
Speech
Understanding
Transform raw transcripts into structured, actionable data. These pre-built, LLM-powered features turn transcripts into intelligence instantly.























Powering the world’s most trusted Voice AI products
Your product experience is only as good as the foundation that powers it. Make sure you build on the best.
The accuracy and quality that Voice AI apps require
Our speech-to-text models redefine what quality means for Voice AI by delivering transcripts that are consistently trustworthy, and built for real-world performance.
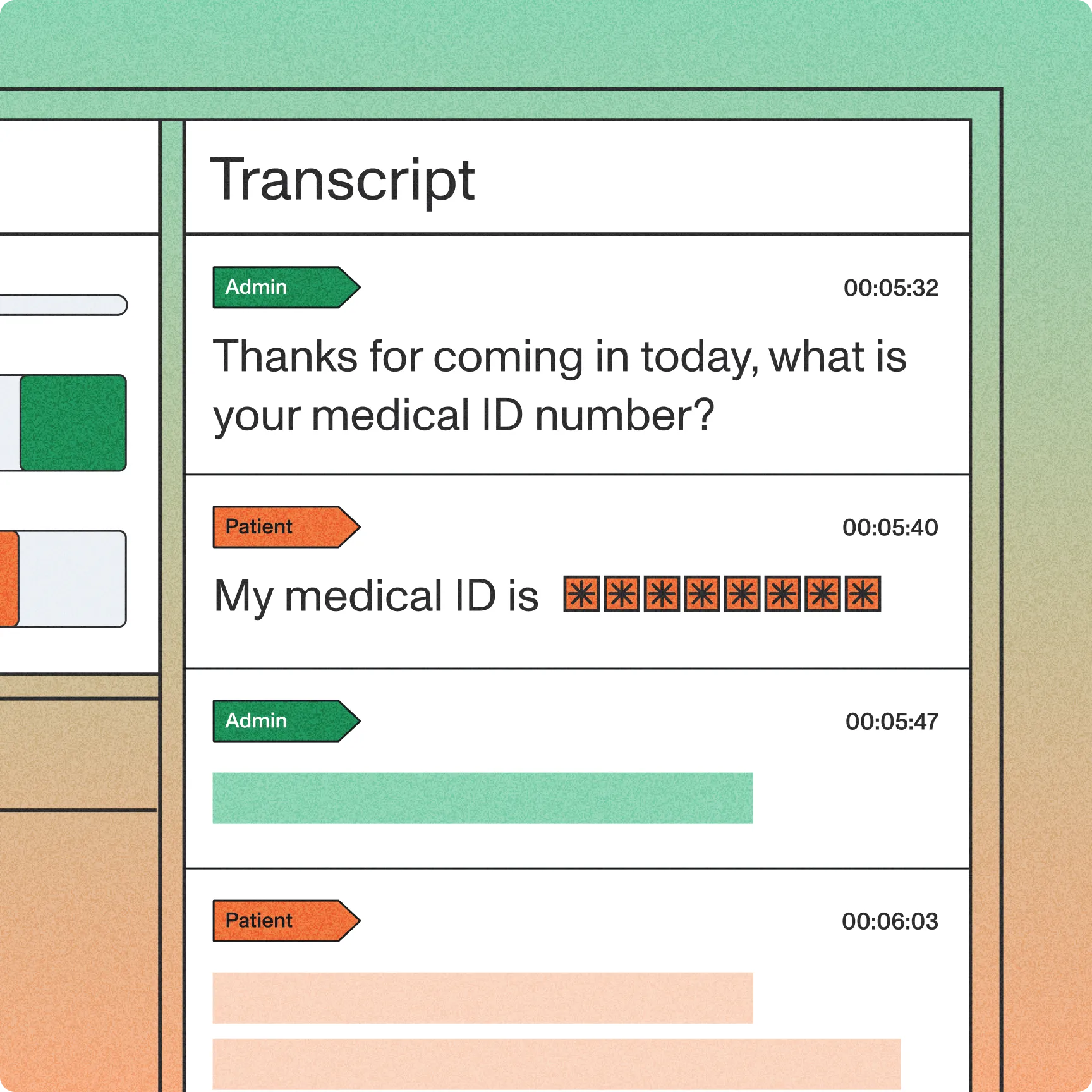
 Capture meaning, not just sound with contextual prompting across every conversation
Capture meaning, not just sound with contextual prompting across every conversation- 57% better recognition of key terms like names, codes, and medical terms
- 64% reduction in speaker counting errors compared to competitors
- 1500+ word context-aware prompting for domain expertise compared to other leading speech-to-text models

Don't just transcribe speech, understand it
Analyze dialog flow and speaker relationships to capture who is speaking, what they mean, and why it matters.
- Track dialogue and speaker context across turns for natural comprehension, labeling speakers by name or role
- Resolve ambiguity automatically — distinguishing between similar terms and acronyms
- Capture non-speech audio events, tone, corrections, and implied meaning to preserve intent
- Ensure reliable performance in overlapping, multi-speaker, and noisy environments
Reliable performance across the globe
We speak your customers' language, so you can serve a global customer base.
- 99-language support with automatic detection and code-switching between English and other languages
- Adapt to regional accents, dialects, and cultural expressions
- Language aware formatting for global date, number, and punctuation standards
- Handle medical, legal, and technical terms easily with specialized vocab and use-case specific prompting
A single platform for all things Voice AI
Innovate, ship, and scale faster than ever, all on a developer-first API.
- Unified speech-to-intelligence pipeline through LLM Gateway
- Seamlessly integrate with leading LLMs, including OpenAI, Anthropic, and Google
- Reliable, enterprise-grade infrastructure with zero rate limits
- No contract, usage-based pricing that's built to scale with you
Feature-rich AI models

Leverage our AI-powered Translation models to transcribe languages in your products at scale automatically. Supporting over 99 languages.
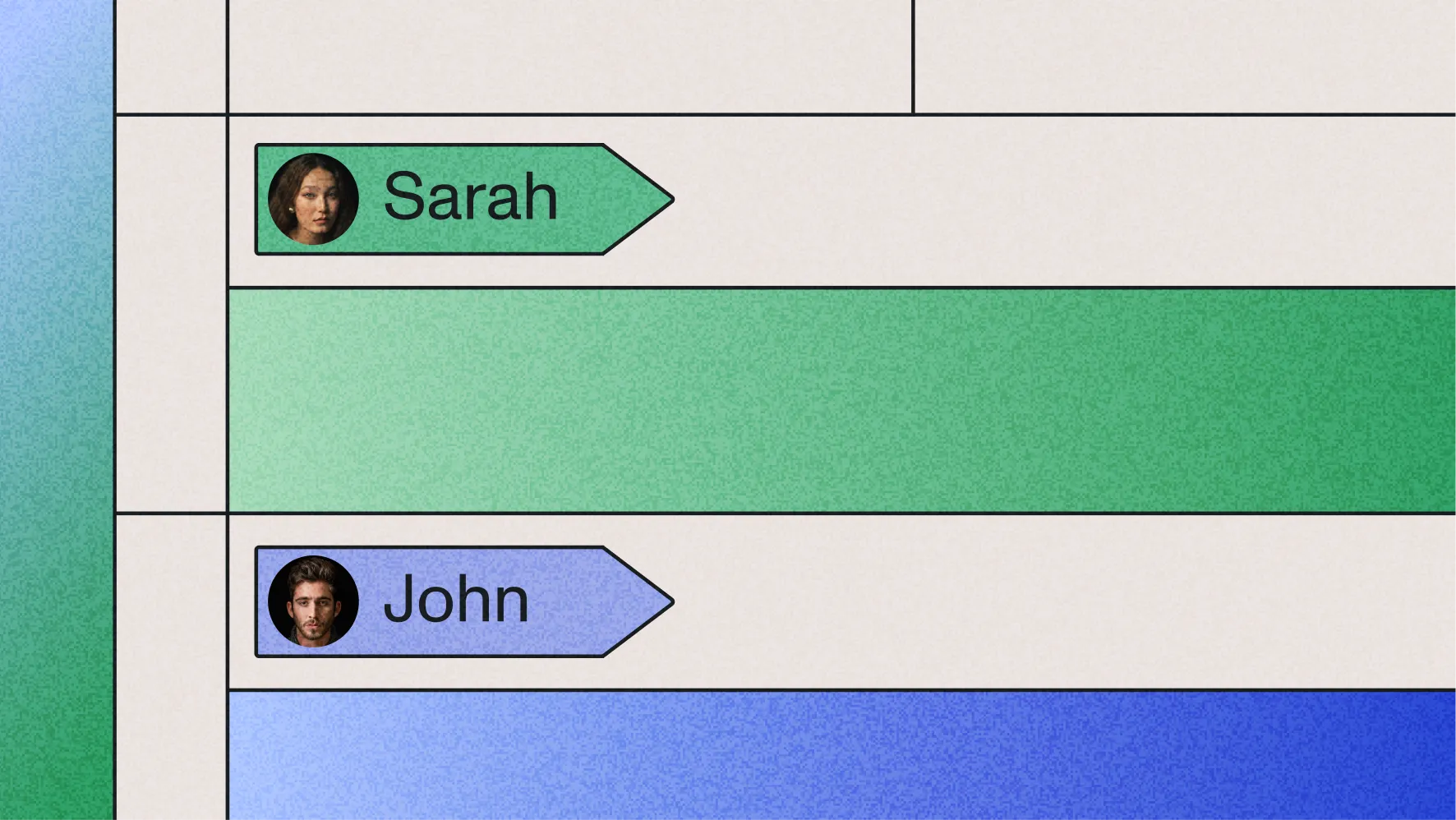
Go beyond "Speaker A" and "Speaker B" by leveraging our Advanced Speaker Identification, labeling speakers by name through audio context.
.avif)
Automatically detect and normalize key text elements in transcripts — including dates, phone numbers, and email addresses — to standardized, machine-readable formats.

Leverage our AI-powered Summarization models to automatically summarize audio/video data in your products at scale. Customize the summary types to best fit your use case.

With Sentiment Analysis, AssemblyAI can detect the sentiment of each sentence of speech spoken in your audio files.

Identify a wide range of entities that are spoken in your audio files, such as person and company names, email addresses, dates, and locations.

Label the topics that are spoken in your audio and video files. The predicted topic labels follow the standardized IAB Taxonomy, which makes them suitable for contextual targeting.

Automatically generate a summary over time for audio and video files.

Accurately identify significant words and phrases, enabling you to extract the most pertinent concepts or highlights from your audio/video file.
Built on Voice AI infrastructure that scales with you
Universal-3 Pro is part of AssemblyAI's complete Voice AI platform, featuring everything you need to build, deploy, and scale Voice Applications
Predictable usage-based pricing
Pay only for what you use with transparent per-second billing. No minimum commitments, annual contracts, or surprise infrastructure costs.
Complete Voice AI
Platform
Access constantly improving models plus the complete toolchain for every voice use case, from transcription to speech-to-speech, all through our Voice AI Cloud.
Proven reliability and security
Deploy with confidence on infrastructure that processes millions of hours daily. Built for production scale with 99.9% uptime and SOC 2 compliance.
The most loved AI apps are built on AssemblyAI
Learn why today’s most innovative companies choose us.



Frequently Asked Questions
Speech Understanding applies LLM‑powered tasks to completed transcripts via the LLM Gateway. You send a transcript_id and a speech_understanding.request (e.g., translation, speaker_identification, custom formatting). The service returns the original transcript augmented with structured outputs, like translated texts and updated utterance speaker labels, so raw text becomes machine‑readable, actionable fields for downstream workflows.
AssemblyAI first diarizes audio into speaker clusters using embeddings. Then Advanced Speaker Identification maps these clusters to real names or roles via the Speech Understanding API, using audio context and optional known_values you provide. Enable speaker_labels and request speaker_identification to return utterances labeled by name.
Yes. AssemblyAI lets you choose summary types and styles. Set summary_type to bullets, bullets_verbose, gist, headline, or paragraph, and pair it with a summary_model (informative, conversational, or catchy). If you specify one, you must specify the other. For fully custom formats, use LeMUR via LLM Gateway.
Get an AssemblyAI API key. Create a transcript (POST /v2/transcript). Add Speech Understanding either: 1) inline—include speech_understanding.request (e.g., translation) in the transcription request, or 2) after—POSThttps://llm-gateway.assemblyai.com/v1/understanding with transcript_id and your speech_understanding.request. Tasks include translation, speaker identification, and custom formatting.
Speech Understanding is billed by audio duration and the models you enable. Pay‑as‑you‑go per hour: Speaker Identification $0.02, Translation $0.06, Custom Formatting $0.03, Entity Detection $0.08, Sentiment Analysis $0.02, Auto Chapters $0.08, Key Phrases $0.01, Topic Detection $0.15, Summarization $0.03.
Speech Understanding runs on the transcript produced by the speech-to-text model you choose. For pre-recorded audio, it works with Universal (default) or Slam‑1. You can specify the model in your request, and pricing follows the model used.
Unlock the value of voice data
Build what’s next on the platform powering thousands of the industry’s leading of Voice AI apps.


