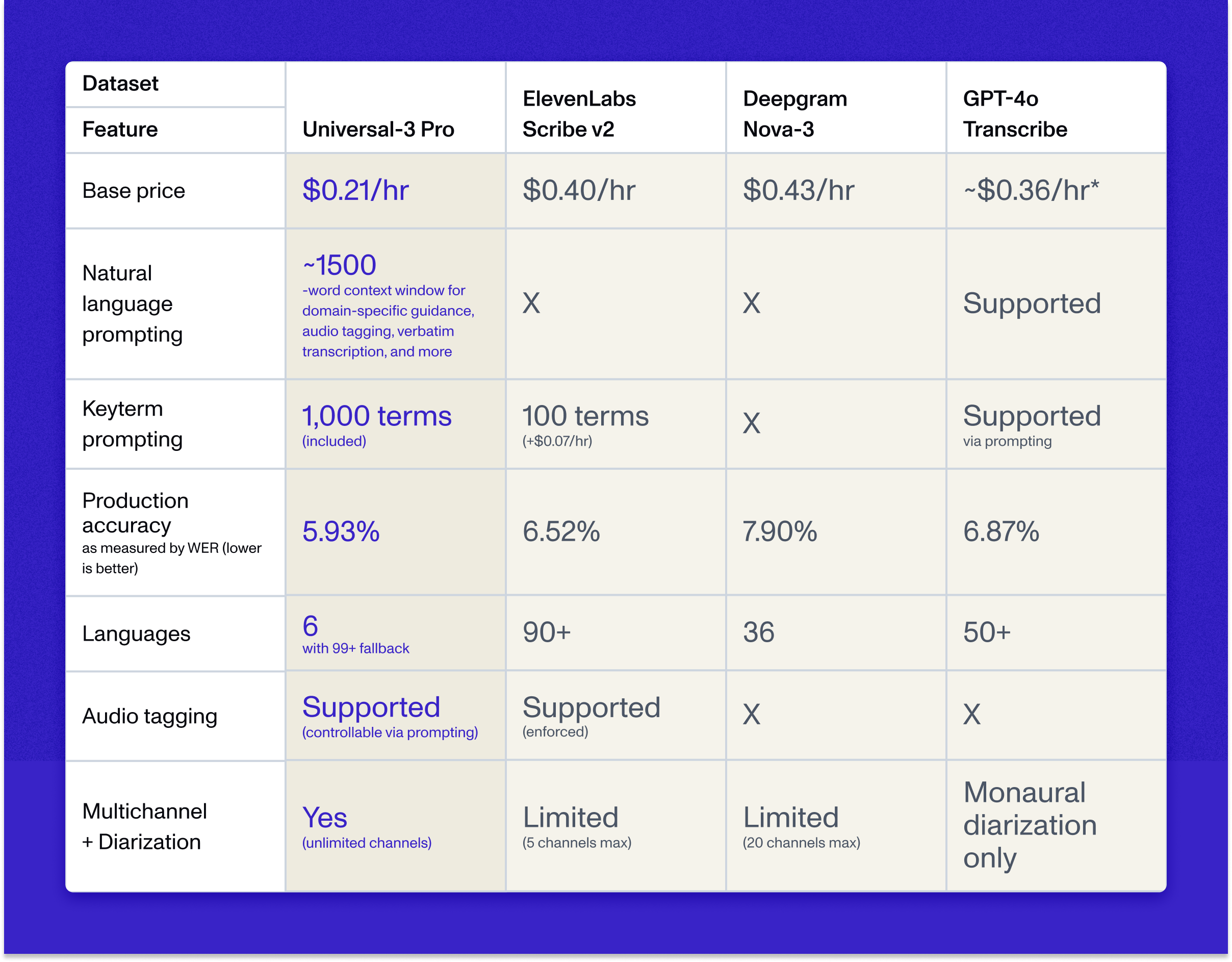
Features and pricing
Universal-3 Pro delivers superior capabilities at better price-performance than competing solutions:
Proven accuracy gains in production
Teams building on Universal-3 Pro report immediate accuracy improvements on production audio. Junior, a voice intelligence platform for M&A teams, saw measurable gains when testing Universal-3 Pro. For due diligence workflows where consultants and investors rely on expert call transcripts to inform billion-dollar decisions, accuracy improvements directly translate to better insights and reduced risk.

Jiminny, a conversation intelligence platform, highlighted improvements in handling business-critical details. When sales teams use conversation intelligence to coach reps and analyze deal cycles, accurate capture of customer names and company-specific terminology is essential for extracting actionable insights.
.png)
These improvements happen out of the box, with additional gains available through targeted prompting.
Why AssemblyAI
Voice AI infrastructure is all we do. We don't build end-user products or split focus across modalities. We're focused entirely on making it faster to build, ship, and scale products with voice data.
We've worked with hundreds of teams in this space. We’ve seen the prompts, the edge cases, and the failure modes. When you build on Universal-3 Pro, you're building on that accumulated knowledge. As we improve the model, those improvements flow to everyone.
Simple pricing, no lock-in. Volume discounts without upfront commits or rate limit negotiations. If we're not the best option for you, it's easy to switch.
Start building with Universal-3 Pro today. →
Get started in 3 ways
- Playground: Test Universal-3 Pro with your audio files. No code required
- Documentation: Review our Prompt Engineering Guide with industry-specific templates
- API: Use your existing API key. Simply update the speech_model parameter
import assemblyai as aai
aai.settings.api_key = "YOUR_API_KEY"
transcriber = aai.Transcriber()
transcript = transcriber.transcribe(
"https://assembly.ai/doctor.mov",
config=aai.TranscriptionConfig(
speech_models=["universal-3-pro", "universal-2"],
language_detection=True,
prompt="Transcribe this audio. Context: a medical consultation discussing medications and symptoms."
)
)
print(transcript.text)No rate limits, upfront commits, or vendor lock-in. Standard volume discounts apply.
Coming Soon
Additional capabilities launching in the coming months:
- Streaming Medical Mode (Beta): Real-time transcription optimized for clinical workflows
- Speech-to-Speech API (Beta): End-to-end voice transformation without text intermediaries
- Expanded language support: Additional languages
Start building with Universal-3 Pro today. →
Free February offer: Free usage valid for the month of February 2026 only, limited to 5,000 hours of Universal-3 Pro transcription. Valid credit card required to access offer. Usage beyond 5,000 hours will be billed at standard list rates. Volume-based discounts available for Universal-3 Pro—contact sales for details.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.