
Streaming diarization just got a major upgrade
Real-time apps live or die on speaker attribution. Our streaming diarization upgrade fixes it at the source and leads the competition on production metrics.



Real-time application live or die on whether they can keep track of who's talking. When diarization fails, the LLM gets bad inputs. Wrong speakers attributed to wrong words. Phantom turns from speakers who don't exist. Real turns missed entirely. A notetaker stitches two people's comments into one. A live caption credits the wrong speaker on screen. An agent-assist tool coaches a sales rep based on words the customer never said.
Today we're shipping a major upgrade to streaming diarization that fixes this at the source, and pulls us decisively ahead of the competition on the metrics that matter in production.
Why diarization is the quiet killer
Speaker attribution is the layer that decides whether the words your model gets right actually reach your application correctly labeled. Get it wrong and the downstream cost compounds: a meeting summary names the wrong person making a commitment, a captioning system misattributes a quote that ends up in a transcript record, an LLM responds to a prompt that was never spoken.
Our recent voice agent report surveyed 455 builders shipping production voice applications. 55% said having to repeat themselves was their users' #1 frustration. Another 47.5% pointed to systems interrupting users mid-sentence. Both of these are as much diarization problems as they are STT or turn-detection problems. When the diarization hallucinates a second speaker mid-utterance, turn logic fires early and the system cuts the user off. When it misses a real speaker change in a multi-party call, two people's words get fused into one input.
This release is about closing that gap, whether you're building an AI notetaker, a live captioning service, an agent-assist tool, a contact center analytics platform, or any other real-time pipeline where knowing who said what actually matters.
What's new
Sharper detection, fewer hallucinations. Compared to our previous diarization model with Universal-3 Pro, this update delivers:
- 66% reduction in false-alarm speakers
- 60% reduction in phantom turn rate
- 12% relative cpWER improvement overall, with 24% relative improvement on 2-speaker audio
Universal-3 Pro outperforms the competition. On head-to-head benchmarks when compared to Deepgram Nova-3:
- 2x better cpWER on 2-speaker telephony
- 13% better cpWER on 4-speaker meetings
- 42% fewer false alarm speakers
- 91% fewer phantom turns and words attributed to speakers who don't exist
For a notetaker capturing a board meeting, that 91% reduction in phantom-speaker words is the difference between a clean transcript and one your customers have to hand-correct before sharing. For an agent-assist tool listening to a sales call, it's the difference between coaching prompts based on what the customer actually said and prompts generated from words the customer never spoke.
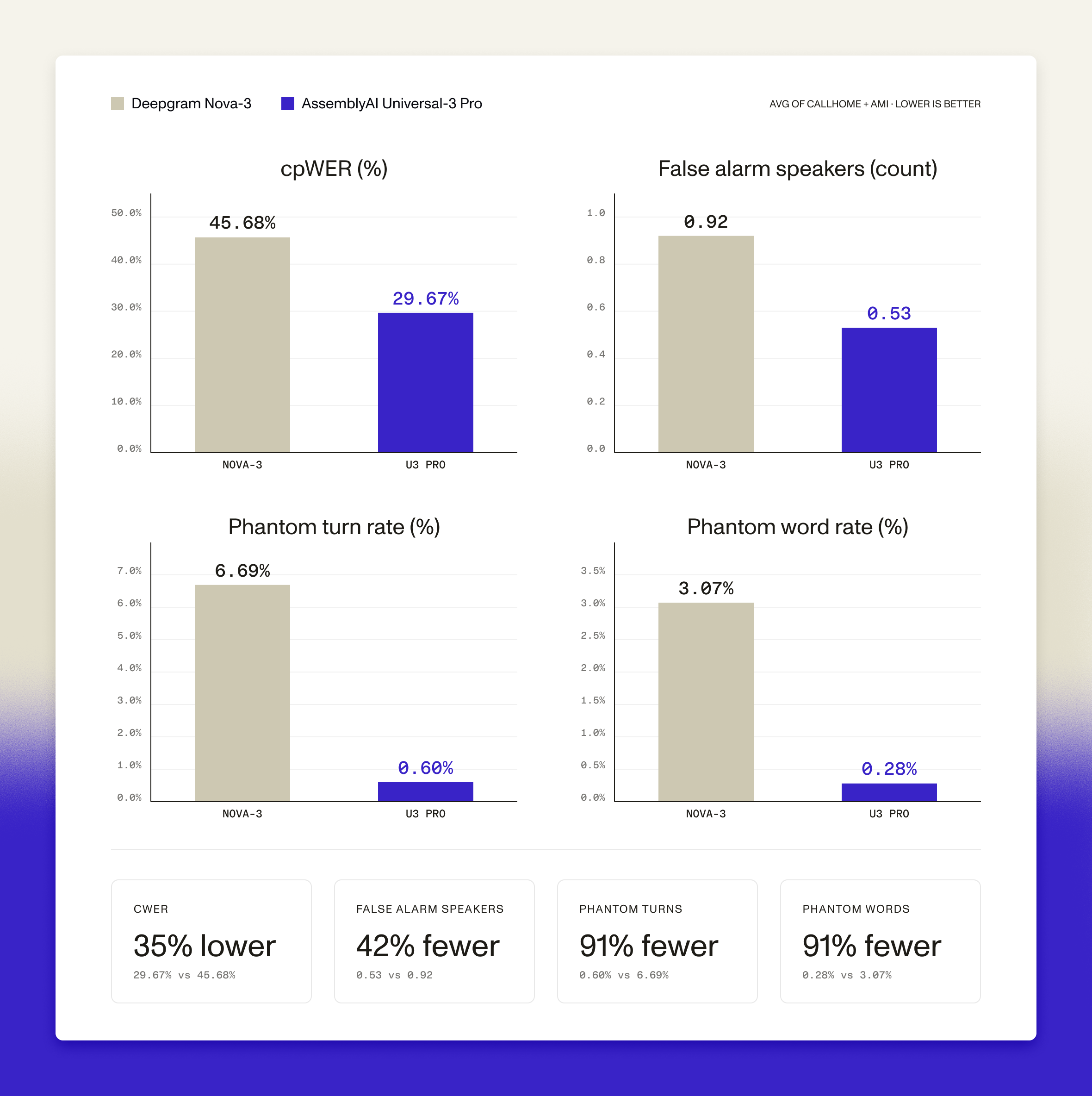
In addition to the Universal-3 Pro Streaming diarization improvements, Universal-Streaming also pulls ahead of Deepgram Nova-3, with 51% fewer false-alarm speakers, 80% fewer phantom turns, 82% fewer phantom words attributed to speakers who don't exist, and 11% better cpWER on average.
Hear the difference
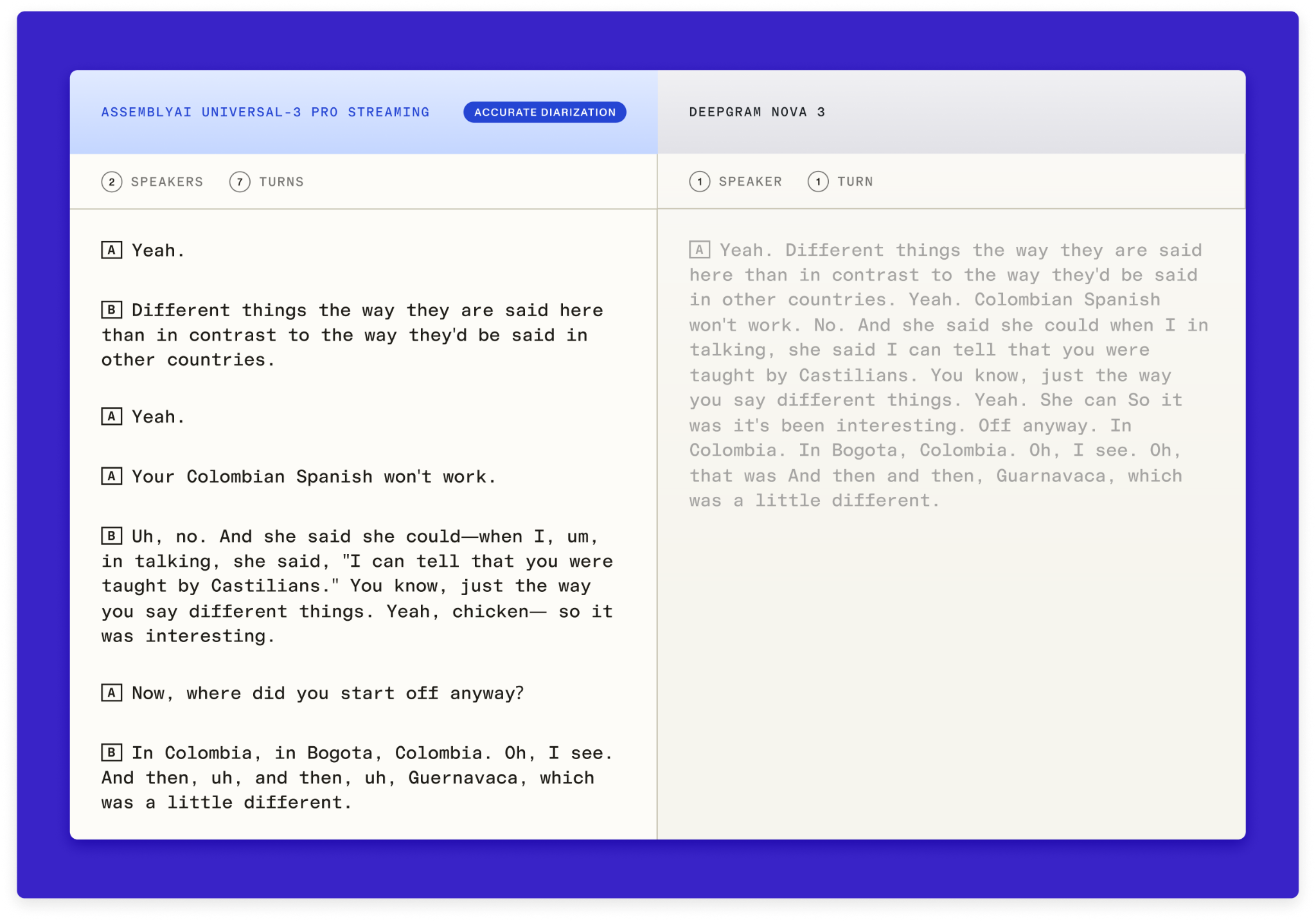
Benchmarks tell you the aggregate story. Audio tells you what your users would actually experience.
Below is the same call run through Deepgram’s diarization model and the AssemblyAI diarization model, side by side. See where their output stitches two people's words into a single turn, entirely missing the second speaker. These are the failures that send your agent down the wrong branch of a conversation, and they're the kind of thing that doesn't show up cleanly in a cpWER number but absolutely shows up in your support tickets.

A small but important API change
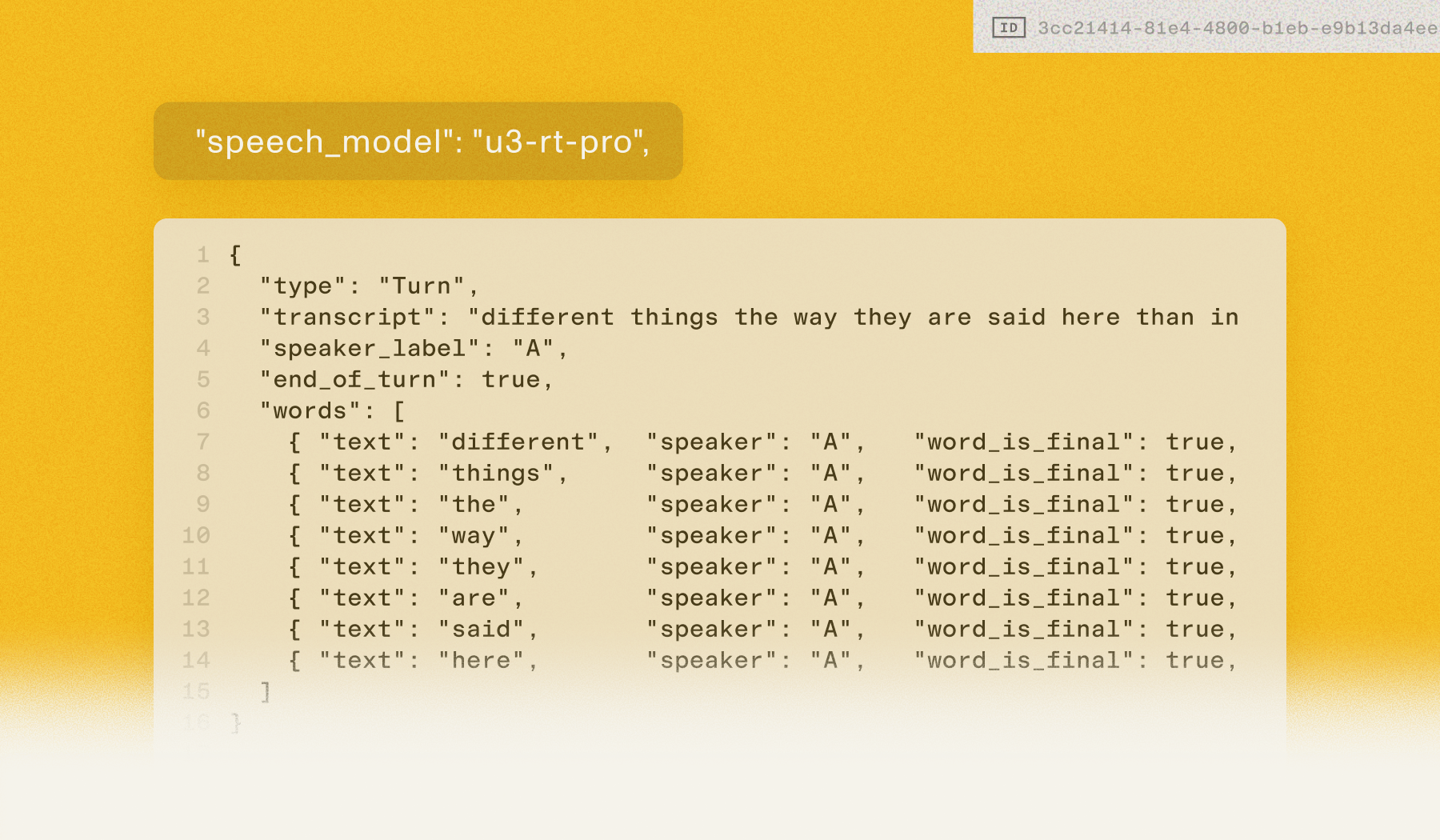
To get the most out of these gains, we're updating the customer-facing API. Each word object inside a turn now carries its own speaker label, rather than inheriting a single label from the parent turn. This unlocks much more refined mid-turn speaker change detection. When one speaker interjects into another's turn, you'll see it at the word level instead of waiting for the next turn boundary. See the example in the thread below.
For builders, this means cleaner inputs to your LLM, more accurate meeting transcripts, and fewer captions credited to the wrong speaker.
The bigger picture
The voice agent report's core conclusion was that the teams winning aren't the ones with the biggest budgets. They're the ones who solved the foundational accuracy problems first. Diarization sits at that foundation. Get it wrong and every downstream layer (LLM, TTS, business logic) inherits the error. Get it right and your application actually feels like, in the words of one builder we surveyed, "a competent, patient human who actually listens."
This release is live today on streaming. Docs and the updated API spec are linked below.
Read the docs ->
Get started now ->
Frequently asked questions
What are phantom turns and false-alarm speakers in streaming diarization?
Phantom turns occur when the diarization model invents speaker changes that didn't happen — splitting one person's speech into two speakers or inserting turn boundaries mid-sentence. False-alarm speakers are entirely hallucinated speakers who don't exist in the audio. Both produce bad inputs for downstream systems: an LLM responds to a prompt that was never spoken, a voice agent cuts a user off because fabricated speaker changes triggered turn logic early, or a meeting summary attributes a commitment to the wrong person.
How does AssemblyAI's streaming diarization compare to Deepgram Nova-3?
On head-to-head benchmarks, AssemblyAI delivers 2x better cpWER on 2-speaker telephony, 13% better cpWER on 4-speaker meetings, 42% fewer false-alarm speakers, and 91% fewer phantom turns and misattributed words compared to Deepgram Nova-3. These gaps matter most in production — a contact center analytics platform processing thousands of calls or an AI notetaker generating shareable transcripts needs speaker attribution that's reliable at scale, not just accurate on clean benchmarks.
What are word-level speaker labels and why do they matter?
Word-level speaker labels mean each word object in a streaming turn now carries its own speaker assignment, rather than inheriting a single label from the parent turn. This enables mid-turn speaker change detection — when one person interjects into another's sentence, the label changes at the exact word boundary instead of waiting for the next turn. For builders, this translates to cleaner inputs for your LLM, more accurate meeting transcripts, and fewer captions credited to the wrong speaker in live captioning systems.
Which real-time applications benefit most from improved streaming diarization?
Any application where knowing who said what during a conversation (not after) drives the core experience. AI notetakers get clean transcripts that don't require hand-correction before sharing. Live captioning systems attribute quotes to the correct speaker on screen. Agent-assist tools fire coaching prompts based on what the customer actually said. Voice agents stop cutting users off mid-sentence because fewer hallucinated speaker changes trigger turn logic early. And contact center analytics platforms get reliable inputs for downstream LLM analysis.
How does diarization accuracy affect voice agents and downstream AI systems?
Speaker diarization sits at the foundation of the real-time speech pipeline — when it fails, every downstream layer inherits the error. A misattributed speaker change can cause a voice agent's turn detection to fire early, an LLM to generate a response to something the wrong person said, or a TTS system to speak over the user. AssemblyAI's 2026 voice agent report found that 55% of builders cited users having to repeat themselves as their top frustration, a problem that's as much about diarization as it is about transcription accuracy.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts