AssemblyAI Voice Agent API vs OpenAI Realtime API: Which should you use?
An honest comparison of AssemblyAI's Voice Agent API and OpenAI's Realtime API—covering architecture, speech accuracy, pricing ($4.50/hr vs. ~$18/hr), developer experience, and when to choose each.



OpenAI's Realtime API was one of the first products to make building voice agents feel accessible. Stream audio in, get audio back—simple idea, big impact. But as developers move from prototype to production, a different set of requirements kicks in: speech accuracy on real-world entities, cost predictability, and a developer experience that doesn't fight you.
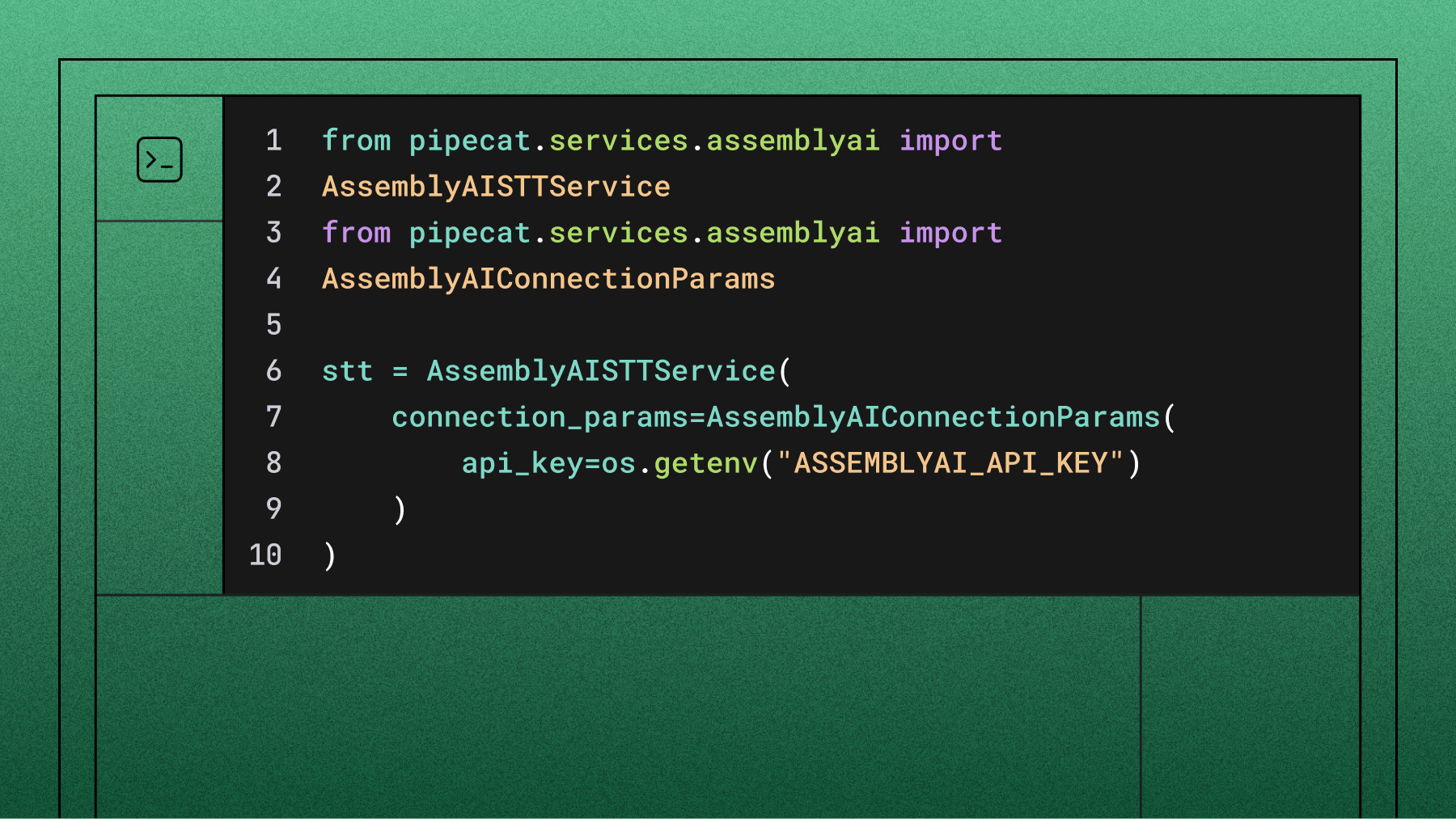
AssemblyAI's Voice Agent API launched in April 2026 as a direct alternative—same simplicity, fundamentally different architecture. Here's an honest comparison of the two.
Architecture: multimodal vs. dedicated pipeline
This is the foundational difference, and everything else flows from it.
OpenAI's Realtime API uses GPT-4o as a single multimodal model. Audio goes in, audio comes out, and one model handles speech understanding, reasoning, and voice generation all at once. It's architecturally clean, and if you're already building on OpenAI, it feels like a natural extension.
AssemblyAI uses a dedicated pipeline: Universal-3 Pro Streaming for speech-to-text (ranked #1 on the Hugging Face Open ASR Leaderboard), a separate LLM for reasoning, and purpose-built TTS for voice generation. Each model is optimized for its specific job.
Why does this matter? Because a model that also handles text, images, and video isn't specifically tuned for the nuances of speech. Turn detection, entity accuracy on names and numbers, handling disfluencies and accented speech—these improve when the model is purpose-built for listening, not doing everything at once.
Speech accuracy: where the gap is real
Voice agents live or die by what they hear. If the speech-to-text layer gets an email address wrong, the agent sends a confirmation to the wrong inbox. If it misses a digit in an account number, the agent looks up the wrong record.
AssemblyAI's Universal-3 Pro Streaming model achieves 94.07% word accuracy on real-world audio, with a 6.3% mean word error rate across English domains—the lowest among major providers in independent benchmarks. On entity accuracy specifically, Universal-3 Pro Streaming has a 16.7% average missed entity rate on names, emails, phone numbers, and credit card numbers. Compare that to OpenAI GPT-4o Transcribe at 23.3% and Deepgram Nova-3 at 25.2%. In head-to-head benchmarks, Universal-3 Pro Streaming shows a 59.64% lower missed email rate and 34.79% lower missed phone rate compared to competitors.
That gap might look small on paper. In practice, it's the difference between an agent that captures "RX-7704132" correctly and one that transcribes "dash seven seven zero four one three two." When your agent acts on that transcript, accuracy isn't a nice-to-have—it's the whole game.
For specialized domains, AssemblyAI also offers Medical Mode that enhances accuracy on clinical terminology—medication names, procedures, dosages. OpenAI doesn't have an equivalent specialized mode.
Pricing: $4.50/hr vs. ~$18/hr
This is the most straightforward comparison.
AssemblyAI's Voice Agent API costs $4.50/hr flat. That covers everything—speech understanding, LLM reasoning, and voice generation. No per-token math, no separate input/output charges. Your monthly cost is simply: hours of agent usage times $4.50.
OpenAI's Realtime API uses per-token billing for both input and output audio tokens. When you do the math on a typical voice agent conversation, that comes out to roughly $18/hr—about 4x the cost.
At prototype scale, both are affordable. At production scale, the difference compounds fast. A customer support operation running 5,000 hours of agent conversations per month is looking at $22,500/month with AssemblyAI vs. $90,000/month with OpenAI. That's $67,500/month in savings—enough to fund an entire engineering team.
Developer experience
OpenAI's Realtime API has over 30 event types to handle. For developers who want fine-grained control over every aspect of the audio stream, that's powerful. For developers who want to get a voice agent running quickly, it's a lot of surface area.
AssemblyAI's approach is deliberately minimalist. One WebSocket, a handful of JSON message types, and the entire API reference is readable in about 10 minutes. Most developers ship a working agent the same day. No SDK required—it works with any WebSocket client and integrates natively with tools like Claude Code.
The standout feature is live mid-conversation updates. You can change the system prompt, swap voices, add or remove tools, and adjust VAD settings—all via a JSON message without dropping the connection. OpenAI's Realtime API supports some mid-session configuration, but AssemblyAI's implementation is more comprehensive.
Tool calling works similarly in both: you register functions with JSON Schema, and the agent calls them when appropriate. AssemblyAI's agent speaks a natural transition while waiting for tool results, which keeps the conversation flowing.
Session resumption is another practical difference. If the WebSocket drops (mobile networks, flaky connections), AssemblyAI preserves context and lets you reconnect within 30 seconds. That's critical for phone-based voice agents where network reliability isn't guaranteed.
Turn detection and conversation flow
This is where you really feel the architectural difference.
AssemblyAI's Voice Agent API uses speech-aware Voice Activity Detection built into the Universal-3 Pro Streaming model. Rather than relying solely on silence thresholds, Universal-3 Pro Streaming uses audio-contextual signals—tonality, pacing, and speech patterns—to determine when a speaker is done. It distinguishes between a thoughtful pause and a conversation ending—so the agent doesn't cut you off mid-thought, and it doesn't sit in dead air for three seconds waiting for you to continue. When you interrupt, it stops and listens naturally.
OpenAI's turn detection relies on more basic VAD that lacks the acoustic sophistication of a purpose-built speech model. The conversation intelligence that comes from a dedicated STT layer shows up most clearly in turn-taking quality.
The honest test: have a real conversation with both. The difference in how natural the interaction feels is something you notice immediately, even if it's hard to put numbers on it.
When to choose each
Choose AssemblyAI's Voice Agent API when:
You need the highest speech accuracy on entities (names, numbers, addresses). You want predictable flat-rate pricing. You want the simplest possible developer experience. You're building for production scale where cost matters. You need healthcare compliance with Medical Mode.
Choose OpenAI's Realtime API when:
You're deeply embedded in OpenAI's ecosystem and value API consistency across products. You need broader language support beyond 6 languages. You want a single-model architecture for simplicity (at the cost of speech-specific optimization). Cost isn't the primary concern.
For most production voice agent use cases—customer support, phone agents, clinical workflows, coaching platforms—AssemblyAI's combination of superior speech accuracy, 4x lower cost, and simpler developer experience makes it the stronger choice.
Frequently asked questions
How much cheaper is AssemblyAI's Voice Agent API compared to OpenAI's Realtime API?
AssemblyAI's Voice Agent API costs $4.50/hr flat, covering speech understanding, LLM reasoning, and voice generation. OpenAI's Realtime API costs approximately $18/hr with per-token billing. That's roughly a 4x cost difference—at 5,000 hours/month of agent usage, the savings exceed $67,000/month.
Which has better speech accuracy for voice agents—AssemblyAI or OpenAI?
AssemblyAI's Universal-3 Pro Streaming model achieves 94.07% word accuracy and a 16.7% average missed entity rate on names, emails, phone numbers, and credit card numbers. OpenAI GPT-4o Transcribe scores 93.13% word accuracy with a 23.3% missed entity rate. Universal-3 Pro Streaming also shows 59.64% fewer missed emails and 34.79% fewer missed phone numbers—the entities voice agents actually act on.
What's the difference between a multimodal and a cascaded voice agent architecture?
OpenAI uses a single multimodal model (GPT-4o) for speech understanding, reasoning, and voice generation. AssemblyAI uses a cascaded pipeline with dedicated models for each step—Universal-3 Pro Streaming for STT, a separate LLM for reasoning, and purpose-built TTS. The cascaded approach delivers better speech accuracy because each model is optimized for its specific task.
Can I migrate from OpenAI's Realtime API to AssemblyAI?
Yes. AssemblyAI's Voice Agent API uses a standard WebSocket with JSON messages—most developers get a working agent running in an afternoon, even when migrating from a different provider. Tool definitions transfer easily since both use JSON Schema. The main adjustment is the simpler event model (fewer event types to handle).
Does AssemblyAI's Voice Agent API support the same languages as OpenAI?
AssemblyAI currently supports 6 languages: English, Spanish, French, German, Italian, and Portuguese. OpenAI's Realtime API supports a broader set through GPT-4o's multilingual capabilities. If your use case requires languages beyond AssemblyAI's current 6, check both providers' documentation as language support is actively expanding.
Which voice agent API is better for healthcare applications?
AssemblyAI has a clear advantage for healthcare with Medical Mode—a dedicated add-on that enhances accuracy on medical terminology (medication names, procedures, dosages). AssemblyAI enables covered entities and their business associates subject to HIPAA to use AssemblyAI services to process protected health information (PHI), with a Business Associate Addendum (BAA) available. Combined with SOC 2 Type 2 certification, it's purpose-built for clinical voice agent workflows. OpenAI offers SOC 2 compliance but no equivalent medical speech optimization.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts