
Universal-3 Pro Streaming: The most accurate real-time transcription model for voice agents
Today we're releasing Universal-3 Pro Streaming, bringing every capability from Universal-3 Pro to real-time transcription: prompting, keyterm prompting,disfluency control, and code-switching. Plus two capabilities new to streaming: real-time speaker diarization and 99+ language support.



A collections platform is seeing agents return both "trade" and "homeowner" when only one was spoken. A major booking company is losing reservations because conversations get cut off before customers finish their sentence. A customer service platform had to disable end-of-speech detection entirely because their model kept generating words that were never spoken.
These aren't edge cases. And the failures aren't random — they cluster around the same problems: credit card numbers, policy IDs, alphanumeric codes, and the moment a customer pauses mid-thought. The problem isn't just accuracy. It's that voice agent failures cascade. You can't fix these problems in post-processing. The customer is already gone.
Today we're releasing Universal-3 Pro Streaming, bringing every capability from Universal-3 Pro to real-time transcription: prompting, keyterm prompting, disfluency control, and code-switching. Plus two capabilities new to streaming: real-time speaker diarization and 99+ language support.
If you're already building with Universal-Streaming, you can get Universal-3 Pro's promptable accuracy in the same pipeline. One line change, no architectural rework.
Universal-3 Pro capabilities, now in real time
Universal-3 Pro changed how developers work with speech by making the model promptable. Give it context upfront (domain vocabulary, speaker roles, formatting instructions) and it gets the transcript right at the source. All of that now works in real time.
Keyterm prompting. Domain-specific terms fail at 3–5x higher rates than general speech in off-the-shelf models. Product names, medication names, internal jargon: the terms that matter most are exactly where accuracy breaks down. Feed the model up to 1,000 words of domain vocabulary and it applies corrections as audio arrives. "Aetna Whole Life Select" gets captured correctly. "Metoprolol succinate" doesn't become something else entirely.
Disfluency control. "I agree" and "I, uh, I guess I agree" carry different evidentiary weight in a legal record. For compliance workflows, prompt for verbatim. For customer-facing summaries, prompt for clean output. Same stream, different instructions.
Code-switching. Bilingual customer service calls don't pause mid-sentence for the transcription model to catch up. Native support for English, Spanish, German, French, Portuguese, and Italian handles real-world language mixing as it happens.
.png)
Fixing turn-taking and conversation flow
The voice AI industry called turn-taking "still unsolved" at recent industry meetups. Production teams consistently report conversations getting cut off before customers finish, breaking natural flow and making interactions feel mechanical.
Universal-3 Pro Streaming handles short utterances and single-word acknowledgments ("yes," "mmhmm," "okay") without breaking diarization or cutting off longer thoughts. The streaming endpoint includes guardrails that prevent text output faster than average speaking pace, addressing the repetition and hallucination issues that plague production deployments.
When a customer speaks, it gets captured completely. When they pause mid-thought, the system waits. When they're done, it responds. That's how conversations should work.

New: Real-time streaming diarization
Misattributing speech to the wrong speaker isn't just an accuracy problem; it's a compliance problem. In a recorded sales call, agent and customer utterances carry different legal weight. In a medical consultation, what the doctor said versus what the patient said determines the record. In a contact center, wrong attribution breaks QA scoring, coaching workflows, and dispute resolution.
For voice agents, the stakes go further. Diarization errors don't stay contained; they cascade. A misattributed turn produces a wrong intent, which triggers a wrong tool call, which takes a wrong action. The further downstream the error travels, the harder it is to recover.
Universal-3 Pro Streaming tracks speaker turns inline, at streaming speed, with native turn detection built directly into the transcript. The model understands when a speaker is done based on how they speak: tonality, pacing, speech patterns, not just silence. This means cleaner handoffs, more accurate intent signals, and fewer cascade failures in production agent pipelines. For teams building on LiveKit or Pipecat, this makes for the most reliable turn detection available.
Prompt speaker roles directly into your session and labels arrive with the transcript as it's generated. No post-processing, no separate pipeline.

Now in beta: Prompting for increased accuracy
Conversations evolve. A support call that starts with account verification moves into troubleshooting, then escalates to technical diagnostics. Each phase has different terminology that matters.
Universal-3 Pro Streaming supports prompting mid-session. With our default prompt, out-of-the-box performance is industry-leading and accurate for most use cases, but prompting can take transcription quality to the next level.
Update your model prompt in real time over WebSocket as the conversation progresses without dropping the connection or restarting the session. Adapt accuracy to context as it unfolds, not just at the start of a call. Check out our comprehensive prompting guide for example prompts, best practices, and how to optimize your prompts for the best results.
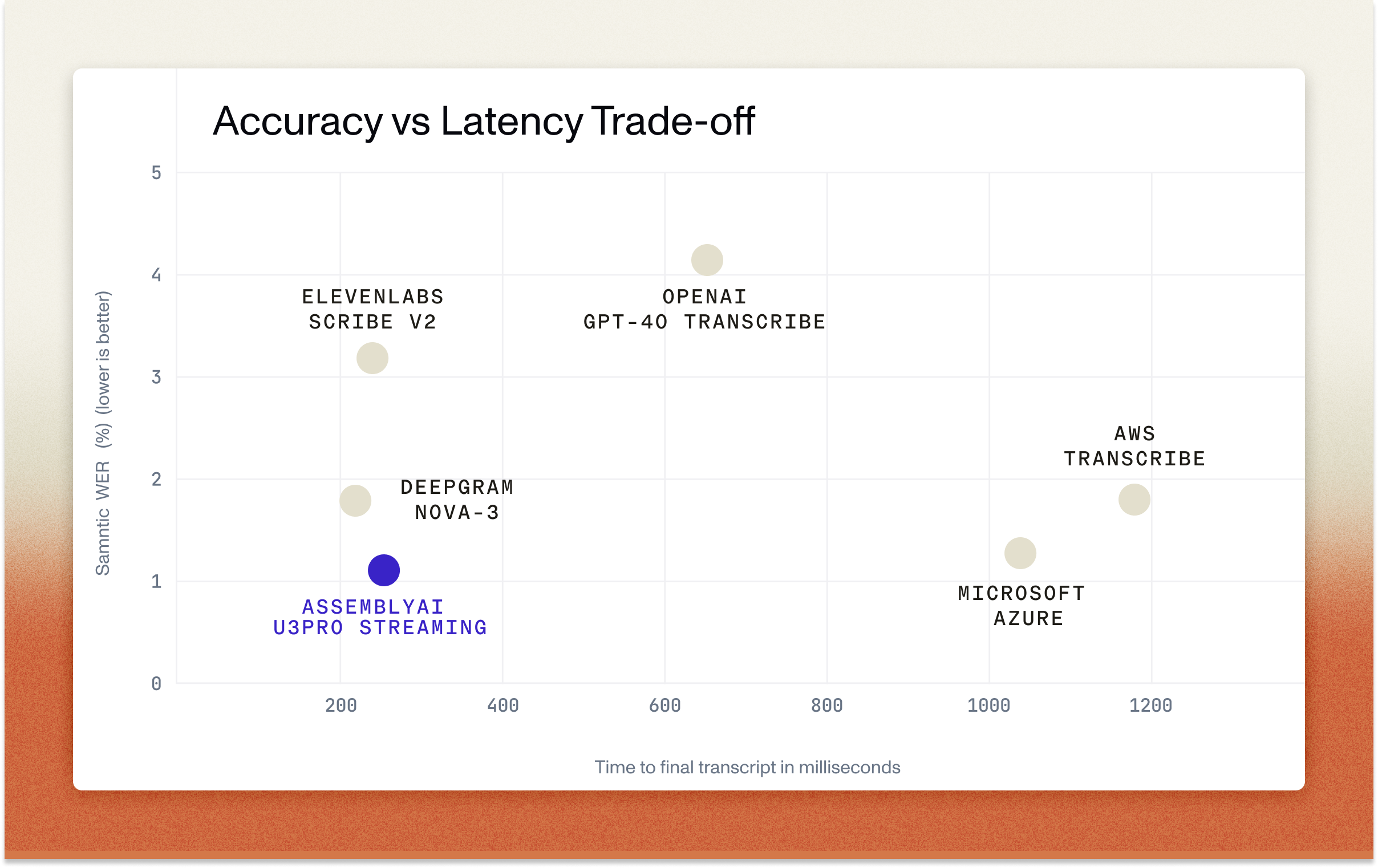
Performance that matches production requirements
Speed matters in real-time applications. Universal-3 Pro Streaming delivers:
- P50 latency: ~150ms after VAD endpoint detection
- P90 latency: ~240ms after VAD endpoint detection
- ~250ms P50 time to complete transcript when paired with VAD set to 100ms
Priced to scale
Universal-3 Pro Streaming is priced at $0.45/hr ($0.0075/min) base rate, with optional add-ons that stack based on what you actually use:
- Keyterms Prompting: Included
- Streaming Diarization: +$0.12/hr
- Prompting (Beta): +$0.05/hr
Unlimited concurrency, no rate limits, no upfront commitments. Volume discounts are available for larger deployments.
Get started
Universal-3 Pro Streaming is available now. If you're already using Universal-Streaming, upgrading is a one-line change: update the speech_model parameter to u3-rt-pro.
Three ways to get started:
- Playground: Test Universal-3 Pro Streaming with your audio, no code required.
- Documentation: Review the streaming API guide and prompt engineering templates
- API: Use your existing API key. Update the speech_model parameter and start streaming.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.


