
Speech-to-text for healthcare developer guide
Medical speech to text for healthcare developers: compare APIs, accuracy, HIPAA, streaming, speaker separation, EHR integration, and clinical workflows.


Medical speech-to-text converts clinical conversations into accurate written documentation by handling specialized healthcare vocabulary that general speech recognition systems can't process. Unlike consumer voice apps that turn "atrial fibrillation" into "aerial vibration," medical speech recognition accurately transcribes complex drug names, procedures, and anatomical terms that appear in clinical conversations.
This specialized accuracy matters because healthcare documentation directly impacts patient safety and legal exposure. When speech recognition mishears "50 milligrams" as "15 milligrams" or confuses medication names, you're dealing with potentially dangerous errors. Medical speech-to-text systems solve these challenges through domain-optimized recognition, BAA support for processing PHI, and real-time processing capabilities designed for clinical workflows where precision on medical terminology is non-negotiable.
What is medical speech-to-text?
Medical speech-to-text is specialized software that converts clinicians' spoken words into written text, capturing complex medical terms that regular speech recognition systems miss. This means when you say "patient presents with paroxysmal atrial fibrillation," the system accurately transcribes every medical term instead of turning "atrial fibrillation" into "aerial vibration" like consumer apps would.
The technology works differently from the voice-to-text on your phone because it's optimized for medical conversations. Regular speech recognition learns from general conversations, news, and social media. Medical speech-to-text is tuned on millions of hours of clinical interactions, medical dictations, and discussions across different specialties.
Here's what makes medical speech-to-text essential for healthcare applications:
- Medical vocabulary recognition: Accurately transcribes drug names, procedures, and anatomical terms.
- Clinical context understanding: Knows that "BP" means blood pressure in a vitals discussion.
- BAA support for PHI: Lets covered entities and their business associates process protected health information under a Business Associate Addendum.
- Speaker separation: Identifies who said what in multi-party clinical conversations.
How speech recognition handles medical vocabulary
Medical conversations contain terminology that changes your transcription requirements completely. When a cardiologist discusses "three-vessel coronary artery disease requiring coronary artery bypass grafting," every single term needs perfect accuracy.
General speech recognition fails here because medical terms don't follow normal language patterns. Drug names like "acetaminophen" or "hydrochlorothiazide" aren't common words that appear in everyday speech training data. Medical abbreviations create additional complexity—"MS" could mean multiple sclerosis, mitral stenosis, or morphine sulfate depending on the clinical context.
Medical speech-to-text systems solve this by training on specialized healthcare datasets containing hundreds of thousands of medical terms, drug names, and procedural language. They learn how clinicians actually speak these terms in real settings, including regional pronunciation variations and specialty-specific abbreviations.
Medical speech recognition vs. general speech-to-text
The differences between medical and general speech-to-text affect every aspect of your transcription accuracy:
The accuracy difference isn't just about convenience—it's about patient safety. When speech recognition mishears "50 milligrams" as "15 milligrams" or confuses "Lamictal" with "Lamisil," you're dealing with potentially dangerous medication errors. AssemblyAI's Medical Mode reaches a 3.2% Missed Entity Rate (MER) on its medical benchmark—the lowest of any benchmarked provider—and catches roughly 20% fewer missed medical entities than Universal-3 Pro alone.
Core technical challenges in medical speech recognition
Building medical speech-to-text applications means solving problems that don't exist in general transcription. Understanding these challenges helps you choose the right approach for your healthcare voice application.
Medical terminology and specialized vocabulary
Medical vocabulary creates transcription challenges you won't find anywhere else. A single medication might have multiple names—brand name, generic name, and various pronunciation patterns. "Acetaminophen" gets pronounced differently by clinicians from different regions or training backgrounds.
The terminology also evolves constantly. New drugs enter the market, treatment protocols change, and medical abbreviations multiply. Your speech recognition system needs to handle this evolving vocabulary without requiring constant retraining.
Common transcription errors with general speech recognition:
- "Metformin" becomes "met for men"
- "Hydrochlorothiazide" becomes "hydro chlorine ties"
- "Paroxysmal atrial fibrillation" becomes "pair of seismic aerial vibration"
Speaker identification in clinical conversations
Clinical conversations rarely involve just one person speaking. You're dealing with clinicians, patients, nurses, family members, and other healthcare providers all in the same audio recording.
Accurate speaker diarization—knowing who said what—becomes critical for legal documentation. When a patient says "I'm not taking my medications" versus a clinician saying "You're not taking your medications?" the speaker attribution completely changes the clinical meaning.
Your system needs to handle interruptions, overlapping speech, and varying audio quality from different positions in an exam room. This is especially challenging when dealing with soft-spoken patients or clinicians who move around during examinations.
Real-time streaming for clinical workflows
Clinicians need transcription that keeps pace with natural conversation. Batch processing that waits until the end of a consultation doesn't work for clinical documentation—providers need to see their words appear as they speak.
Streaming transcription introduces trade-offs you need to understand:
- Lower latency: Faster response but potentially reduced accuracy on complex terms.
- Higher accuracy: Better transcription but delays that disrupt clinical workflow.
- Balanced approach: Optimized for medical terminology with acceptable latency.
The goal is finding the sweet spot where clinicians can speak naturally without pausing while maintaining accuracy on critical medical information.
BAA and data security requirements
Healthcare data protection requirements go far beyond basic encryption. If you're building medical speech-to-text applications, you need to understand HIPAA's specific requirements for any system handling protected health information (PHI).
Your system and your vendors should support:
- End-to-end encryption: During both transmission and storage.
- Detailed audit logs: Tracking who accessed what data when.
- Business Associate Addendums: The BAA is the contract under HIPAA between a covered entity and its business associate that governs PHI handling.
- Data residency controls: Some healthcare organizations require data to stay in specific regions.
You'll also need automatic PHI detection and redaction for scenarios where de-identified data is used for quality improvement or research purposes.
Technical requirements for medical speech recognition
Evaluating medical speech recognition APIs requires understanding specific performance metrics that directly impact clinical usability.
Accuracy and performance benchmarks
Medical speech recognition accuracy gets measured differently than general transcription. You need high accuracy specifically on clinical terminology, not just overall word recognition. The most useful metric is the Missed Entity Rate (MER): the share of medical entities—drugs, dosages, procedures, anatomy—the system fails to capture. AssemblyAI's Medical Mode reaches a 3.2% MER, the lowest across benchmarked providers. See the full benchmarks.
Here's what accuracy means in medical contexts:
- Drug names: Must achieve near-perfect accuracy to prevent medication errors.
- Dosages: Critical for patient safety; "50 mg" versus "15 mg" matters.
- Medical procedures: Accurate billing and treatment documentation depends on precise terminology.
- Anatomical terms: Essential for surgical reports and diagnostic accuracy.
Performance varies by medical specialty. Radiology reports with standardized terminology might achieve higher accuracy than psychiatry sessions with more conversational content.
Language and multilingual support
Healthcare serves diverse populations, making multilingual support essential for many medical practices. Medical Mode currently supports four languages at launch: English, Spanish, German, and French. If Medical Mode is applied to an unsupported language, the API ignores the domain parameter, returns a warning that Medical Mode was not applied, and still returns the transcript using standard transcription. English offers the most comprehensive medical terminology coverage across all specialties. Spanish, German, and French provide medical vocabulary support essential for practices serving those language populations.
EHR and clinical workflow integration
Your medical speech-to-text system needs to integrate seamlessly with existing clinical systems. This means supporting healthcare data standards, providing structured output that maps to electronic health record fields, and handling the authentication protocols that hospital IT departments require.
Common integration patterns include:
- Direct API connections: Transcribed text flows immediately into the EHR.
- Webhook-based systems: EHR gets notified when transcription completes.
- Hybrid approaches: Real-time transcription with asynchronous EHR updates.
Real-time streaming vs. batch processing
Your choice between streaming and batch processing depends on specific clinical workflows:
Real-time streaming works best for:
- Patient consultations where clinicians need immediate feedback.
- Telemedicine visits requiring live captions.
- Bedside documentation in hospital settings.
Batch processing suits:
- Dictated discharge summaries.
- Surgical reports with complex terminology.
- Quality review processes where accuracy trumps speed.
Medical speech recognition APIs and infrastructure
Three major APIs provide medical speech-to-text capabilities, each with distinct advantages for healthcare applications.
AssemblyAI
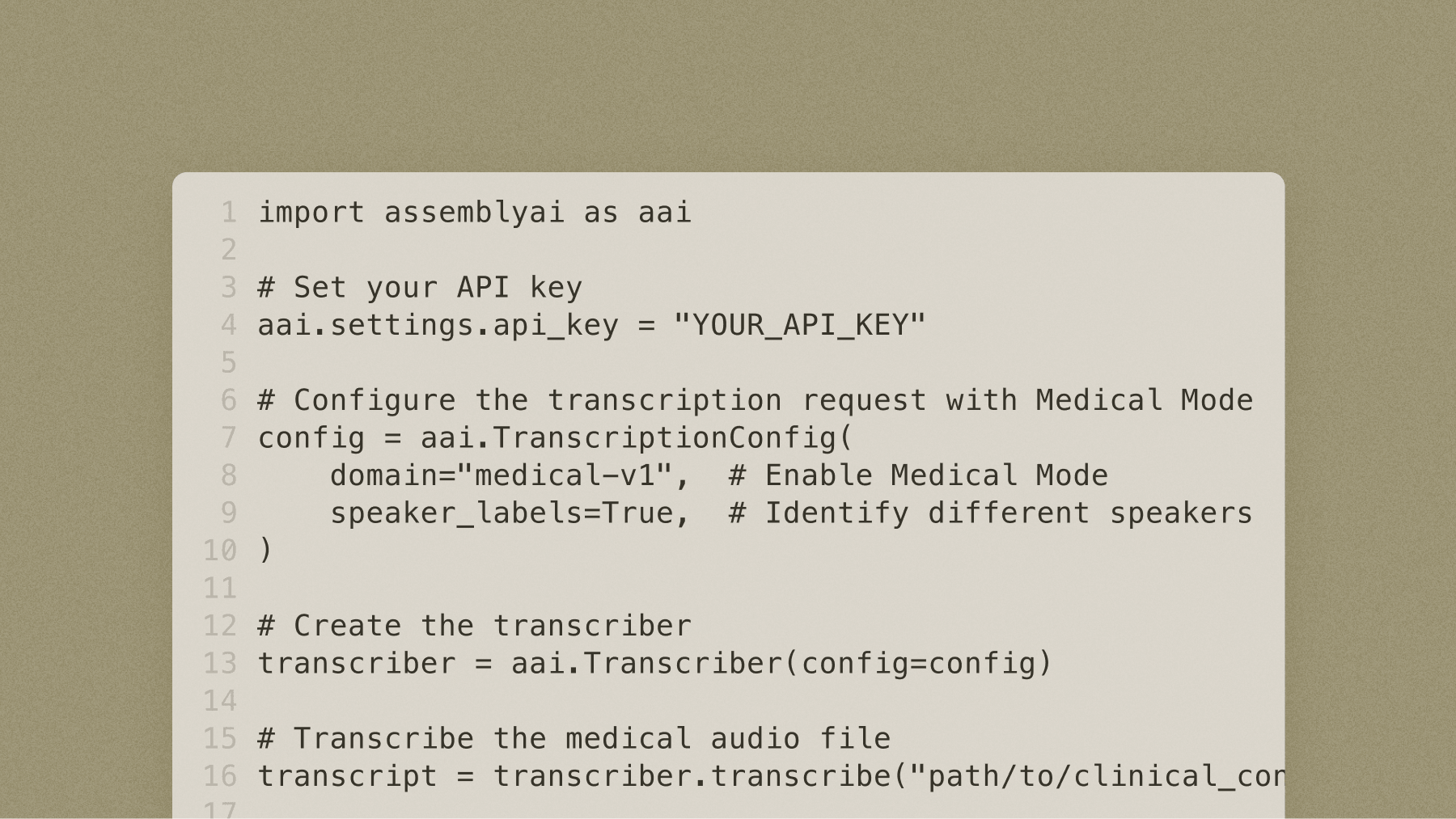
AssemblyAI's Voice AI platform provides medical speech recognition through Medical Mode, a $0.15/hr add-on. Medical Mode is domain-optimized for medical entity recognition, built on Universal-3 Pro and Universal-3 Pro Streaming. It catches terminology errors before they propagate into SOAP notes, discharge summaries, or downstream LLMs, and reaches a 3.2% Missed Entity Rate on AssemblyAI's medical benchmark. For pre-recorded audio, Universal-3 Pro with Medical Mode delivers that accuracy on clinical terminology. For real-time applications, Universal-3 Pro Streaming with Medical Mode provides the same accuracy gains with under 300ms latency, without requiring manual dictionary training or maintenance. Pricing is straightforward: Universal-3 Pro is $0.21/hr, and Universal-3 Pro plus Medical Mode is $0.36/hr.
To enable Medical Mode, set the domain parameter to "medical-v1" in your transcription request. Here's a complete streaming example in JavaScript:
npm install ws mic
const WebSocket = require("ws");
const mic = require("mic");
const querystring = require("querystring");
// --- Configuration ---
const YOUR_API_KEY = "YOUR-API-KEY"; // Replace with your actual API key
const CONNECTION_PARAMS = {
sample_rate: 16000,
speech_model: "u3-rt-pro",
domain: "medical-v1",
};
const API_ENDPOINT_BASE_URL = "wss://streaming.assemblyai.com/v3/ws";
const API_ENDPOINT = `${API_ENDPOINT_BASE_URL}?${querystring.stringify(CONNECTION_PARAMS)}`;
// Audio Configuration
const SAMPLE_RATE = CONNECTION_PARAMS.sample_rate;
const CHANNELS = 1;
// Global variables
let micInstance = null;
let micInputStream = null;
let ws = null;
let stopRequested = false;
// --- Helper functions ---
function formatTimestamp(timestamp) {
return new Date(timestamp * 1000).toISOString();
}
// --- Main function ---
async function run() {
console.log("Starting AssemblyAI real-time transcription...");
ws = new WebSocket(API_ENDPOINT, {
headers: {
Authorization: YOUR_API_KEY,
},
});
ws.on("open", () => {
console.log("WebSocket connection opened.");
console.log(`Connected to: ${API_ENDPOINT}`);
startMicrophone();
});
ws.on("message", (message) => {
try {
const data = JSON.parse(message);
const msgType = data.type;
if (msgType === "Begin") {
const sessionId = data.id;
const expiresAt = data.expires_at;
console.log(
`\nSession began: ID=${sessionId}, ExpiresAt=${formatTimestamp(expiresAt)}`
);
} else if (msgType === "Turn") {
const transcript = data.transcript || "";
const formatted = data.turn_is_formatted;
if (formatted) {
process.stdout.write("\r" + " ".repeat(100) + "\r");
console.log(transcript);
} else {
process.stdout.write(`\r${transcript}`);
}
} else if (msgType === "Termination") {
const audioDuration = data.audio_duration_seconds;
const sessionDuration = data.session_duration_seconds;
console.log(
`\nSession Terminated: Audio Duration=${audioDuration}s, Session Duration=${sessionDuration}s`
);
}
} catch (error) {
console.error(`\nError handling message: ${error}`);
console.error(`Message data: ${message}`);
}
});
ws.on("error", (error) => {
console.error(`\nWebSocket Error: ${error}`);
cleanup();
});
ws.on("close", (code, reason) => {
console.log(`\nWebSocket Disconnected: Status=${code}, Msg=${reason}`);
cleanup();
});
setupTerminationHandlers();
}
function startMicrophone() {
try {
micInstance = mic({
rate: SAMPLE_RATE.toString(),
channels: CHANNELS.toString(),
debug: false,
exitOnSilence: 6,
});
micInputStream = micInstance.getAudioStream();
micInputStream.on("data", (data) => {
if (ws && ws.readyState === WebSocket.OPEN && !stopRequested) {
ws.send(data);
}
});
micInputStream.on("error", (err) => {
console.error(`Microphone Error: ${err}`);
cleanup();
});
micInstance.start();
console.log("Microphone stream opened successfully.");
console.log("Speak into your microphone. Press Ctrl+C to stop.");
} catch (error) {
console.error(`Error opening microphone stream: ${error}`);
cleanup();
}
}
function cleanup() {
stopRequested = true;
if (micInstance) {
try {
micInstance.stop();
} catch (error) {
console.error(`Error stopping microphone: ${error}`);
}
micInstance = null;
}
if (ws && [WebSocket.OPEN, WebSocket.CONNECTING].includes(ws.readyState)) {
try {
if (ws.readyState === WebSocket.OPEN) {
const terminateMessage = { type: "Terminate" };
console.log(
`Sending termination message: ${JSON.stringify(terminateMessage)}`
);
ws.send(JSON.stringify(terminateMessage));
}
ws.close();
} catch (error) {
console.error(`Error closing WebSocket: ${error}`);
}
ws = null;
}
console.log("Cleanup complete.");
}
function setupTerminationHandlers() {
process.on("SIGINT", () => {
console.log("\nCtrl+C received. Stopping...");
cleanup();
setTimeout(() => process.exit(0), 1000);
});
process.on("SIGTERM", () => {
console.log("\nTermination signal received. Stopping...");
cleanup();
setTimeout(() => process.exit(0), 1000);
});
process.on("uncaughtException", (error) => {
console.error(`\nUncaught exception: ${error}`);
cleanup();
setTimeout(() => process.exit(1), 1000);
});
}
// Start the application
run();
The platform includes automatic speaker diarization for multi-party clinical conversations, essential for capturing interactions between providers, patients, and others accurately. AssemblyAI enables covered entities and their business associates subject to HIPAA to use AssemblyAI services to process protected health information (PHI). AssemblyAI is considered a business associate under HIPAA and offers a Business Associate Addendum (BAA) required under HIPAA.
AWS Transcribe Medical
Amazon's medical transcription service provides speech recognition with built-in medical vocabulary for primary care and specialty fields. The service supports both real-time streaming and batch processing with automatic punctuation and formatting for clinical notes.
AWS Transcribe Medical integrates well with other AWS services, making it convenient for organizations already using AWS infrastructure. The API includes medical entity detection for identifying conditions, medications, and treatments within transcribed text. However, it currently only supports English, limiting its use in multilingual healthcare settings. On AssemblyAI's medical benchmark, AWS Transcribe Medical sits around a 24.4% Missed Entity Rate.
Deepgram
Deepgram offers medical and general-purpose speech recognition, including a Nova-3 Medical model targeted at healthcare use cases. Deepgram's streaming capabilities and custom vocabulary features allow healthcare organizations to build specialized transcription systems, and its Nova-3 Medical model provides healthcare-oriented vocabulary coverage. On AssemblyAI's medical benchmark, Nova-3 Medical sits around an 8.7% Missed Entity Rate.
Implementation patterns and examples
Real-world medical speech-to-text implementations follow proven patterns that balance accuracy, speed, and clinical usability.
Clinical documentation automation
Automated clinical documentation transforms how clinicians create patient notes. Instead of spending 15 to 20 minutes typing after each visit, providers speak naturally while the system generates structured clinical notes.
Successful implementations handle common clinical scenarios:
- Interruptions: When nurses enter the room during documentation.
- Context switching: Distinguishing between clinical observations and casual conversation.
- Structured formatting: Automatically organizing content into SOAP note format.
The key is understanding that clinical documentation isn't just transcription—it's about capturing medically relevant information in formats that integrate with existing clinical workflows.
EHR integration architectures
Effective EHR integration requires careful architectural planning to ensure reliable, secure data flow. The most common pattern uses middleware that receives transcribed text from the speech recognition API, applies formatting rules specific to the healthcare organization, and pushes structured data into the EHR.
Real-time architectures stream transcribed text directly into draft notes that clinicians can review and edit while still with the patient. Asynchronous patterns allow providers to dictate notes between visits, with transcription processing in the background and notifications when notes are ready for review.
Final words
Medical speech-to-text converts clinical conversations into accurate documentation by handling specialized medical vocabulary that general speech recognition can't process. The technology combines domain-optimized recognition, BAA support for processing PHI, and real-time processing capabilities to fit seamlessly into clinical workflows where accuracy on drug names and dosages directly impacts patient safety.
The technical foundation matters because healthcare can't compromise on accuracy or security. AssemblyAI's Voice AI platform addresses these requirements through Medical Mode for clinical terminology accuracy—a 3.2% Missed Entity Rate, the lowest of any benchmarked provider—streaming transcription for real-time workflows, speaker diarization for multi-party clinical conversations, and BAA availability for processing PHI. This specialized infrastructure transforms complex medical conversations into reliable, structured documentation that integrates with existing healthcare systems.
Frequently asked questions
How accurate is medical speech-to-text with drug names and medical terminology?
The right metric is the Missed Entity Rate (MER), which measures the share of medical entities the system fails to capture. AssemblyAI's Medical Mode reaches a 3.2% MER on its medical benchmark—the lowest of any benchmarked provider—and catches roughly 20% fewer missed entities than Universal-3 Pro alone.
How does AssemblyAI Medical Mode compare to Deepgram Nova-3 Medical, Amazon Transcribe Medical, and Whisper?
On AssemblyAI's medical benchmark, Medical Mode reaches a 3.2% MER, the lowest across benchmarked providers. Deepgram Nova-3 Medical sits around 8.7% MER and Amazon Transcribe Medical around 24.4% MER. General-purpose models like Whisper aren't tuned for medical entities and miss substantially more clinical terms. See the full benchmarks.
What makes medical speech-to-text different from regular voice transcription apps?
Medical speech-to-text includes domain-optimized recognition of healthcare vocabularies, BAA support for processing PHI, clinical context understanding, and medical entity recognition, while regular apps lack medical terminology coverage and the contractual safeguards healthcare requires.
How do I handle PHI and HIPAA obligations when using medical speech-to-text APIs?
Select vendors that offer a Business Associate Addendum (BAA). AssemblyAI enables covered entities and their business associates subject to HIPAA to use AssemblyAI services to process PHI; AssemblyAI is considered a business associate under HIPAA and offers a BAA required under HIPAA. Pair that with end-to-end encryption, detailed audit logs, and PII/PHI redaction.
Can medical speech-to-text work in real-time during patient consultations?
Yes. Universal-3 Pro Streaming with Medical Mode supports real-time streaming with under 300ms latency, enabling live clinical documentation during encounters without disrupting workflow.
Does medical speech-to-text separate different speakers in clinical conversations?
Modern medical speech recognition includes speaker diarization that accurately separates and labels different speakers, essential for distinguishing between clinician and patient statements in medical documentation.
Which programming languages can I use to integrate medical speech-to-text APIs?
Most medical speech-to-text APIs provide SDKs for popular languages including Python, JavaScript, Java, and C#, with RESTful APIs supporting any language that can make HTTP requests.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
