
Introducing our Voice Agent API
Today we're launching our Voice Agent API: the complete voice agent pipeline, built on our own models top to bottom, behind a single WebSocket. Purpose-built around one idea — your agent is only as smart as what it actually hears.



You know when a voice agent cuts you off mid-sentence? Or sits in silence for three seconds before responding? Or you try to interrupt and it just keeps talking over you?
Those moments aren't a voice problem. They're a listening problem. And they're why most voice experiences still feel like demos, even when everything else about the product is polished.
Today we're launching our Voice Agent API: the complete voice agent pipeline, built on our own models top to bottom, behind a single WebSocket. Purpose-built around one idea: your agent is only as smart as what it actually hears.
Our voice stack, end-to-end
The Voice Agent API is a single WebSocket connection. You stream audio in. You get audio back. One bill, measured in hours. One place for logs and observability. $4.50/hr covers everything: speech understanding, LLM reasoning, and voice generation.
Simple on purpose. The less overhead you manage, the faster you ship. When voice infrastructure is invisible, you spend your time on the product, not the plumbing.

If you're already building on LiveKit or Pipecat, our speech-to-text still powers your stack. The Voice Agent API is for teams who want the full pipeline in one integration.
Why listening is the hard part
Most voice agent platforms treat STT as a solved problem; a commodity step before the "real" work happens. We don't see it that way, and the numbers are why.
In our Voice Agent Report, 76% of respondents rated speech-to-text accuracy as the single most important non-negotiable when building voice agents, above latency, cost, and integration capabilities.
Here’s why: If the transcription is wrong, the LLM responds to the wrong thing. A garbled account number, a misheard medication name, a missed customer question: the downstream effects compound fast. Garbage in, garbage out.
Universal-3 Pro Streaming, the model the Voice Agent API runs on, handles names, account numbers, domain terminology, and accented speech, with leading accuracy, and the proof is in the outcomes our customers see with their voice agents.


But accurate transcription is only half of listening. The other half is knowing when someone is done talking.
Turn detection, knowing the difference between "I'm pausing to think" and "I'm done, your turn," is one of the hardest problems in conversational AI. Get it wrong and you either cut people off or leave uncomfortable silences. Both kill the experience.
We handle turn detection server-side, with configurable thresholds so you can tune the conversational feel for your specific use case. When a user interrupts, the agent stops immediately and starts listening again. No shouting over it. No awkward dead air. Conversations just flow.
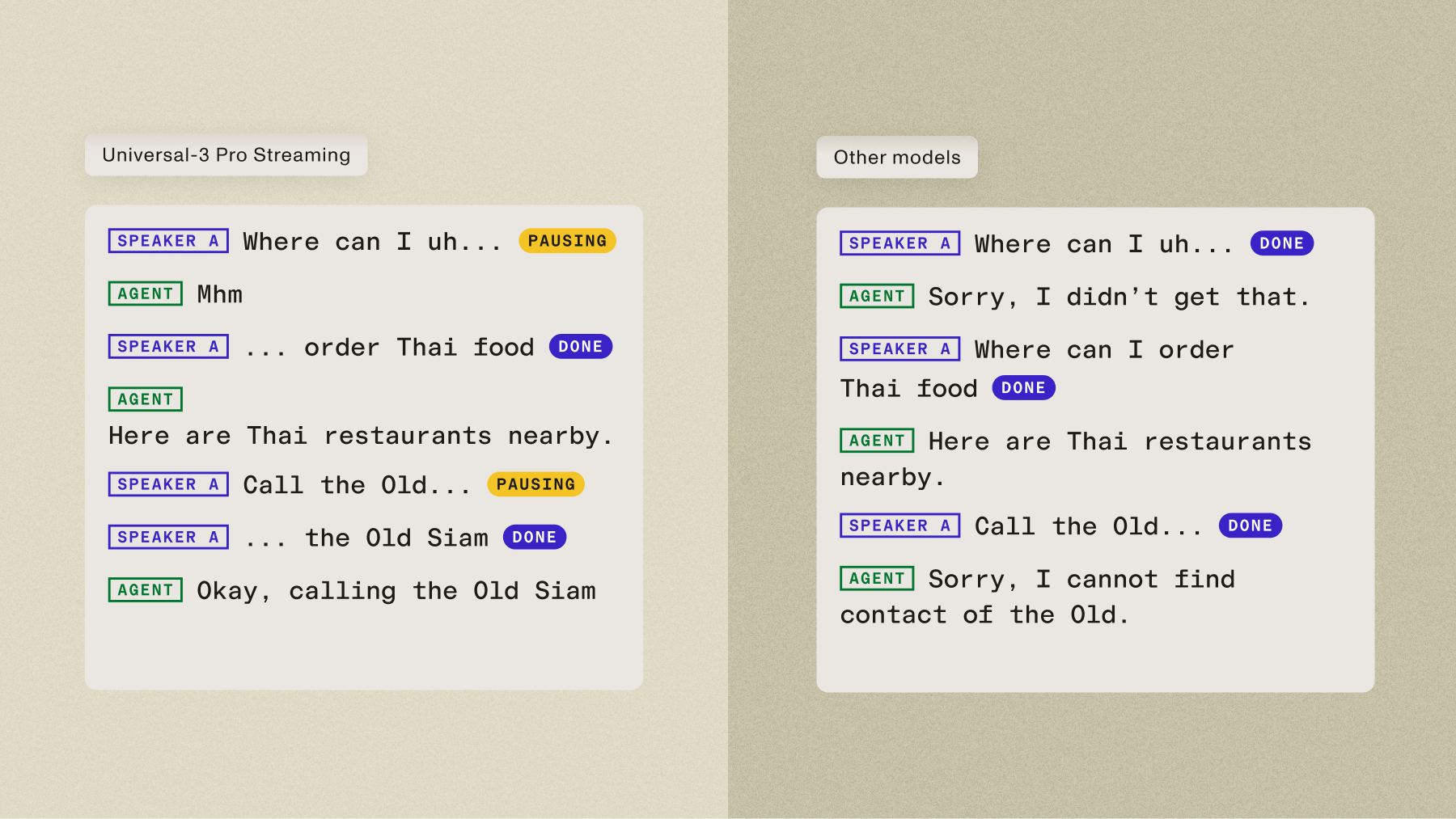
The developer experience we've been building toward
The API is a WebSocket and a handful of JSON message types. No SDK to install. No framework to learn. You can read the entire API reference in 10 minutes. Most developers get a working agent running the same afternoon they start.
It's also the first API we've built that works end-to-end with Claude Code. Paste the docs into your terminal and scaffold a working integration without leaving it.
A few things that make building with it feel different:
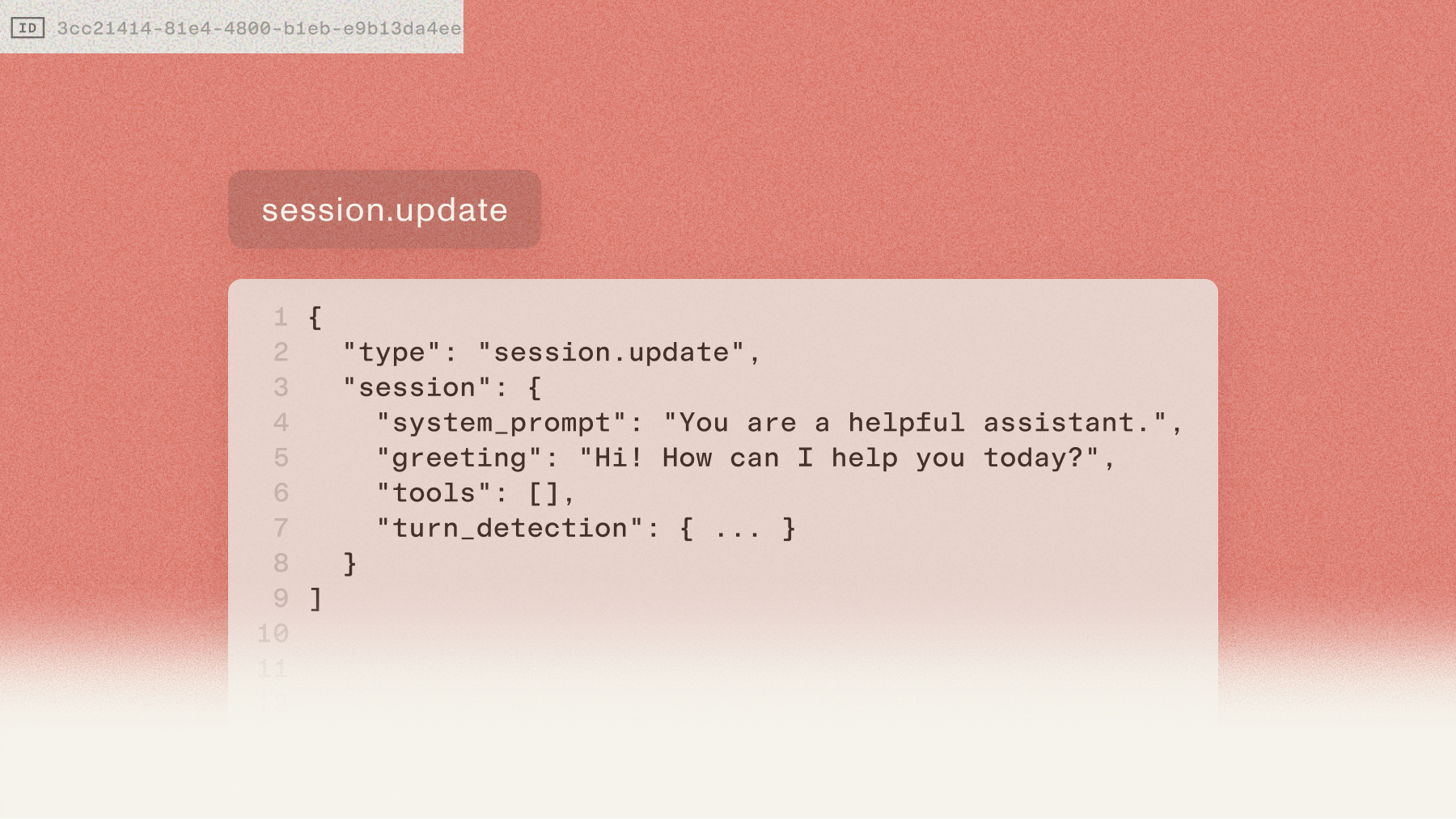
- Live configuration. Update the system prompt, tools, or turn detection settings mid-conversation. No reconnection needed. This matters more than it seems. Most voice platforms require a full re-initialization when you need to change agent behavior.
- Tool calling. Register custom functions with JSON Schema and let the agent take real actions. Your logic, your integrations, our orchestration.
- Session resumption. If the WebSocket drops, reconnect within 30 seconds and pick up exactly where you left off. Context preserved.
- Standard JSON throughout. No proprietary event schemas to learn. No framework-specific patterns to unlearn. If you can read JSON, you can read the full API surface.
What you can build
The API is infrastructure, not a product template. What you build on it should feel like yours, not like every other voice agent on the same platform.
A contact center that routes tickets based on what the customer actually said, not a keyword match. A clinical intake workflow that captures medication names correctly the first time. A sales coaching tool that catches the moment a rep fumbled the objection. A language learning app that gives real-time feedback in six languages.
The teams we've talked to are building things we didn't anticipate. Not because the API is flexible in some abstract way, but because it's invisible enough to get out of the way.
Invisible infrastructure
There's a version of a voice product where users feel like they're using a platform. Same personality. Same patterns. Same guardrails. Then there's the version where users feel like a team built something specifically for them.
The Voice Agent API is designed to enable the second version. Your customers should feel like you built it.
We're not the agent. We're the platform you build on.
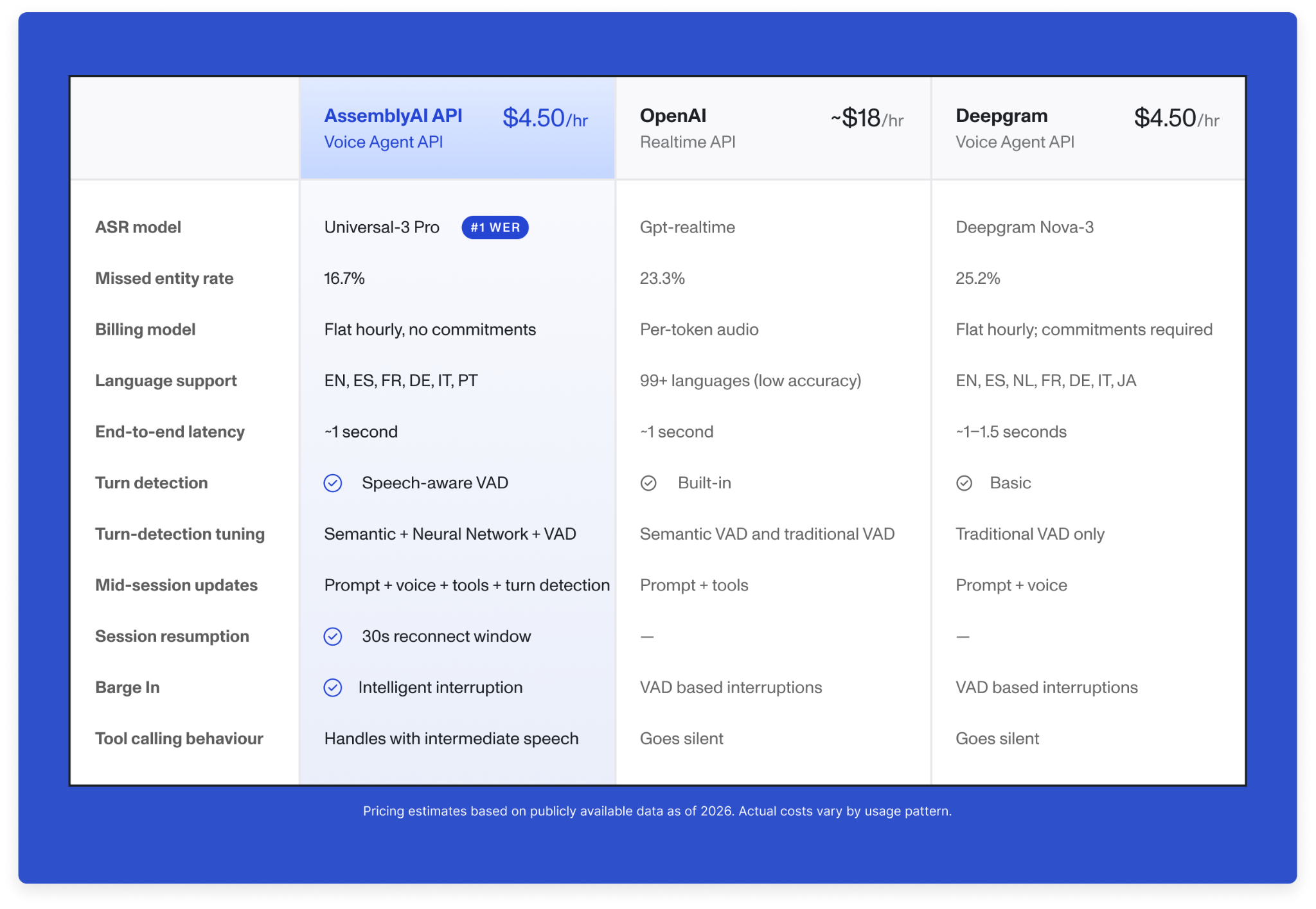
How we compare
Production voice agents live or die on a handful of numbers: how fast the model responds, how accurately it transcribes, how much it costs per hour, and whether the pricing stays predictable as you scale. Here's where the Voice Agent API lands.
Get Started
The best way to evaluate a voice agent platform is to have a conversation with one. Try it in the playground, or start building now. If you like the way it listens, the rest follows.
Get your API key →
Try it in the Playground →
Read the docs →
Frequently asked questions
Why does speech-to-text accuracy matter more than LLM quality for voice agents?
If the transcription is wrong, the LLM responds to the wrong thing — a garbled account number, a misheard medication name, or a missed customer question compounds through every downstream step. The Voice Agent API runs on Universal-3 Pro Streaming, which has the lowest word error rate of any production-grade streaming speech model and is purpose-built to capture names, numbers, and domain terminology that voice agents need to act on. Accurate listening is the foundation that makes everything else — reasoning, tool use, voice output — actually work.
How does the Voice Agent API handle turn detection and interruptions?
The API handles turn detection server-side using configurable thresholds that combine acoustic and semantic signals, going beyond basic silence-based VAD to distinguish between a natural pause and a completed thought. When a user interrupts mid-response, the agent stops speaking immediately and starts listening again — no shouting over it and no dead air. Developers can tune the conversational feel for their specific use case, from fast-paced IVR flows to longer-form clinical conversations.
Can I update my voice agent's behavior during a live conversation?
Yes — the Voice Agent API supports live configuration updates without requiring a reconnection. You can change the system prompt, register or remove tools, or adjust turn detection settings mid-conversation while the WebSocket stays open. This is a meaningful difference from most voice platforms, which require a full re-initialization to change agent behavior, causing dropped context and interrupted sessions.
Does the Voice Agent API work with Claude Code?
Yes. The Voice Agent API is the first AssemblyAI API built to work end-to-end with Claude Code — you can paste the docs into your terminal and scaffold a working voice agent integration without leaving the CLI. The API uses standard JSON over WebSocket with no proprietary SDK, so Claude Code can generate functional integration code directly from the API reference. Most developers ship a working demo the same afternoon they start.
How is the Voice Agent API different from stitching together separate STT, LLM, and TTS providers?
A multi-vendor pipeline means managing three separate APIs, three billing models, and the latency overhead of chaining them together — plus the engineering burden of handling turn detection, interruption logic, and session state yourself. The Voice Agent API collapses all of that into a single WebSocket at $4.50 per hour flat, with turn detection, tool calling, and session resumption built in. For teams already using orchestrators like LiveKit or Pipecat, Streaming Speech-to-Text remains available as a modular STT component.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts
