How to get the most out of Universal-3 Pro with prompt engineering
Learn how to use natural language prompts with Universal-3 Pro to control transcription output, from capturing disfluencies to handling multilingual audio and PII.



Universal-3 Pro is the first production-quality, promptable speech-to-text model from AssemblyAI. Alongside your transcription request, you include a plain-language instruction that controls how the model handles speech patterns, ambiguous audio, mixed languages, and more.
This guide covers the core prompting techniques, real examples from our workshop, and best practices for iterating toward the right prompt for your use case.
Universal-3 Pro vs. Universal-2: what changed?
It helps to see what the model does differently out of the box, with no prompt at all, before getting into prompting specifics.
Universal-3 Pro was built exclusively on speech tasks—transcription, speaker identification, and audio understanding—giving it a level of contextual understanding that general-purpose models can't replicate. It also handles broad language coverage, with automatic language detection that can fall back across 99 languages, so you get the accuracy and flexibility of Universal-2 alongside its deeper speech intelligence. For teams that need promptable control over how transcription behaves before it even begins, Universal-3 Pro is the stronger foundation.
Here's a concrete example from a real test file: the speaker says, "Why are you here when it's midnight? We could talk—glad you're here." Universal-2 transcribed it as: "Why are you here? When it's midnight, we can talk." Universal-3 Pro got it right. Different punctuation, different sentence structure, completely different meaning.
That contextual awareness is what makes prompting possible in the first place. As Zach from our Applied AI engineering team put it during the workshop:
"The model is capable of interpreting an audio event and, based on the context we provided upfront with the prompt, determining how to represent that information within the transcript."
What is a promptable speech language model?
With Universal-3 Pro, you include a natural language prompt in your API request alongside the audio. The model reads that instruction before processing the audio and uses it to guide transcription decisions: how to handle filler words, whether to translate or preserve foreign language, how confident it needs to be before writing a word.
Unlike general-purpose LLMs built for text, images, and video, Universal-3 Pro is trained exclusively on speech. This means your prompts control how the transcript is generated, not whether you get a transcript at all. The output is always a transcript.
The key thing to know: vague instructions produce vague results. The model is highly instructional. It responds well to specific, directive language and tends to underperform when instructions are soft or general. More on that in the best practices section below.
Key prompting techniques
Preserving disfluencies and speech patterns
By default, Universal-3 Pro produces clean, readable output. It strips most "ums," "uhs," false starts, and colloquialisms like "gonna" in favor of "going to." That's fine for meeting notes, but it's not what you want when analyzing speaker performance, coaching sales reps, or doing qualitative research.
To capture those patterns, you need to be explicit and specific. Writing "disfluencies" alone isn't enough. The model isn't sure what you mean: does that include "um"? Filler words? Repeated phrases? You need to spell it out.
Example prompt:
Mandatory: Preserve linguistic speech patterns including
disfluencies, filler words, hesitations, repetitions, stutters,
false starts, and colloquialisms in the spoken language.Layer in more components as needed. "Colloquialisms" alone will get you "gonna" instead of "going to." "Repetitions" will surface phrase restarts. The more specific the instruction, the more the model surfaces.
"If I was evaluating my performance on this webinar, you probably want to hear ums and uhs to understand if I was speaking clearly and professionally. In other contexts, maybe you prefer it to read more like a transcript or a book. You can actually control this." — Ryan, Head of Customer-Facing Teams
Best-guess transcription
When audio quality is low or speech is ambiguous, the model may suppress a prediction rather than risk a wrong answer. If you want it to commit, to take its best shot at any speech it detects, tell it to.
Example prompt:
Always: Transcribe speech with your best guess based on context
in all possible scenarios where speech is present in the audio.This is particularly useful for difficult audio files where the model might otherwise leave gaps. It signals that if there's any chance that's speech, write something.
Marking unclear audio
The other side of best-guess transcription. If you'd rather the model flag uncertainty than guess wrong, useful for human review workflows or building pseudo-labeled datasets, prompt it to mark unclear segments instead.
Example prompt:
Transcribe speech with your best guess when speech is heard. Mark
unclear when audio segments are unknown.On implementation: the team tested both [unclear] and [masked] tags. [unclear] is the recommended default. [masked] surfaces more instances of uncertain audio, but it also has a side effect of tagging profanity, so it can remove content you may want to keep. Use [masked] only if your use case doesn't require profanity in the output.
"We've done tons of experiments... and we've landed on 'unclear' as probably the best way to represent that data." — Zach
One practical application: run two transcriptions in parallel, one with best-guess and one with unclear tagging. The best-guess version acts like a pseudo-labeled transcription; the unclear version tells a human reviewer exactly where to focus their attention.
Code-switching and multilingual audio
Universal-3 Pro currently supports six languages: English, Spanish, French, German, Italian, and Portuguese, with auto-fallback to 99 languages with Universal-2 and additional languages planned as part of ongoing model development. For audio that mixes languages within the same conversation, common in communities like Miami where English and Spanish blend naturally, the model defaults to transcribing everything in the dominant language unless you tell it otherwise.
In testing with the Miami Corpus, a dataset of Spanglish conversations, the unprompted model translated Spanish phrases into English. Adding one instruction fixed it.
Example prompt:
Preserve the original language(s) and script as spoken, including
code-switching and mixed-language phrases."By telling the model 'don't translate this thing,' we've actually caused it to fix it... you start to see how having these different prompts is going to change the way that it's transcribing and picking up all these small Spanish words within the audio file." — Ryan
PII redaction via prompting
Universal-3 Pro can tag personally identifiable information within the transcript as [private], but only with precise instructions. The generic term "PII" isn't reliable enough; the model doesn't consistently know what that covers. Instead, enumerate the specific types of information you want flagged.
Example prompt:
Always: Transcribe the audio. Tag any names, addresses, phone
numbers, email addresses, and contact information as [private].This works alongside AssemblyAI's native PII redaction feature, which is also expected to see improved entity detection performance with Universal-3 Pro.
"It's hard to control this if we don't give it very specific instructions. You would actually want to enumerate exactly what you want, names, addresses, contact information, and this would give you a much better result." — Ryan
Audio tagging for non-speech events
Universal-3 Pro can attempt to identify and label non-speech audio events, laughter, silence, background noise, music, and more. Performance varies by file right now, so treat this as an experimental capability. That said, for use cases where non-speech context matters, call quality monitoring, media production, ambient audio logging, it's worth testing.
Example prompt:
Include all audio tags for non-speech wherever encountered.For better results, specify the tags you're looking for rather than asking for all of them at once. The model can get overeager with a broad instruction.
Speaker labels (experimental)
The model can emit speaker change markers and attempt to assign roles or names based on conversational context. For short, clearly structured audio, this works well. For long files, it's not production-ready.
The reason: Universal-3 Pro processes long audio in chunks, and speaker context doesn't always carry across chunk boundaries. You might get accurate speaker labels in the first chunk, inconsistent labels in the middle, and accurate again at the end.
For production use cases, use AssemblyAI's native Speaker Diarization feature (speaker_labels: true). If you need speaker names or roles rather than generic labels (Speaker A, Speaker B), pair it with Speaker Identification, which analyzes conversation content to infer who is speaking and replaces generic labels with meaningful identifiers. Work is underway to combine the model's audio-level speaker change detection with the native diarization feature, which will improve overall accuracy by drawing on both acoustic embeddings and the model's contextual awareness.
Prompt structure quick reference
Writing effective prompts: best practices
Use directive language. Words like "mandatory," "always," and "never" produce more consistent results than soft framing. "Take a guess" signals low priority; "always transcribe with your best guess in all possible scenarios" signals a firm instruction. The model responds to specificity and authority.
Be specific, not categorical. "Disfluencies" is a category. "Um, uh, false starts, and repeated phrases" is a list of things you actually want. The more specific the instruction, the less the model has to interpret, and the more predictable your output.
Layer prompts incrementally. Start with one instruction, evaluate the output, then add the next. Stacking five instructions at once makes it hard to identify what's working. Build from a baseline.
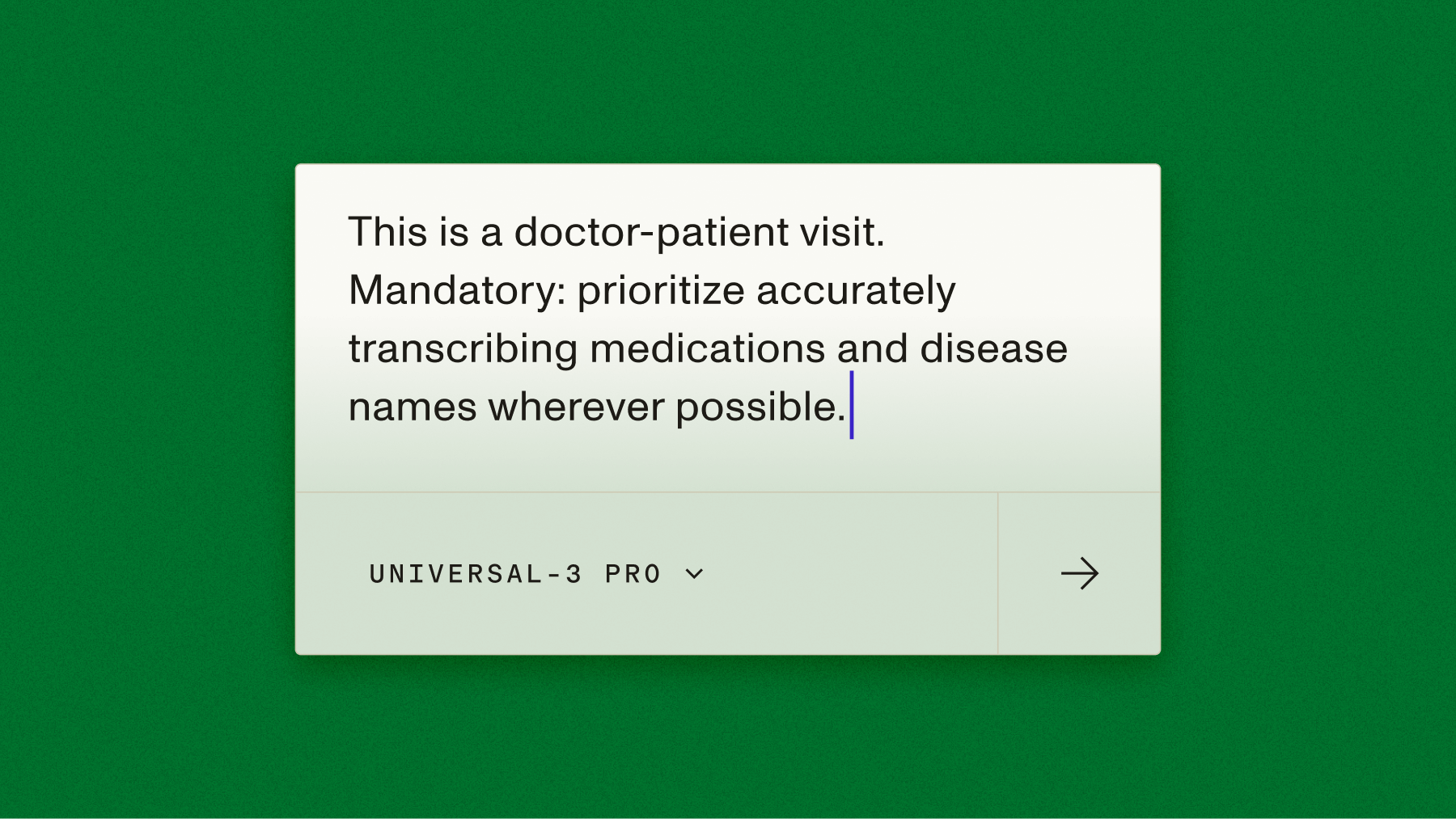
Frame domain context as instructions, not descriptions. Don't just describe the audio, tell the model what to do with it:
❌ "This is a doctor-patient visit."
✅ "This is a doctor-patient visit. Prioritize accurately transcribing medication names and medical conditions wherever possible."The first tells the model what it's hearing. The second tells it how to behave, and that's what actually changes the output.
Know when to use Keyterms Prompting vs. open-field prompting. Keyterms Prompting is best when you know specific names, jargon, or product terms in advance. Open-field prompting is better when the content is variable or unknown. Note that on Universal-3 Pro, Keyterms Prompting supports up to 1,000 words or phrases, a significant expansion over Universal-2's 200-word limit, and is available as a separate add-on at $0.05/hour. The two parameters are mutually exclusive at the API level, but you can include key terms inside your open prompt field to approximate a combined approach.
How to evaluate and iterate on prompts at scale
Getting to the right prompt for a specific dataset takes iteration. A few tools that help:
AssemblyAI CLI eval tool — Pull public datasets from Hugging Face, run prompts against them, and compare outputs to ground truth using word error rate. Good for quick simulation across standardized benchmarks.
Prompt optimization repo — A more structured approach that uses component-based testing. Define prompt components (disfluency handling, language behavior, guessing rules, etc.), test variations of each, and converge on the best-performing combination.
Prompt Repair Wizard — Available on the AssemblyAI dashboard. Paste in your current prompt, describe what's going wrong in the output, and the tool suggests improvements based on prompting best practices.
A note on word error rate and human-labeled data
Traditional WER benchmarks compare model output to a human-labeled truth file. With Universal-3 Pro, that comparison gets complicated. The model frequently outperforms the human transcriber.
In testing with one customer's dataset, the team reviewed every difference between Universal-3 Pro output and the human-labeled truth file. Roughly 95% of the time, Universal-3 Pro was correct and the human label was wrong.
Artificial Analysis, a third-party benchmark provider, ran into the same issue. They built a proprietary dataset and manually corrected existing benchmarks like Earnings22 and Vox Populi because the original ground truth labels had too many errors.
The practical implication: if your WER is higher with Universal-3 Pro than Universal-2, don't assume the new model is performing worse. Go back and listen to the audio flagged as insertions. The model may be catching things the human transcriber originally missed. Semantic WER, which uses an LLM to evaluate transcription quality based on defined rules rather than exact string matching, is becoming a more meaningful evaluation method for this reason.
What's on the roadmap
A few capabilities are in active development, per the official Universal-3 Pro product page:
- Streaming support for Universal-3 Pro: A fully promptable streaming version is in development. The plan is to support dynamic prompting for voice agents, where transcription behavior can be adjusted on the fly based on conversation context.
- Speaker diarization for streaming: Native diarization support for real-time use cases is in the works.
- Improved native audio tagging: The goal is to make non-speech audio tagging a stable, consistent API-level feature rather than a prompt-dependent behavior.
- More languages: Expanded language support beyond the current six (English, Spanish, French, German, Italian, Portuguese) is planned as part of ongoing model development.
Final words
Prompting gives you precise control over how Universal-3 Pro interprets and represents audio. Whether you're capturing every disfluency, preserving mixed-language speech, or flagging uncertain segments for human review, the techniques here apply directly to production use cases. The model rewards specificity, so start with one instruction, evaluate the output, and build from there. More languages, streaming support, and native audio tagging are on the way.
Frequently asked questions
What is Universal-3 Pro? Universal-3 Pro is AssemblyAI's most advanced speech language model and the first production-quality, promptable model purpose-built for speech tasks. You can include a plain-language instruction alongside your transcription request to customize how the model handles speech patterns, language, uncertainty, and more.
How do I transcribe disfluencies like "um" and "uh" with Universal-3 Pro? Include this prompt: Mandatory: Preserve linguistic speech patterns including disfluencies, filler words, hesitations, repetitions, stutters, false starts, and colloquialisms. Specificity matters, listing out the exact patterns you want will produce better results than using the word "disfluencies" alone.
Can Universal-3 Pro handle multiple languages in one audio file? Yes. Add this instruction to your prompt: Preserve the original language(s) and script as spoken, including code-switching and mixed-language phrases. Universal-3 Pro currently supports English, Spanish, French, German, Italian, and Portuguese, with additional languages on the roadmap.
What's the difference between Keyterms Prompting and open-field prompting in Universal-3 Pro? Keyterms Prompting boosts accuracy for specific known words or names (up to 1,000 words/phrases, at +$0.05/hr). Open-field prompting gives the model behavioral instructions for how to transcribe (also +$0.05/hr). Use Keyterms Prompting when you know what's in the audio; use open-field prompting when you don't. You can also include key terms inside your open-field prompt to combine both.
How much does Universal-3 Pro cost? Universal-3 Pro is priced at $0.21/hour. Open-field prompting is available as an add-on at $0.05/hour. Keyterms Prompting is a separate add-on also at $0.05/hour. Volume discounts are available, contact sales@assemblyai.com for details.
Why is my word error rate higher with Universal-3 Pro than Universal-2? In many cases, Universal-3 Pro is outperforming the human-labeled truth file used for comparison. Before assuming lower performance, listen back to the audio flagged as insertions. The model may be transcribing things a human transcriber originally missed.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts