
LLM Gateway: The easiest and most reliable way to call multiple LLMs
Today we're relaunching LLM Gateway with automatic fallbacks, real-time streaming with tool calling, structured outputs, prompt caching, and new models from Qwen and Moonshot. All through a single OpenAI-compatible endpoint, with zero markup on provider costs.


Today we're relaunching LLM Gateway with automatic fallbacks, real-time streaming with tool calling, structured outputs, prompt caching, and new models from Qwen and Moonshot. All through a single OpenAI-compatible endpoint, with zero markup on provider costs.
It's the easiest and most reliable way to call multiple LLMs from one place, with the same AssemblyAI API key you already have.
Why we built it differently
Most developers calling LLMs in production juggle three or four providers, which means multiple accounts, bills, error codes, and rate limits, plus more chances of an outage taking your product down. Existing gateways are supposed to fix that, but they add fees on every request, latency to Voice AI workflows, and another security opening.
LLM Gateway is built differently. Zero markup on provider costs, minimal dependencies, and infrastructure that runs alongside AssemblyAI's STT to remove a network hop for any developer building on speech. Available in both US and EU regions, with an EU endpoint that keeps your data inside the European Union.
What's new
A curated catalog across four providers
Two new model families are now live: Qwen 3 and Kimi K2.5 from Moonshot AI, both running on Baseten. They join 20+ production-quality models across Anthropic, OpenAI, Google, and Baseten, all through a single endpoint.
We curate the catalog instead of dumping every model into it, and we ship new releases the same day they drop. If you need a model we don't have yet, send us a request and we'll usually get it added within a few days.
Automatic fallbacks across providers
We'd never accept a transcription API that dropped 2% of requests during peak hours, so it's strange that the industry has accepted it from LLM providers for this long.
If your primary model returns an error or exceeds a latency threshold you set, the request reroutes to a fallback automatically with the same schema and the same response format, no client-side retry logic required. Your users never see the outage, and unlike OpenRouter's fallback routing (which adds about 15ms of overhead) ours adds none.
A single provider is a single point of failure. A gateway with fallbacks is a reliability layer that you don't have to build yourself.
Streaming responses in real time
Streamed responses are now live for GPT-5-nano, Kimi K2.5, and the Qwen models, with more coming soon.
Streaming matters anywhere you want to show output as it's generated instead of making the user wait for the full response: chat interfaces, summarization that runs as a transcript comes in, and any real-time pipeline where time-to-first-token is what the end user actually experiences.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_ASSEMBLYAI_KEY",
base_url="https://llm-gateway.assemblyai.com/v1"
)
stream = client.chat.completions.create(
model="openai/gpt-5-nano",
messages=[{"role": "user", "content": "Summarize this transcript."}],
stream=True
)
for chunk in stream:
print(chunk.choices[0].delta.content, end="")Same OpenAI SDK with the same code you'd write against any provider. The only difference is the base URL.
Call tools while streaming
Tool calling now works with streamed responses. Your application can invoke functions like database lookups, API calls, or CRM updates as the model generates, without waiting for the full response. For more complex flows, the gateway supports automatic tool chaining across multiple steps so the model can reason through a sequence of actions without you orchestrating each call.
For voice agents, this is how you get real-time actions: a customer says "check my order status" and the agent calls your fulfillment API mid-turn, then speaks the result. No post-processing step. No second request.
response = client.chat.completions.create(
model="openai/gpt-5-nano",
messages=[{"role": "user", "content": "What's the status of order #4821?"}],
tools=[{
"type": "function",
"function": {
"name": "get_order_status",
"description": "Look up an order by ID",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string"}
},
"required": ["order_id"]
}
}
}],
stream=True
)
Get structured JSON from Claude models
Structured outputs are now supported for Claude 4.5 and later models. Request a JSON schema and get typed responses back, with no prompt engineering required to coax the model into valid JSON and no post-processing required to fix malformed output.
This is useful for any workflow where you need reliable structure: extracting entities from a transcript, classifying intent, generating structured clinical notes from a medical conversation. The schema goes in, valid JSON comes out, and your downstream code can rely on the shape.
Prompt caching across providers
Prompt caching is implicit for GPT and Gemini models and explicit via cache_control for Anthropic. For any application that re-sends a long system prompt on every request, this drops both cost and time-to-first-token in a way that's immediately visible in the latency numbers.
How LLM Gateway compares
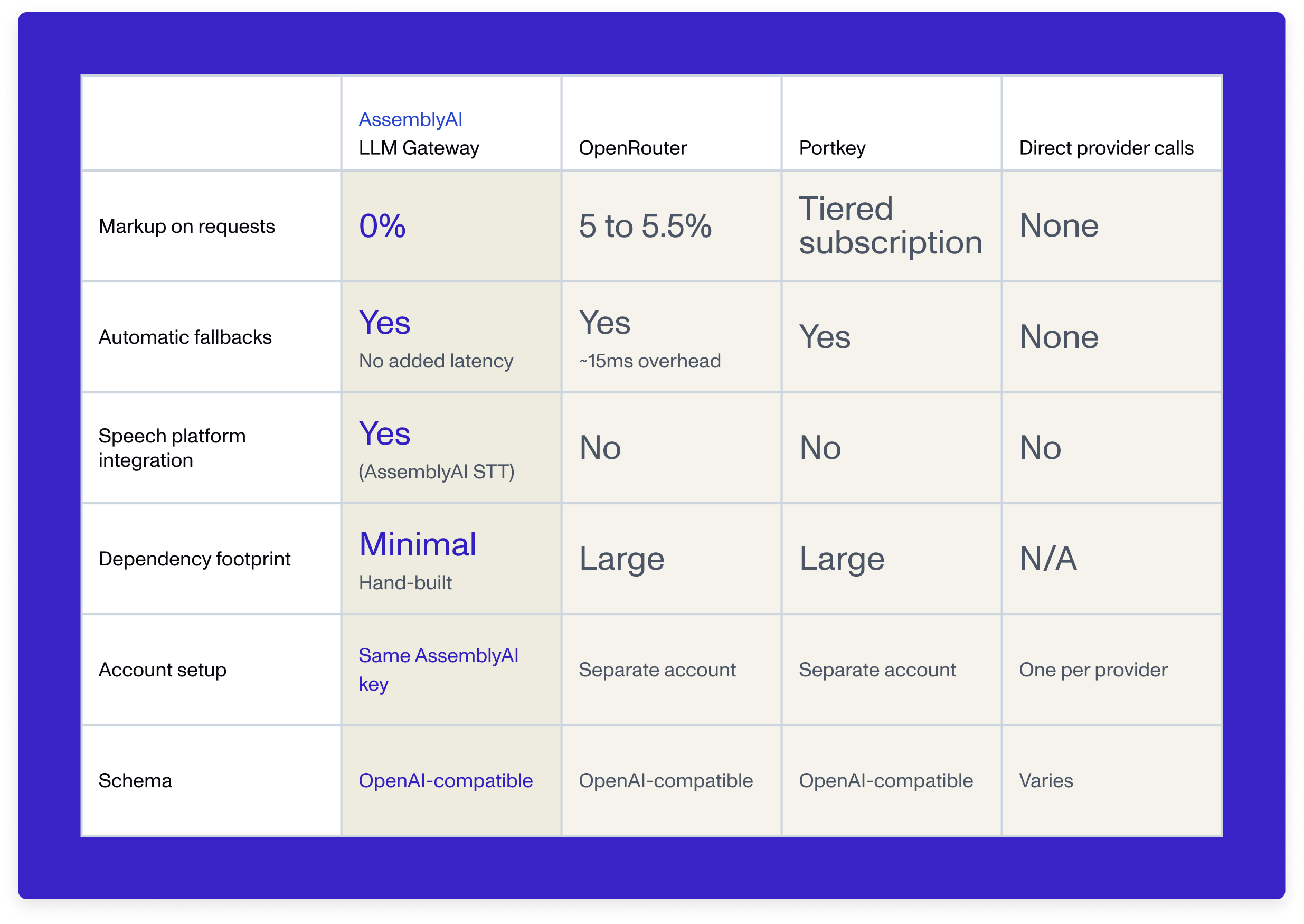
We're the only major LLM gateway that passes through provider costs with no fee on top. We're also the only one built with minimal, hand-written integrations instead of large third-party proxy libraries, which means a much smaller attack surface and no exposure to dependency-chain vulnerabilities.
Built into the same infrastructure as your STT
If you're building on AssemblyAI's STT, LLM Gateway is the only way to call an LLM on every utterance without leaving our infrastructure. No extra network hop, no separate billing relationship, no second SDK to manage. Run tool calls, intent classification, or summarization on the transcript stream with the lowest possible latency, and the whole pipeline lives in one system with one API key and one bill. No standalone gateway can offer this.
Get started
LLM Gateway is OpenAI-compatible. Point your existing code at the gateway, pick a model, and start building.
Frequently asked questions
How do automatic fallbacks work in LLM Gateway?
When your primary model returns an error or exceeds a latency threshold, LLM Gateway automatically reroutes the request to a fallback model you've configured — same schema, same response format, no client-side retry logic required. You define fallback depth, retry behavior, and per-fallback overrides (model, provider, temperature, or prompt), so your application stays up even when an individual provider doesn't. This is particularly important for voice agent workflows where a single dropped LLM call breaks the entire conversation.
Does LLM Gateway support streaming responses with tool calling?
Yes — LLM Gateway now supports streamed responses with tool calling for models including GPT-5-nano, Kimi K2.5, and Qwen 3. In a voice agent pipeline, streaming means TTS can start speaking before the LLM finishes generating, and tool calling lets the agent invoke functions mid-turn — database lookups, API calls, CRM updates — without waiting for the full response. This combination is what makes the difference between a conversation that feels natural and one that feels like being on hold.
How does LLM Gateway pricing compare to OpenRouter and other LLM gateways?
LLM Gateway charges 0% markup on top of provider model costs — you pay the exact per-token rate from the underlying provider with no additional fee. OpenRouter charges 5–5.5% on every request, and llmgateway.io charges 5%. Combined with unified billing through your existing AssemblyAI account and no separate signup required, this makes LLM Gateway the lowest-cost way to route across multiple LLM providers from a single endpoint. See current per-model rates on the pricing page.
Can I use LLM Gateway inside a real-time voice agent pipeline?
Yes, and this is where LLM Gateway offers something standalone gateways can't. Because it runs inside AssemblyAI's infrastructure alongside Streaming Speech-to-Text, there's no extra network hop when routing an LLM call on each utterance — speech to LLM to action happens in a single system with minimal latency. Developers building STT → LLM → TTS pipelines get the lowest possible end-to-end latency, while standalone gateways like OpenRouter add an external hop on every request.
What models does LLM Gateway support and how quickly are new models added?
LLM Gateway currently supports 20+ production-quality models across Anthropic (Claude Sonnet, Opus, Haiku), OpenAI (GPT-5, GPT-5-nano, GPT-4.1), Google (Gemini 2.5 Flash, Gemini 3 Flash), and newer additions like Qwen 3 and Kimi K2.5 from Moonshot AI. New models are added within days of request — the catalog is curated for quality rather than breadth, focusing on models that work well for voice AI and transcript analysis workloads. The full model list is in the developer docs.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts

