Build your first AI voice agent: 3 step-by-step examples
In this article, we’ll walk you through three hands-on tutorials from AssemblyAI’s YouTube channel, each offering a different approach to building your own AI voice agent tech stack—from low-code platforms to full Python implementations.



2025 is turning out to be the year of the AI voice agent—top companies are already integrating agents to make phone calls, answer questions, and handle business-critical tasks in real time. Whether it’s scheduling appointments, resolving customer issues, or even tutoring users on complex subjects, AI voice agents are increasingly part of our daily digital interactions.
In this article, we’ll walk you through three hands-on tutorials from AssemblyAI’s YouTube channel, each offering a different approach to building your own AI voice agent tech stack—from low-code platforms to full Python implementations. These examples are perfect for developers or product teams ready to start playing with real-time AI today.
Common use cases
AI voice agents are already transforming a wide range of industries:
- Customer service for AI-powered call centers: Handling inbound calls and reducing wait times
- Sales and training: Role-play training for call center agents and salespeople
- Meeting and conversation intelligence: Capturing notes, action items, and generating summaries
- Healthcare: Patient scheduling and basic information gathering
Entertainment: Interactive conversational experiences with fictional characters
Hands-on tutorials to build your AI voice agent
These tutorials cover everything from building with managed platforms to fully customizable, code-driven implementations. Choose the approach that fits your project and skill level.
Example 1: Building an AI voice agent with Vapi & AssemblyAI
In this example, you’ll use Vapi—a platform that streamlines the process of building, testing, and deploying AI voice agents. It acts as an orchestrator between AI models like AssemblyAI for transcription and others for LLM and TTS (text to speech), and provides tools to turn these models into production-ready voice agents with monitoring capabilities.
The dashboard also lets you monitor latency, costs, and conversation flow—all critical for delivering smooth, natural interactions.
Requirements
To use Vapi's platform, you need:
- Access to Vapi's platform (vapi.ai)
- API keys for the services you want to integrate (optional, as Vapi offers accounts with preferred pricing)
- Basic understanding of conversation design
Core components
Vapi's platform offers a unified dashboard that includes:
- Model Selection and Configuration:
- Speech-to-text providers (including AssemblyAI)
- Large language models (Claude, GPT, etc.)
- Text-to-speech providers
- Workflow Builder:
- Structured conversation flows as an alternative to prompts
- Step-by-step blocks including: say something, gather information, make API requests, transfer calls, and conditional logic
- Tools and Integrations:
- API connections to external systems
- Custom voice selection and training options
A key advantage of Vapi's workflow approach is that it helps prevent LLM hallucinations by creating more structured conversations. Instead of relying solely on prompts, which can lead models to go off-track, workflows provide step-by-step conversation guides.
Example 2: Building an AI voice agent with DeepSeek R1
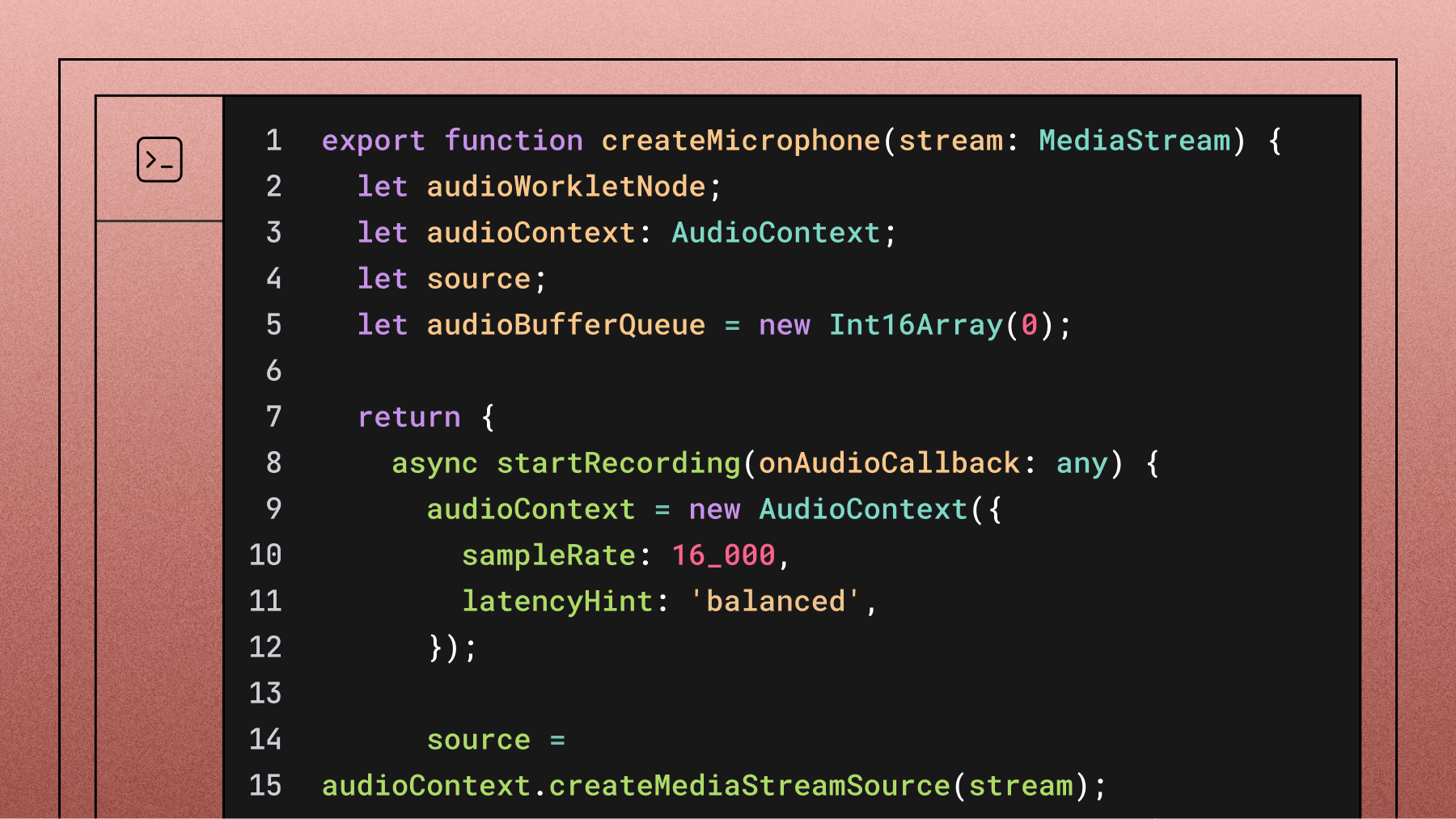
In the second example, you’ll build an AI voice agent in Python using real-time speech recognition and DeepSeek's R1 model. What makes this implementation special is R1's reasoning capabilities—the model explains its chain of thought as it formulates answers, which helps with complex problem-solving like coding challenges or math problems.
This approach uses DeepSeek's R1 model running locally through Ollama, with AssemblyAI handling real-time transcription and ElevenLabs providing text-to-speech capabilities. The implementation is Python-based and requires setting up several components to work together.
Requirements
To implement this voice agent, you need:
- AssemblyAI API key for real-time speech-to-text
- Ollama installed to run the DeepSeek R1 model locally
- ElevenLabs API key for text-to-speech
- PortAudio (pre-installed on Windows, manual installation for Linux/Mac)
- Python packages: assemblyai, ollama, eleven_labs, and mvp for Mac users
Core components
The implementation includes the following components:
- AIVoiceAgent Class:
- Initializes the necessary API keys and components
- Maintains a transcript object to keep conversation context
- Real-time Speech Processing:
- Real-time transcriber using AssemblyAI's API
- Event handlers for processing different types of transcripts (partial vs. final)
- LLM Integration:
- Integration with the DeepSeek R1 model via Ollama
- Processing of responses through ElevenLabs for text-to-speech
- Maintains conversation context by appending to the full transcript
Note that the voice agent is designed to continuously listen for user input. When the user speaks, the system captures partial transcripts as individual words. When the user pauses for more than 700 milliseconds, the system considers it a "final transcript" and sends the complete question to the DeepSeek R1 model. The model processes the question and explains its reasoning process, which is converted to speech and played back to the user.
Example 3: Building an AI agent with LiveKit for real-time speech-to-text
In the last example, you’ll build an AI agent for real-time speech-to-text in web applications using LiveKit. LiveKit is a platform for building real-time audio and video applications that abstracts away many complex details of real-time communication, making it easier to build performant applications.
LiveKit provides a flexible agent system for rapidly building AI agents and incorporating them into applications. At the core of a LiveKit application is a server that manages participants connecting to "rooms" (real-time sessions). Participants can publish and subscribe to data streams called "tracks" which are commonly audio or video, but can be any arbitrary data.
Requirements
To implement this solution, you need:
- A LiveKit server (self-hosted or using LiveKit Cloud)
- An AssemblyAI API key with billing set up for streaming speech-to-text
- Python installed with these packages: livekit-server-sdk, livekit-plugins-assembly, python-dotenv
Core components
The implementation includes:
- LiveKit Architecture:
- LiveKit server managing the real-time session
- Participants connecting to "rooms"
- Data streams called "tracks" that can be published and subscribed to
- Agent Implementation:
- Entry point function executed when the agent connects to the room
- Track subscription handling for new audio tracks
- Audio stream processing and forwarding to AssemblyAI
- Transcript processing and forwarding back to the LiveKit room
Note that when the agent connects to the LiveKit room, it automatically subscribes to every audio track published to the room. For each track, the agent creates an asynchronous task that simultaneously pushes audio frames to AssemblyAI and receives transcription events back. Final transcripts are printed to the console and forwarded to the LiveKit room, where they appear in the chat feature of the front-end application.
Choosing your path and what's next?
Not sure where to start? Here’s how to choose:
- Need the fastest deployment? Try Vapi (Example 1).
- Want full Python control with local LLM? Try DeepSeek R1 (Example 2).
- Want to use open source and engage with community? Try LiveKit (Example 3).
Here are the best next steps to take if you’re considering developing a voice agent:
- Try the code/setup yourself
- Explore the documentation for the tools used
- Think about customizing the agent for a specific use case
Check out other relevant tutorials or resources on the AssemblyAI YouTube channel and blog.
Start building AI voice agents
With platforms like Vapi, open models like DeepSeek R1, and powerful APIs like AssemblyAI, you can build responsive, real-time voice agents that make a real impact.
Ready to build your own? Watch the tutorials, try the code, and start experimenting today—we’d love to hear what you create.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts