How to build an AI-Powered interview scoring system with speech-to-text
This tutorial shows you how to build an AI-powered interview scoring system that records interviews, converts speech-to-text, and systematically evaluates candidates using structured criteria.



This tutorial shows you how to build an AI-powered interview scoring system that records interviews, converts speech-to-text, and systematically evaluates candidates using structured criteria. Instead of frantically taking notes while trying to listen and assess simultaneously, you'll separate interviewing from scoring—conduct natural conversations first, then analyze complete transcripts afterward with objective evidence for every evaluation.
You'll use Python with AssemblyAI's speech-to-text API to transcribe interviews with speaker separation, then implement automated scoring algorithms that search transcripts for competency evidence. The system generates detailed scorecards with supporting quotes, timestamps, and numerical ratings for each skill you're evaluating. By the end, you'll have a complete workflow that transforms subjective interview assessments into data-driven hiring decisions backed by verifiable evidence from actual candidate responses.
What is an AI-powered interview scoring system?
An AI-powered interview scoring system is a structured tool that records your interviews, turns the audio into text, and then searches for evidence of specific skills. This means you can focus entirely on the conversation during interviews, then analyze what was said afterward using the complete transcript.
Here's how it works: You record the interview, upload the audio file to a speech-to-text API, get back a transcript with speaker labels, and then search for quotes that prove or disprove each skill you're evaluating. Instead of frantically taking notes while trying to listen, you have every word preserved for careful analysis.
Traditional interview scoring happens while you're talking—you're trying to listen, take notes, and evaluate simultaneously. AI-powered scoring separates these tasks completely. You interview first, then score later using the full transcript.
Core components: Criteria, scale, evidence, and transcripts
Every interview scoring system needs four parts working together. First, you define what skills matter for the job—usually 4 to 6 specific competencies like problem-solving or technical knowledge.
Second, you create a 1-5 rating scale where each number means something specific. Third, you extract evidence from the transcript—actual quotes where candidates demonstrate each skill. Fourth, you use complete transcripts as your single source of truth instead of handwritten notes.
- Scoring criteria: Job-specific skills you can observe in answers
- Rating scale: Clear definitions for scores 1 through 5
- Evidence extraction: Direct quotes that prove competency levels
- Complete transcripts: Every word said, with speaker labels and timestamps
The manual scoring challenge: Bias, recall, and inconsistency
Manual scoring during interviews creates three problems that hurt your hiring decisions. You experience cognitive overload when trying to listen, evaluate, and take notes at the same time—your brain can't do all three tasks well simultaneously.
Memory-based scoring means you forget details from earlier in the interview. You might miss a brilliant answer from minute 10 if the candidate stumbles at minute 45. Different interviewers also interpret the same response differently—one person's "strong communication" is another's "adequate explanation."
Benefits of transcript-based scoring
Transcript-based scoring gives you four key advantages over manual evaluation:
- Complete evidence: Every claim in your evaluation links to an actual quote
- Reduced bias: All evaluators review identical information instead of different notes
- Legal protection: Timestamped evidence supports your hiring decisions if challenged
- Time savings: Batch-process multiple interviews and share transcripts with your team
You can search transcripts for specific keywords, share them with other interviewers for second opinions, and create detailed scorecards with supporting evidence for every rating.
How to build an AI-powered interview scoring system
Building your scoring system requires five sequential steps. Each step builds on the previous one, from defining what you're measuring to generating scores with supporting evidence.
Step 1: Define role-specific scoring criteria
Start by identifying 4 to 6 skills that directly predict success in the specific role you're hiring for. Don't use generic traits like "good communication"—these mean different things for different jobs.
For a software engineering role, focus on observable behaviors:
- How candidates break down complex technical problems
- Their approach to system design and architecture decisions
- Knowledge of relevant programming languages and frameworks
- Ability to explain technical concepts clearly
For a customer success role, look for different competencies:
- Specific techniques for handling difficult customer situations
- Methods for building trust and rapport with clients
- How quickly they learn new software systems
- Examples of influencing customer decisions
Write each competency as something you can identify in interview responses. Instead of "leadership potential," use "describes specific examples of mentoring team members or influencing technical decisions."
Step 2: Choose your rating scale
Use a 5-point scale with clear definitions for each score. This gives you enough detail without overwhelming evaluators with too many options.
Score 1 - Far Below Requirements: No evidence of competence, avoided the question, or gave completely irrelevant answers
Score 2 - Below Requirements: Minimal understanding shown, vague responses without concrete examples
Score 3 - Meets Requirements: Adequate demonstration with at least one relevant, complete example
Score 4 - Exceeds Requirements: Strong evidence with multiple detailed examples or sophisticated understanding
Score 5 - Far Exceeds Requirements: Exceptional mastery with innovative approaches or profound insights
Don't use scales with more than 5 points. Research shows humans struggle to consistently differentiate between more than 5 levels, so a 10-point scale creates noise rather than precision.
Step 3: Set up interview recording and transcription
Quality transcription starts with quality audio recording. You need clear, separate audio for each speaker to get accurate transcripts with speaker labels.
Recording setup for video platforms:
- Zoom: Enable cloud recording with separate audio files for each participant
- Microsoft Teams: Use meeting recording, then download the MP4 file
- Google Meet: Install a recording extension or use OBS Studio for local capture
Audio quality requirements:
- Use external microphones instead of built-in laptop mics
- Test audio levels before each interview—aim for clear, consistent volume
- Record in quiet rooms with minimal background noise
- Save recordings in common formats like MP3, MP4, or WAV
Legal requirements:
- Inform candidates during scheduling that interviews will be recorded
- Get verbal consent at the start: "This interview will be recorded for evaluation purposes. Do you consent?"
- Follow your local laws—some states require consent from all parties
- Store recordings securely and delete them after making hiring decisions
Step 4: Configure AssemblyAI transcription (Python)
Now you'll implement the transcription system using Python and AssemblyAI's speech-to-text API. Start by installing the required packages:
pip install assemblyai python-dotenvCreate a .env file to store your API key securely:
ASSEMBLYAI_API_KEY=your_api_key_hereHere's a complete script to transcribe interviews with speaker labels:
# interview_transcriber.py
import assemblyai as aai
import json
import os
from datetime import datetime
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Configure AssemblyAI
aai.settings.api_key = os.getenv('ASSEMBLYAI_API_KEY')
def transcribe_interview(audio_file_path, candidate_name,
position):
"""
Transcribe an interview recording with speaker separation
Args:
audio_file_path: Path to your audio file
candidate_name: Name of the candidate
position: Job title being interviewed for
Returns:
Dictionary with transcript and metadata
"""
print(f"Starting transcription for {candidate_name}...")
# Configure transcription settings
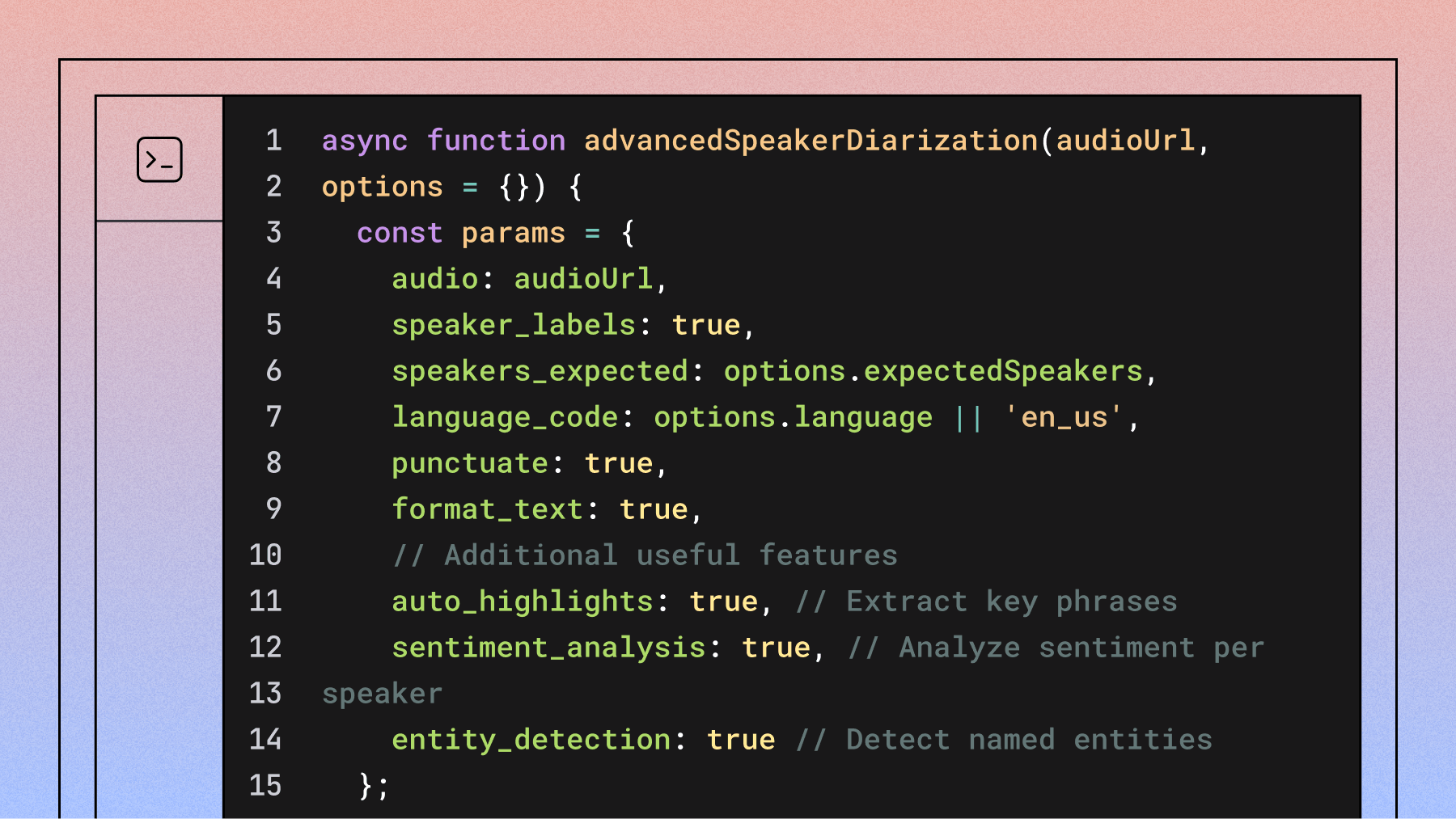
config = aai.TranscriptionConfig(
speech_model=aai.SpeechModel.best, # Use highest
accuracy model
speaker_labels=True, # Separate speakers
speakers_expected=2, # Interview has 2 people
punctuate=True, # Add punctuation
format_text=True # Proper capitalization
)
# Create transcriber and process file
transcriber = aai.Transcriber(config=config)
transcript = transcriber.transcribe(audio_file_path)
# Check if transcription succeeded
if transcript.status == aai.TranscriptStatus.error:
print(f"Transcription failed: {transcript.error}")
return None
print("Transcription completed successfully!")
# Extract speaker-labeled segments
utterances = []
for utterance in transcript.utterances:
utterances.append({
'speaker': utterance.speaker,
'text': utterance.text,
'start_time': utterance.start / 1000, # Convert to
seconds
'end_time': utterance.end / 1000,
'confidence': utterance.confidence
})
# Prepare results
result = {
'candidate_name': candidate_name,
'position': position,
'interview_date': datetime.now().strftime('%Y-%m-%d
%H:%M:%S'),
'duration_minutes': round(transcript.audio_duration / 60,
2),
'utterances': utterances,
'full_text': transcript.text
}
# Save transcript to JSON file
output_filename = f"{candidate_name.replace(' ',
'_')}_{position.replace(' ', '_')}.json"
with open(output_filename, 'w') as f:
json.dump(result, f, indent=2, ensure_ascii=False)
print(f"Transcript saved as {output_filename}")
return result
# Example usage
if __name__ == "__main__":
result = transcribe_interview(
audio_file_path="interview_recording.mp3",
candidate_name="Sarah Johnson",
position="Senior Developer"
)
if result:
print(f"Interview duration: {result['duration_minutes']} minutes")
print(f"Total utterances: {len(result['utterances'])}")
Key configuration options explained:
- speech_model=aai.SpeechModel.best: Uses AssemblyAI's highest accuracy model for optimal transcription quality
- speaker_labels=True: AssemblyAI automatically identifies different speakers and labels them consistently throughout the transcript
- speakers_expected=2: Optimizes the algorithm for two-person conversations (interviewer and candidate)
- punctuate=True: Adds periods, commas, and question marks to make the text readable
- format_text=True: Capitalizes proper nouns and sentence beginnings
AssemblyAI handles multiple audio formats automatically—you don't need to convert files before uploading. The API works with MP3, MP4, M4A, WAV, and other common formats.
Step 5: Extract evidence and calculate Sscores
With your transcript ready, you can now extract evidence for each competency and calculate scores. Here's a complete scoring system:
# interview_scorer.py
import json
import re
from typing import Dict, List, Tuple
class InterviewScorer:
def __init__(self, transcript_file: str):
"""Load transcript and prepare for scoring"""
with open(transcript_file, 'r') as f:
self.transcript_data = json.load(f)
# Extract candidate responses (usually Speaker B)
self.candidate_responses =
self._get_candidate_responses()
def _get_candidate_responses(self) -> List[str]:
"""Extract only the candidate's speech from transcript"""
responses = []
# Count how many times each speaker talks
speaker_counts = {}
for utterance in self.transcript_data['utterances']:
speaker = utterance['speaker']
speaker_counts[speaker] = speaker_counts.get(speaker,
0) + 1
# Candidate usually speaks less than interviewer
candidate_speaker = min(speaker_counts.keys(), key=lambda
x: speaker_counts[x])
# Get all candidate utterances
for utterance in self.transcript_data['utterances']:
if utterance['speaker'] == candidate_speaker:
responses.append(utterance['text'])
return responses
def find_evidence_for_competency(self, competency_keywords:
List[str]) -> List[str]:
"""
Find candidate responses that contain evidence of a competency
Args:
competency_keywords: List of words/phrases related to
the skill
Returns:
List of candidate quotes showing this competency
"""
evidence = []
for response in self.candidate_responses:
response_lower = response.lower()
# Check if response contains any competency keywords
keyword_matches = sum(1 for keyword
in competency_keywords
if keyword.lower() in response_lower)
# If response has keywords and is substantial,
include as evidence
if keyword_matches > 0 and len(response.split()) >
10:
evidence.append(response)
return evidence[:3] # Return top 3 pieces of evidence
def score_competency(self, evidence: List[str]) -> int:
"""
Calculate 1-5 score based on evidence quality and
quantity
Args:
evidence: List of quotes showing competency
Returns:
Score from 1 (poor) to 5 (excellent)
"""
if not evidence:
return 1 # No evidence found
evidence_count = len(evidence)
avg_length = sum(len(e.split()) for e in evidence) /
len(evidence)
# Score based on quantity and depth of evidence
if evidence_count == 1 and avg_length < 20:
return 2 # Minimal evidence
elif evidence_count <= 2 and avg_length < 30:
return 3 # Adequate evidence
elif evidence_count >= 2 and avg_length >= 30:
return 4 # Strong evidence
elif evidence_count >= 3 and avg_length >= 40:
return 5 # Exceptional evidence
else:
return 3 # Default to adequate
def generate_scorecard(self, competencies: Dict[str,
List[str]]) -> Dict:
"""
Generate complete scorecard with scores and supporting evidence
Args:
competencies: Dict mapping competency names to
keyword lists
Returns:
Complete scorecard with scores and evidence
"""
scorecard = {
'candidate': self.transcript_data['candidate_name'],
'position': self.transcript_data['position'],
'interview_date':
self.transcript_data['interview_date'],
'competency_scores': {},
'supporting_evidence': {},
'overall_score': 0
}
total_score = 0
for competency_name, keywords in competencies.items():
# Find evidence and calculate score
evidence =
self.find_evidence_for_competency(keywords)
score = self.score_competency(evidence)
# Store results
scorecard['competency_scores'][competency_name] =
score
scorecard['supporting_evidence'][competency_name] =
evidence
total_score += score
# Calculate overall average
scorecard['overall_score'] = round(total_score /
len(competencies), 1)
return scorecard
def save_scorecard(self, competencies: Dict[str, List[str]],
output_file: str):
"""Generate and save scorecard to JSON file"""
scorecard = self.generate_scorecard(competencies)
with open(output_file, 'w') as f:
json.dump(scorecard, f, indent=2, ensure_ascii=False)
# Print summary
print(f"\n=== Scorecard for {scorecard['candidate']}
===")
for competency, score in
scorecard['competency_scores'].items():
print(f"{competency}: {score}/5")
print(f"Overall Score: {scorecard['overall_score']}/5")
print(f"Detailed scorecard saved to {output_file}")
# Example usage
if __name__ == "__main__":
# Define competencies with relevant keywords
engineering_competencies = {
'Problem Solving': [
'analyze', 'debug', 'troubleshoot', 'solution',
'approach',
'investigate', 'root cause', 'systematic', 'break
down'
],
'Technical Skills': [
'python', 'javascript', 'react', 'database', 'api',
'algorithm', 'architecture', 'testing', 'performance'
],
'Communication': [
'explain', 'clarify', 'example', 'understand',
'question',
'discuss', 'present', 'document', 'feedback'
],
'Experience': [
'project', 'team', 'lead', 'built', 'developed',
'implemented', 'managed', 'delivered', 'worked on'
]
}
# Score the interview
scorer =
InterviewScorer('Sarah_Johnson_Senior_Developer.json')
scorer.save_scorecard(engineering_competencies,
'sarah_johnson_scorecard.json')
This system searches candidate responses for keywords related to each competency, then scores based on the quantity and depth of evidence found. You can customize the keywords for different roles and adjust the scoring logic based on your needs.
For more sophisticated analysis, you can integrate with language models through AssemblyAI's LLM Gateway:
# Advanced scoring with AssemblyAI LLM Gateway
import requests
import os
def score_with_llm(self, competency: str, candidate_responses: str) -> dict:
"""Use AssemblyAI LLM Gateway to analyze responses for
specific competency"""
prompt = f"""Analyze these interview responses for evidence
of {competency}.
Candidate responses:
{candidate_responses}
Provide:
1. Score from 1-5 (1=no evidence, 5=exceptional evidence)
2. Three best quotes demonstrating this skill
3. Brief explanation of your score
Respond in JSON format."""
headers = {
'authorization': os.getenv('ASSEMBLYAI_API_KEY'),
'Content-Type': 'application/json'
}
response = requests.post(
'https://llm-gateway.assemblyai.com/v1/chat/completions',
headers=headers,
json={
'model': 'claude-sonnet-4-20250514',
'messages': [
{
'role': 'user',
'content': prompt
}
],
'max_tokens': 1000,
'temperature': 0.1
}
)
return response.json()['choices'][0]['message']['content']Common implementation mistakes to avoid
Three critical mistakes can undermine your scoring system and lead to poor hiring decisions.
Using one-size-fits-all criteria
Don't use the same competencies for every role—"communication skills" means different things for a backend engineer versus a sales representative. A data scientist needs to explain statistical concepts to non-technical stakeholders, while a customer support agent needs empathy and de-escalation techniques.
Instead, analyze your top performers in each role and identify what makes them successful. If your best engineers excel at code reviews, include "provides constructive technical feedback" rather than generic "teamwork." If your top salespeople ask great discovery questions, look for "uses strategic questioning to uncover customer needs."
Skipping interviewer calibration sessions
Even with transcripts and defined scales, different evaluators interpret evidence differently without alignment. One person's "strong problem-solving" is another's "basic analysis" because everyone brings different expectations.
Schedule monthly calibration sessions where all interviewers score the same sample transcript independently, then discuss differences. When scores differ by more than one point, dig into why. These conversations surface hidden assumptions and align your team on what each score level actually means.
Neglecting audio quality requirements
Poor audio quality ruins everything downstream—inaccurate transcripts lead to missed evidence and unreliable scores. A transcript with even 20% errors can completely change the meaning of technical explanations or miss key competency indicators.
Set strict quality standards and test them:
- Test recording setup before every interview
- Require external microphones for all participants
- Use wired internet connections to prevent audio dropouts
- Record practice sessions to verify audio clarity
- Reject and reschedule interviews with poor audio quality
One garbled explanation of a technical concept can change a candidate's score from "exceeds expectations" to "below requirements" if key terms are mistranscribed.
How to measure interview scoring system effectiveness
Track four metrics to validate that your system improves hiring decisions and reduces inconsistency between interviewers.
Time-to-Hire: Measure days from job posting to offer acceptance. Structured scoring should speed up decision-making because you have clear evidence for each decision.
Quality of Hire: Track new hire performance ratings after 6 months on the job. Higher-scored candidates should perform better if your system accurately predicts success.
Inter-Rater Reliability: Calculate agreement between different evaluators scoring the same interview. Use Cohen's Kappa coefficient—scores above 0.7 indicate good agreement.
Score Distribution: Check if scores spread appropriately across candidates. If everyone clusters around the same score, your criteria might be too generic or your scale needs adjustment.
Here's Python code to calculate inter-rater reliability:
from sklearn.metrics import cohen_kappa_score
def calculate_agreement(evaluator1_scores, evaluator2_scores):
"""Calculate Cohen's Kappa for inter-rater agreement"""
kappa = cohen_kappa_score(evaluator1_scores,
evaluator2_scores)
if kappa < 0.4:
agreement_level = "Poor agreement - needs calibration"
elif kappa < 0.6:
agreement_level = "Fair agreement - some calibration needed"
elif kappa < 0.8:
agreement_level = "Good agreement - system working well"
else:
agreement_level = "Excellent agreement - very consistent"
return kappa, agreement_level
# Example
eval1_scores = [3, 4, 5, 2, 4, 3, 5, 4]
eval2_scores = [3, 5, 4, 2, 3, 3, 4, 4]
kappa, interpretation = calculate_agreement(eval1_scores,
eval2_scores)
print(f"Agreement score: {kappa:.2f} - {interpretation}")
Track these metrics before and after implementing your system to measure improvement. Most teams see better consistency and faster decision-making within a few months of adoption.
Final words
This transcript-based approach transforms interview scoring from a subjective, memory-dependent process into an objective, evidence-based system. You record interviews to capture every detail, transcribe them to create searchable text, then systematically extract evidence for each competency you're evaluating. This separation of interviewing and scoring lets you focus entirely on the conversation while ensuring thorough, consistent evaluation afterward.
AssemblyAI's speech-to-text models excel at handling the diverse accents, technical terminology, and conversational speech patterns common in interviews. Features like speaker diarization automatically separate interviewer and candidate speech, while high accuracy rates ensure your evidence extraction reflects what was actually said rather than transcription errors. When hiring decisions depend on capturing nuanced technical discussions and behavioral examples, reliable speech recognition becomes essential infrastructure for building fair, defensible interview processes.
Freqeuently asked questions
How accurate does speech-to-text need to be for reliable interview scoring?
You need high accuracy for effective scoring because transcription errors can change technical terms or miss key competency indicators. AssemblyAI's Universal models achieve a mean Word Error Rate (WER) of 5.6% on English datasets, which translates to approximately 94.4% accuracy, ensuring your scores reflect actual candidate responses.
Can I use this system with video interview platforms like Zoom and Teams?
Yes, most video platforms let you download recordings as MP4 files, which AssemblyAI accepts directly. You can also extract just the audio track if you prefer working with audio files. The transcription process works the same regardless of whether you upload video or audio files.
How does automated transcript scoring compare to traditional manual evaluation during interviews?
Transcript-based scoring achieves much higher consistency between different evaluators because everyone reviews identical, complete information rather than relying on incomplete notes and fading memories. You also capture evidence that would be impossible to write down during fast-paced conversations.
What should I do if candidates refuse to consent to interview recording?
Offer traditional live scoring as an alternative while explaining that recording ensures fairer evaluation by allowing thorough review of their responses. Most candidates consent once they understand recordings are used solely for accurate assessment and aren't shared outside the hiring team.
How many competencies should I evaluate per interview to avoid overwhelming the scoring process?
Stick to 4-6 competencies maximum per interview. More than that becomes difficult to track effectively, and you risk diluting focus on the most important skills. Choose competencies that directly predict success in the specific role rather than using generic criteria.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Related posts