
Speech-to-text prompting with AssemblyAI Universal-3 Pro
Learn the best practices for speech-to-text prompting with AssemblyAI Universal-3 Pro

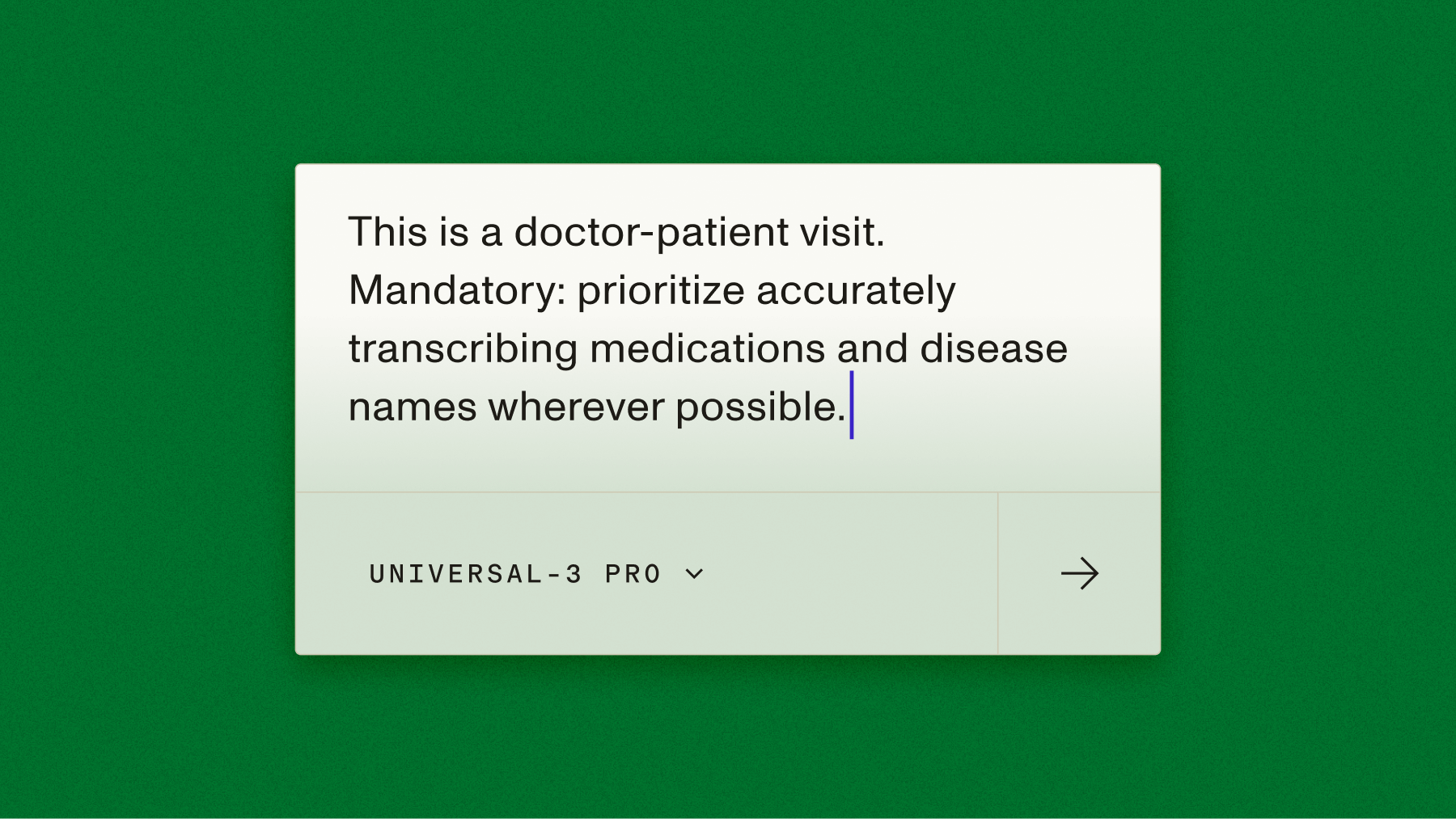

Universal-3-Pro is AssemblyAI's state-of-the-art speech recognition model, and the first of its kind promptable Speech Language Model. Universal-3-Pro lets developers guide transcription with natural language prompts so accuracy is shaped up front, not corrected downstream. Rather than applying fixes after the fact, you provide context before the model listens: preserving disfluencies, capturing audio events, and handling speech patterns that standard transcription misses. The result is transcripts tailored to what actually matters for your application.
Universal-3 Pro accepts a prompt parameter that lets you influence transcription behavior using plain English. This is different from post-processing — instructions are applied during transcription.
This guide covers what actually works, with code.
Setup
pip install assemblyaiimport assemblyai as aai
aai.settings.api_key = "your-api-key"Specify the model via speech_models. Always include universal-2 as a fallback for languages outside Universal-3 Pro's core six (English, Spanish, Portuguese, French, German, Italian):
config = aai.TranscriptionConfig(
speech_models=["universal-3-pro", "universal-2"],
prompt="Your instructions here."
)
transcript = aai.Transcriber().transcribe("audio.mp3", config=config)
print(transcript.text)Note: prompt and keyterms_prompt are mutually exclusive — pick one per request. Use keyterms_prompt when you just need term boosting and don't require behavioral control. Use prompt when you need formatting, speaker labeling, or transcription style.
Start without a prompt
Before writing any instructions, run the transcription with no prompt. See what the model gets right and wrong on its own. This tells you exactly what to fix, rather than over-specifying behavior the model already handles correctly.
What you can actually control
1. Domain context
A single sentence describing the audio content helps the model resolve ambiguous words correctly.
prompt="This is a cardiology consultation discussing
echocardiogram results and beta blocker dosing."The model uses this to favor domain-appropriate spellings when audio is unclear — e.g. "metoprolol" over "meta-propanol."
2. Vocabulary corrections
Show 2–3 spelling examples. The model generalizes the pattern rather than memorizing exact matches.
prompt="""Spelling corrections: 'metformin' not 'metaformin',
'HbA1c' not 'A1C', 'AssemblyAI' not 'Assembly AI'."""
You don't need an exhaustive list. Pattern examples work better than word dumps.
3. Transcription style: clean vs. verbatim
Clean — removes filler words, false starts, repetitions:
prompt="Produce a clean transcript. Remove filler words (um, uh,
like) and false starts."Verbatim — preserves everything as spoken:
prompt="Verbatim transcript. Include all filler words,
hesitations, and repetitions exactly as spoken."Choose based on downstream use. Clean is better for meeting notes and docs; verbatim for research, legal records, or training data.
4. Output formatting
Control number formatting, punctuation style, and structure:
prompt="""Format numbers: spell out under ten, use numerals for 10+.
Format currency as '$X.XX'. Write percentages as 'X.X%'. No em dashes."""
5. Speaker labeling (experimental)
Works best for structured two-person conversations with known roles:
prompt="""Label speakers as 'Interviewer' and 'Candidate'.
The Interviewer asks questions; the Candidate gives longer responses."""
This feature has variable results. For reliable timestamped speaker segments, use speaker_labels=True instead and skip prompted speaker attribution. Don't combine both in the same request.
6. Code-switching / multilingual
Preserves mixed-language speech in its original language mix without forcing translation:
prompt="Transcribe in the original language mix. Preserve each
phrase in the language it was spoken — do not translate. Audio
contains Spanish and English."Universal-3 Pro handles code-switching natively across its six core languages.
Combining instructions
You can stack all of the above in a single prompt. Keep it under 300 words (the 1,500-word limit gives plenty of headroom, but concise prompts perform better):
config = aai.TranscriptionConfig(
speech_models=["universal-3-pro", "universal-2"],
prompt="""Context: Quarterly earnings call with company executives.
Clean transcript — remove filler words and false starts.
Spelling: 'EBITDA' not 'e-bid-da', 'CapEx' not 'cap ex'.
Format currency as '$X.XX'. Write percentages as 'X.X%'. Spell out numbers under ten."""
)
transcript = aai.Transcriber().transcribe("earnings_call.mp3", config=config)
print(transcript.text)Recommended prompt order:
- Context
- Speaker roles
- Transcription style (clean/verbatim)
- Vocabulary corrections
- Formatting rules
Limitations
Some limitations to consider:
- prompt only works with Universal-3 Pro, not Universal-2
- prompt and keyterms_prompt cannot be used together
- Max prompt length: 1,500 words
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts




