AssemblyAI Universal-3-Pro vs ElevenLabs Scribe v2 Compared
Compare AssemblyAI Universal-3-Pro vs ElevenLabs Scribe v2 for speech-to-text APIs. Learn key differences in prompting control, multichannel support, concurrency handling, pricing, and compliance features for production voice applications.



Choosing a speech-to-text API today means evaluating more than raw transcription accuracy. For teams shipping production voice applications, factors like prompting control, concurrency limits, multichannel handling, and downstream speech understanding capabilities often matter more than model benchmarks alone.
In this post, we compare ElevenLabs Scribe v2 and AssemblyAI Universal-3-Pro, with a focus on asynchronous (async) transcription, scalability, and real-world deployment tradeoffs.
Get $50 in free credits to test AssemblyAI’s models
Feature comparison
ElevenLabs Scribe v2
Scribe v2 is ElevenLabs’ latest speech-to-text model, optimized for broad language coverage and built-in entity detection. It supports both batch (async) and real-time transcription and integrates into ElevenLabs’ broader voice platform (TTS, voice cloning, dubbing, conversational AI).
AssemblyAI Universal-3-Pro
Universal-3-Pro is a context-aware speech-to-text model purpose-built for large-scale async workloads. It prioritizes transcription control, multichannel support, predictable concurrency, and deep speech understanding features beyond basic ASR.
| Feature | ElevenLabs Scribe v2 | AssemblyAI Universal-3-Pro |
|---|---|---|
| Language & Customization | ||
| Language Support | 90+ languages | 6 core languages; fallback to 99 via Universal model |
| Natural Language Prompting | Not supported | Up to 1,500 words |
| Keyterm Prompting | Up to 100 terms | Up to 1,000 terms (incl. multi-word phrases) |
| Audio Tagging | Built-in (laughter, applause, etc.) | Via prompting (flexible, user-controlled) |
| Speaker & Channel Handling | ||
| Max Speakers (Diarization) | Up to 48 | Up to 100 |
| Max Channels | Up to 5 | Unlimited |
| Multichannel + Diarization | Cannot combine | Supported simultaneously |
| Entity Detection & Redaction | ||
| Entity Detection (PII/PHI/PCI) | Supported | Supported |
| Text Redaction | Supported | Supported |
| Audio Redaction | Not available | Supported (redacted MP3/WAV output) |
| Concurrency & Scaling | ||
| Concurrency Model | Shared account-wide across all products | Separate pools per product |
| Multichannel Concurrency | Scales linearly with channel count | 1× concurrency regardless of channels |
| Long File Handling | Internally chunked (uses extra concurrency) | No extra concurrency consumed |
| Paid Concurrency Tiers | Yes | No |
| Pricing (Async) | ||
| Base Transcription | $0.22/hr (Business) | $0.21/hr |
| Keyterm Prompting | +$0.07/hr | +$0.05/hr |
| Speaker Diarization | Included | +$0.02/hr |
| Entity Detection | +$0.04/hr | +$0.08/hr |
| PII Audio Redaction | Not available | +$0.05/hr |
Language Support
Scribe v2 supports 90+ languages, making it a strong choice for globally distributed or multilingual applications.
Universal-3-Pro currently supports six core languages (English, Spanish, Portuguese, French, German, Italian), with fallback support to 99 languages via AssemblyAI’s Universal model. This makes Universal-3-Pro well-suited for high-accuracy workflows in supported languages, while still allowing coverage elsewhere.
Prompting and customization
One of the biggest differences between the two platforms is prompting capability.
Scribe v2:
- Supports keyterm prompting (up to 100 terms)
- Does not support natural language prompts
Universal-3-Pro:
- Supports up to 1,500 words of natural language prompting
- Supports 1,000 keyterms, including multi-word phrases
- Allows fine-grained control over transcription style, domain terminology, disfluencies, and audio tagging
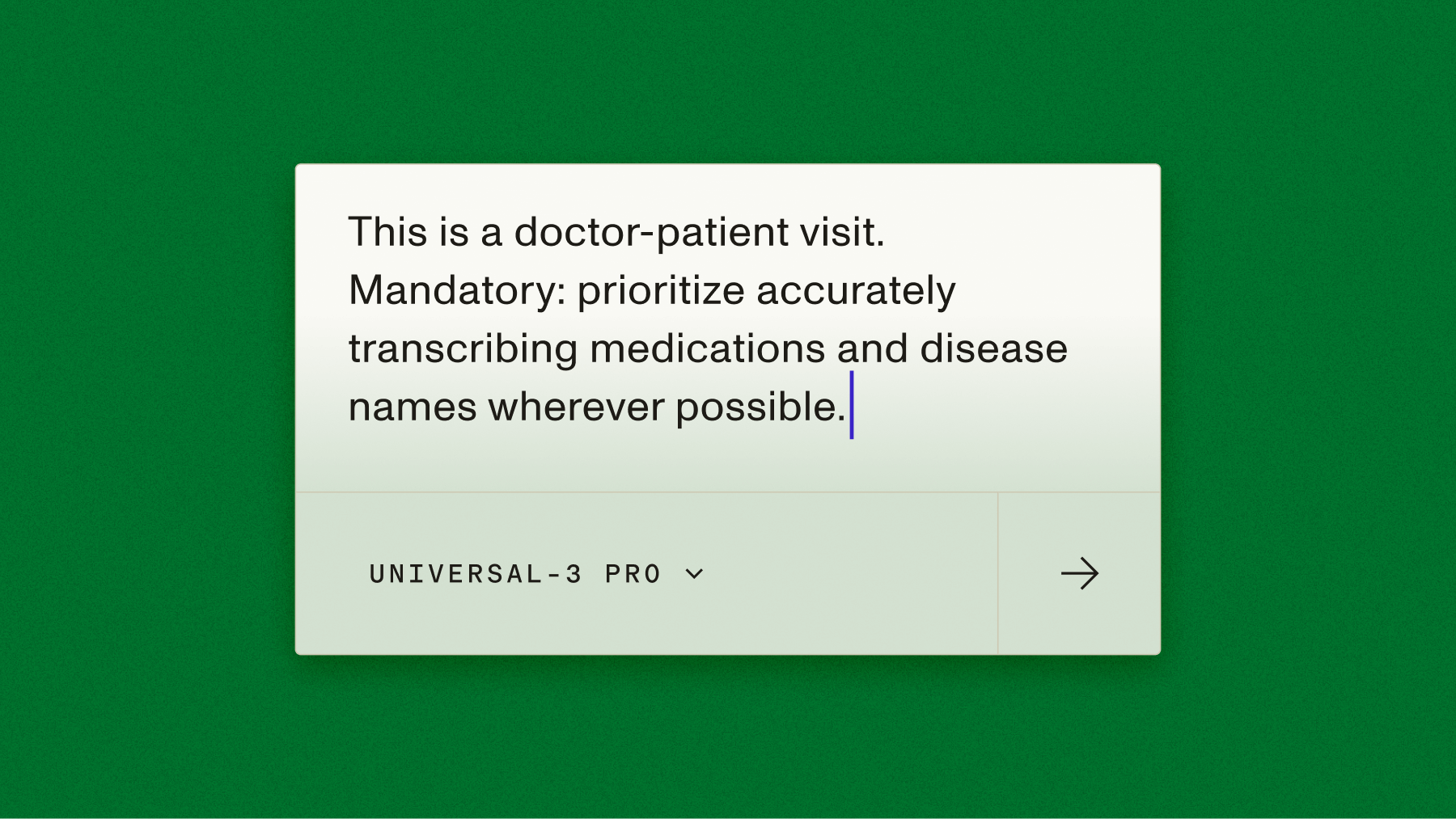
Unlike other speech-to-text models, you're not limited to light keyterm prompting or a single, fixed output style — you get LLM-style controllability over the transcription itself. You can progressively layer in instructions (e.g., be more verbatim and capture filler words, treat this as a medical conversation, label speakers by role, doctor vs. patient, handle code switching between English and Spanish) and reliably steer the model’s behavior without changing your underlying audio or pipeline.
This unmatched controllability means you can design one robust prompt and apply it across tens or hundreds of calls, getting consistent, workflow-ready outputs rather than brittle, one-off hacks around the model’s limitations.
Audio tagging
Scribe v2 includes built-in audio tagging for non-speech events such as laughter and applause, returned as separate elements in the word array.
Universal-3-Pro achieves similar (and often more flexible) behavior via prompting. This allows developers to explicitly choose which events to tag, or omit entirely, depending on the use case.
Speaker diarization and multichannel audio
This is a major architectural difference:
Scribe v2
- Up to 48 speakers
- Up to 5 channels
- Cannot combine multichannel audio with diarization
Universal-3-Pro
- Up to 100 speakers
- Unlimited channels
- Supports multichannel + diarization simultaneously
For call center, meeting intelligence, or interview analysis use cases, the ability to separate channels and identify speakers within each channel is critical.
Entity detection and redaction
Both platforms support entity detection across PII, PHI, and PCI categories.
Key difference:
- Scribe v2 supports text redaction only
- Universal-3-Pro supports text + audio redaction, generating redacted MP3 or WAV files with sensitive information beeped out
Audio redaction is often required for regulated industries that store or replay audio recordings.
Concurrency and scaling
Concurrency management is where many teams encounter unexpected friction in production.
ElevenLabs
- Concurrency is shared account-wide across products (STT, TTS, streaming)
- Longer files are internally chunked, consuming additional concurrency
- Multichannel audio scales linearly with channel count
- Capacity planning becomes more complex as workloads grow
AssemblyAI
- Separate concurrency pools per product
- No paid concurrency tiers
- No priority queues
- Multichannel files count as 1× concurrency
For high-volume async workloads, AssemblyAI’s model is significantly easier to reason about and scale.
Pricing overview (Async)
Pricing varies by plan and volume, but Universal-3-Pro generally offers lower base cost and fewer required add-ons for advanced workflows.
Pricing overview (Async)
| Feature | Scribe v2 | Universal-3-Pro |
|---|---|---|
| Base Transcription | $0.22/hr (Business) | $0.21/hr |
| Keyterm Prompting | +$0.07/hr | +$0.05/hr |
| Speaker Diarization | Included | +$0.02/hr |
| Entity Detection | +$0.04/hr | +$0.08/hr |
| PII Audio Redaction | Not available | +$0.05/hr |
Get $50 in free credits to test AssemblyAI’s models
Final takeaway
Scribe v2 is a capable ASR model within a broader voice platform. Universal-3-Pro is designed specifically for teams that treat speech, not just text, as structured data and need reliability, control, and scale.
If you’re building production-grade voice applications, the difference is less about features on paper and more about operational simplicity.
Frequently Asked Questions (FAQs)
What is the main difference between AssemblyAI Universal-3-Pro and ElevenLabs Scribe v2?
The main difference is transcription control and scalability architecture. AssemblyAI Universal-3-Pro supports up to 1,500 words of natural language prompting for fine-grained control over output, while ElevenLabs Scribe v2 does not support natural language prompts. Additionally, AssemblyAI uses separate, predictable concurrency pools and supports unlimited multichannel audio with simultaneous speaker diarization, whereas ElevenLabs shares concurrency across all products and limits multichannel files to 5 channels without diarization support.
Is AssemblyAI cheaper than ElevenLabs for speech-to-text?
AssemblyAI Universal-3-Pro has a lower base async transcription rate ($0.20/hour vs $0.22/hour for ElevenLabs Business tier) and includes 1,000 keyterms at no additional cost. ElevenLabs charges +$0.07/hour for keyterm prompting beyond 100 terms. While specific feature add-on costs vary, AssemblyAI generally requires fewer paid features for advanced workflows like multichannel processing and offers more predictable scaling costs due to its simpler concurrency model.
Can AssemblyAI transcribe multichannel audio with speaker diarization?
A: Yes. AssemblyAI Universal-3-Pro supports unlimited channels and can perform speaker diarization simultaneously on multichannel audio, which is critical for call center recordings, interviews, and meetings where you need both channel separation and speaker identification. ElevenLabs Scribe v2 limits multichannel audio to 5 channels and does not support combining multichannel processing with speaker diarization.
Which speech-to-text API is better for compliance and regulated industries?
A: AssemblyAI Universal-3-Pro is better suited for compliance-heavy workflows. It offers both text and audio PII redaction (generating redacted audio files with sensitive information removed), supports up to 1,500 words of prompting for precise compliance terminology handling, and provides predictable concurrency without shared limits. ElevenLabs Scribe v2 only supports text-based redaction and lacks audio redaction capabilities required by many regulated industries that store or replay recordings.
How does concurrency work differently between AssemblyAI and ElevenLabs?
A: AssemblyAI uses separate concurrency pools for each product (speech-to-text, text-to-speech), with multichannel files counting as 1× concurrency regardless of channel count. ElevenLabs shares concurrency account-wide across all products (STT, TTS, streaming), and multichannel files consume concurrency linearly based on channel count. ElevenLabs also chunks longer files internally, consuming additional concurrency slots. For high-volume async workloads, AssemblyAI's model is simpler to plan and scale.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.